
Linux到精通2

Shell编程
这里说的Shell 脚本(shell script),是在Linux 环境下运行的脚本程序
Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 种类众多,常见的有:
- Bourne Shell(/usr/bin/sh或/bin/sh)
- Bourne Again Shell(/bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for Root(/sbin/sh)
- ……
Bash是大多数Linux 系统默认的 Shell,本文也仅关注Bash Shell。
在一般情况下,并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为 #!/bin/bash。
#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
入门
运行Shell脚本
编写shell脚本:
1 | vi test.sh |
#! 是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell。
echo 命令用于向窗口输出文本。
运行 Shell 脚本有两种方法:
1、作为可执行程序
1 | chmod +x ./test.sh #使脚本具有执行权限 |
默认情况下,一定要写成 ./test.sh,而不是 test.sh,运行其它二进制的程序也一样。
除非将当前目录.加入到PATH环境变量中,配置方法:
1 | sudo vi /etc/profile |
2、作为解释器参数
直接运行解释器,其参数就是 shell 脚本的文件名:
1 | /bin/sh test.sh |
这种方式运行的脚本,不需要在第一行指定解释器信息,写了也没用。
编写一个快捷创建shell脚本的命令
1 | #!/bin/bash |
将以上内容编写好之后保存为shell文件,然后执行
1 | chmod u+x shell |
echo命令
Shell 的 echo 指令与 PHP 的 echo 指令类似,都是用于字符串的输出。命令格式:
1 | echo string |
显示普通字符串:
1 | echo "It is a test" |
这里的双引号完全可以省略,以下命令与上面实例效果一致:
1 | echo It is a test |
显示转义字符:
1 | echo "\"It is a test\"" |
结果将是:
1 | "It is a test" |
同样,双引号也可以省略
read 命令从标准输入中读取一行,并把输入行的每个字段的值指定给 shell 变量
1 | #!/bin/sh |
以上代码保存为 test.sh,name 接收标准输入的变量,结果将是:
1 | [root@www ~]# sh test.sh |
显示换行
1 | echo -e "OK! \n" # -e 开启转义 |
输出结果:
1 | OK! |
显示不换行
1 | #!/bin/sh |
输出结果:
1 | OK! It is a test |
printf 命令
printf 命令的语法:
1 | printf format-string [arguments...] |
参数说明:
- format-string: 为格式控制字符串
- arguments: 为参数列表。
实例如下:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | 姓名 性别 体重kg |
- %s %c %d %f都是格式替代符
- %-10s 指一个宽度为10个字符(-表示左对齐,没有则表示右对齐),任何字符都会被显示在10个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
- %-4.2f 指格式化为小数,其中.2指保留2位小数。
printf的转义序列:
| 序列 | 说明 |
|---|---|
| \a | 警告字符,通常为ASCII的BEL字符 |
| \b | 后退 |
| \c | 抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略 |
| \f | 换页(formfeed) |
| \n | 换行 |
| \r | 回车(Carriage return) |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ | 一个字面上的反斜杠字符 |
| \ddd | 表示1到3位数八进制值的字符。仅在格式字符串中有效 |
| \0ddd | 表示1到3位的八进制值字符 |
例子:
1 | python@ubuntu:~/test$ printf "a string, no processing:<%s>\n" "A\nB" |
Shell 注释
以 # 开头的行就是注释,会被解释器忽略:
1 | #-------------------------------------------- |
多行注释还可以使用以下格式:
1 | :<<EOF |
EOF 也可以使用其他符号:
1 | :<<' |
Shell变量
定义变量
1 | your_name="taobao.com" |
变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
使用变量
在变量名前面加美元符号即可,如:
1 | your_name="qinjx" |
加花括号可以帮助解释器识别变量的边界,比如:
1 | for skill in Ada Coffe Action Java; do |
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
1 | python@ubuntu:~/shell$ myUrl="http://www.google.com" |
删除变量
使用 unset 命令可以删除变量,但不能删除只读变量:
1 | #!/bin/sh |
变量类型
运行shell时,会同时存在三种变量:
- 1) 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
- 2) 环境变量 所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
- 3) shell变量 shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
Shell 函数
shell中函数的定义格式如下:
1 | [ function ] funname [()] |
说明:
- 1、可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
- 2、参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255)
示例:
1 | #!/bin/bash |
输出,类似下面:
1 | 这个函数会对输入的两个数字进行相加运算... |
函数返回值在调用该函数后通过 $? 来获得。
注意:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数…
带参数的函数示例:
1 | #!/bin/bash |
输出结果:
1 | 第一个参数为 1 ! |
当n>=10时,需要使用${n}来获取参数。
另外,还有几个特殊字符用来处理参数:
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数 |
| $$ | 脚本运行的当前进程ID号 |
| $! | 后台运行的最后一个进程的ID号 |
| $@ | 与$*相同,但是使用时加引号,并在引号中返回每个参数。 |
| $- | 显示Shell使用的当前选项,与set命令功能相同。 |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
文件包含
Shell 文件包含的语法格式如下:
1 | . filename # 注意点号(.)和文件名中间有一空格 |
实例
创建两个 shell 脚本文件。
test1.sh 代码如下:
1 | #!/bin/bash |
test2.sh 代码如下:
1 | #!/bin/bash |
接下来,我们为 test2.sh 添加可执行权限并执行:
1 | $ chmod +x test2.sh |
**注:**被包含的文件 test1.sh 不需要可执行权限。
shell数据类型
字符串
字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号:
1 | str='this is a string' |
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号:
1 | your_name='taobao' |
输出结果为:
1 | Hello, I know you are "taobao"! |
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
拼接字符串:
1 | your_name="taobao" |
输出结果为:
1 | hello, taobao ! hello, taobao ! |
获取字符串长度
1 | string="abcd" |
截取字符串${s:n1:n2}
以下实例从字符串第 2 个字符开始截取 4 个字符:
1 | string="taobao is a great site" |
查找字符出现的位置expr index
查找字符 i 或 o 的位置(哪个字母先出现就计算哪个):
1 | string="taobao is a great site" |
注意: 以上脚本中 ` 是反引号,而不是单引号 **’**。
数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
数组元素的下标由 0 开始编号。
定义数组
在 Shell 中,用括号来表示数组,数组元素用”空格”符号分割开。定义数组的一般形式为:
1 | array_name=(value0 value1 value2 value3) |
或者
1 | array_name=( |
或单独定义数组的各个分量:
1 | array_name[0]=value0 |
可以不使用连续的下标,而且下标的范围没有限制。
读取数组
读取数组元素值的一般格式是:
1 | valuen=${array_name[n]} |
例子:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | $ chmod +x test.sh |
使用 @或* 符号可以获取数组中的所有元素,例如:
1 | echo ${array_name[@]} |
例子:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | $ chmod +x test.sh |
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
1 | # 取得数组元素的个数 |
例子:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | $ chmod +x test.sh |
Shell传递参数
执行 Shell 脚本时,向脚本传递参数,脚本内获取参数的格式为:**$n**。
n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推……
$0 为执行的文件名
test.sh文件内容如下:
1 | vi test.sh |
运行结果:
1 | python@ubuntu:~/test$ sh test.sh 1 2 3 |
参数获取:
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本的参数个数 |
$* |
传递的参数作为一个字符串显示 |
| $$ | 脚本运行的当前进程ID号 |
| $! | 后台运行的最后一个进程的ID号 |
$@ |
与$*相同,但是使用时加引号 |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | python@ubuntu:~/test$ ./test.sh 1 2 3 |
$*与$@的区别:
- 只有在双引号中体现出来。假设在脚本运行时写了三个参数 1、2、3,,则
$*等价于 “1 2 3”(传递了一个参数),而$@等价于 “1” “2” “3”(传递了三个参数)。
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | python@ubuntu:~/test$ sh test 1 2 3 |
Shell基本运算符
Shell 和其他编程语言一样,支持多种运算符,包括:
- 算数运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr,expr 最常用。
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | 两数之和为 : 4 |
两点注意:
- 表达式和运算符之间要有空格,例如 2+2 是不对的,必须写成 2 + 2。
- 完整的表达式要被 ` ` 包含,这个字符是反引号在 Esc 键下边。
算术运算符
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b 结果为 30。 |
| - | 减法 | expr $a - $b 结果为 -10。 |
| * | 乘法 | expr $a \* $b 结果为 200。 |
| / | 除法 | expr $b / $a 结果为 2。 |
| % | 取余 | expr $b % $a 结果为 0。 |
| = | 赋值 | a=$b 将把变量 b 的值赋给 a。 |
| == | 相等。用于比较两个数字,相同则返回 true。 | [ $a == $b ] 返回 false。 |
| != | 不相等。用于比较两个数字,不相同则返回 true。 | [ $a != $b ] 返回 true。 |
算术运算符实例如下:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | a + b : 30 |
注意:
- 乘号(*)前边必须加反斜杠
\才能实现乘法运算; - if…then…fi 是条件语句,后续将会讲解。
- 在 MAC 中 shell 的 expr 语法是:**$((表达式))**,此处表达式中的 “*” 不需要转义符号
\。
1 | let varName=算术表达式 |
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ]返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
关系运算符实例如下:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | 10 -eq 20: a 不等于 b |
布尔运算符
下表列出了常用的布尔运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
| -o | 或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a | 与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
布尔运算符实例如下:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | 10 != 20 : a 不等于 b |
逻辑运算符
以下介绍 Shell 的逻辑运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
逻辑运算符实例如下:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | 返回 false |
字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0,为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否为0,不为0返回 true。 | [ -n "$a" ] 返回 true。 |
| $ | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
字符串运算符实例如下:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | abc = efg: a 不等于 b |
文件测试运算符
文件测试运算符用于检测 Unix 文件的各种属性。
属性检测描述如下:
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件,如果是,则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件,如果是,则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -g file | 检测文件是否设置了 SGID 位,如果是,则返回 true。 | [ -g $file ] 返回 false。 |
| -k file | 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 | [ -k $file ] 返回 false。 |
| -p file | 检测文件是否是有名管道,如果是,则返回 true。 | [ -p $file ] 返回 false。 |
| -u file | 检测文件是否设置了 SUID 位,如果是,则返回 true。 | [ -u $file ] 返回 false。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。 |
其他检查符:
- -S: 判断某文件是否 socket。
- -L: 检测文件是否存在并且是一个符号链接。
变量 file 表示文件 /var/www/runoob/test.sh,它的大小为 100 字节,具有 rwx 权限。下面的代码,将检测该文件的各种属性:
1 | #!/bin/bash |
执行脚本,输出结果如下所示:
1 | 文件可读 |
test命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
数值测试
| 参数 | 说明 |
|---|---|
| -eq | 等于则为真 |
| -ne | 不等于则为真 |
| -gt | 大于则为真 |
| -ge | 大于等于则为真 |
| -lt | 小于则为真 |
| -le | 小于等于则为真 |
实例演示:
1 | num1=100 |
输出结果:
1 | 两个数相等! |
代码中的 [] 执行基本的算数运算,如:
1 | #!/bin/bash |
结果为:
1 | result 为: 11 |
字符串测试
| 参数 | 说明 |
|---|---|
| = | 等于则为真 |
| != | 不相等则为真 |
| -z 字符串 | 字符串的长度为零则为真 |
| -n 字符串 | 字符串的长度不为零则为真 |
实例演示:
1 | num1="ru1noob" |
输出结果:
1 | 两个字符串不相等! |
文件测试
| 参数 | 说明 |
|---|---|
| -e 文件名 | 如果文件存在则为真 |
| -r 文件名 | 如果文件存在且可读则为真 |
| -w 文件名 | 如果文件存在且可写则为真 |
| -x 文件名 | 如果文件存在且可执行则为真 |
| -s 文件名 | 如果文件存在且至少有一个字符则为真 |
| -d 文件名 | 如果文件存在且为目录则为真 |
| -f 文件名 | 如果文件存在且为普通文件则为真 |
| -c 文件名 | 如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 | 如果文件存在且为块特殊文件则为真 |
实例演示:
1 | cd /bin |
输出结果:
1 | 文件已存在! |
另外,Shell还提供了与( -a )、或( -o )、非( ! )三个逻辑操作符用于将测试条件连接起来,其优先级为:”!“最高,”-a”次之,”-o”最低。例如:
1 | cd /bin |
输出结果:
1 | 至少有一个文件存在! |
Shell 流程控制
if else判断语句
if 语句语法格式:
1 | if condition |
写成一行(适用于终端命令提示符):
1 | if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi |
if else 语法格式:
1 | if condition |
if else-if else 语法格式:
1 | if condition1 |
以下实例判断两个变量是否相等:
1 | a=10 |
输出结果:
1 | a 小于 b |
if else语句经常与test命令结合使用,如下所示:
1 | num1=$[2*3] |
输出结果:
1 | 两个数字相等! |
for循环
for循环一般格式为:
1 | for var in item1 item2 ... itemN |
写成一行:
1 | for var in item1 item2 ... itemN; do command1; command2… done; |
例如,顺序输出当前列表中的数字:
1 | for loop in 1 2 3 4 5 |
输出结果:
1 | The value is: 1 |
顺序输出字符串中的字符:
1 | for str in 'This is a string' |
输出结果:
1 | This is a string |
while循环
while循环格式为:
1 | while condition |
示例:
1 | #!/bin/bash |
运行脚本,输出:
1 | 1 |
while循环可用于读取键盘信息。下面的例子中,输入信息被设置为变量FILM,按Ctrl-D结束循环。
1 | echo '按下 <CTRL-D> 退出' |
运行脚本,输出类似下面:
1 | 按下 <CTRL-D> 退出 |
无限循环
无限循环语法格式:
1 | while : |
或者
1 | while true |
或者
1 | for (( ; ; )) |
until 循环
until 循环执行一系列命令直至条件为 true 时停止。
until 循环与 while 循环在处理方式上刚好相反。
一般 while 循环优于 until 循环,但在某些时候—也只是极少数情况下,until 循环更加有用。
until 语法格式:
1 | until condition |
condition 一般为条件表达式,如果返回值为 false,则继续执行循环体内的语句,否则跳出循环。
以下实例我们使用 until 命令来输出 0 ~ 9 的数字:
1 | #!/bin/bash |
运行结果:
输出结果为:
1 | 0 |
case
Shell case语句为多选择语句。可以用case语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。case语句格式如下:
1 | case 值 in |
下面的脚本提示输入1到4,与每一种模式进行匹配:
1 | echo '输入 1 到 4 之间的数字:' |
输入不同的内容,会有不同的结果,例如:
1 | 输入 1 到 4 之间的数字: |
跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell使用两个命令来实现该功能:break和continue。
break命令允许跳出所有循环(终止执行后面的所有循环)。
下面的例子中,脚本进入死循环直至用户输入数字大于5。要跳出这个循环,返回到shell提示符下,需要使用break命令。
1 | #!/bin/bash |
执行以上代码,输出结果为:
1 | 输入 1 到 5 之间的数字:3 |
continue命令与break命令类似,只有一点差别,它不会跳出所有循环,仅仅跳出当前循环。
Shell输入/输出重定向
重定向命令列表如下:
| 命令 | 说明 |
|---|---|
| command > file | 将输出重定向到 file。 |
| command < file | 将输入重定向到 file。 |
| command >> file | 将输出以追加的方式重定向到 file。 |
| n > file | 将文件描述符为 n 的文件重定向到 file。 |
| n >> file | 将文件描述符为 n 的文件以追加的方式重定向到 file。 |
| n >& m | 将输出文件 m 和 n 合并。 |
| n <& m | 将输入文件 m 和 n 合并。 |
| << tag | 将开始标记 tag 和结束标记 tag 之间的内容作为输入。 |
需要注意的是文件描述符 0 通常是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。
输出重定向
重定向一般通过在命令间插入特定的符号来实现。特别的,这些符号的语法如下所示:
1 | command1 > file1 |
上面这个命令执行command1然后将输出的内容存入file1。
注意任何file1内的已经存在的内容将被新内容替代。如果要将新内容添加在文件末尾,请使用>>操作符。
输出重定向会覆盖文件内容:
1 | $ echo "www.baidu.com" > users |
如果不希望文件内容被覆盖,可以使用 >> 追加到文件末尾,例如:
1 | $ echo "www.baidu.com" >> users |
输入重定向
和输出重定向一样,Unix 命令也可以从文件获取输入,语法为:
1 | command1 < file1 |
这样,本来需要从键盘获取输入的命令会转移到文件读取内容。
注意:输出重定向是大于号(>),输入重定向是小于号(<)。
统计 users 文件的行数,执行以下命令:
1 | python@ubuntu:~/test$ wc -l test |
也可以将输入重定向到 users 文件:
1 | python@ubuntu:~/test$ wc -l <test |
注意:上面两个例子的结果不同:第一个例子,会输出文件名;第二个不会,因为它仅仅知道从标准输入读取内容。
同时替换输入和输出,执行command1,从文件infile读取内容,然后将输出写入到outfile中:
1 | command1 < infile > outfile |
重定向深入讲解
一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件:
- 标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
- 标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。
- 标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
默认情况下,command > file 将 stdout 重定向到 file,command < file 将stdin 重定向到 file。
如果希望 stderr 重定向到 file,可以这样写:
1 | $ command 2 > file |
如果希望 stderr 追加到 file 文件末尾,可以这样写:
1 | $ command 2 >> file |
2 表示标准错误文件(stderr)。
如果希望将 stdout 和 stderr 合并后重定向到 file,可以这样写:
1 | $ command > file 2>&1 |
如果希望对 stdin 和 stdout 都重定向,可以这样写:
1 | $ command < file1 >file2 |
command 命令将 stdin 重定向到 file1,将 stdout 重定向到 file2。
Here Document
Here Document 是 Shell 中的一种特殊的重定向方式,用来将输入重定向到一个交互式 Shell 脚本或程序。
它的基本的形式如下:
1 | command << delimiter |
它的作用是将两个 delimiter 之间的内容(document) 作为输入传递给 command。
注意:结尾的delimiter 一定要顶格写,前面不能有任何字符,后面也不能有任何字符,包括空格和 tab 缩进。
在命令行中通过 wc -l 命令计算 Here Document 的行数:
1 | $ wc -l << EOF |
/dev/null 文件
如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null:
1 | $ command > /dev/null |
/dev/null 是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是 /dev/null 文件非常有用,将命令的输出重定向到它,会起到”禁止输出”的效果。
如果希望屏蔽 stdout 和 stderr,可以这样写:
1 | $ command > /dev/null 2>&1 |
0 是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。
实例
杨辉三角:
1 | #!/bin/bash |
sum()&max():
1 | #!/bin/bash |
99乘法表:
1 | #!/bin/bash |
文本编辑命令
cut命令
1 | 选项与参数: |
cut以行为单位,根据分隔符把行分成若干列,这样就可以指定选取哪些列了。
1 | cut -d '分隔字符' -f 选取的列数 |
只显示/etc/passwd的用户和shell:
1 | #cat /etc/passwd | cut -d ':' -f 1,7 |
sed命令
sed 可依照脚本的指令来处理、编辑文本文件。
Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法:
1 | sed [-e<script>][-f<script文件>][文本文件] |
参数说明:
-e <script>以指定的script来处理输入的文本文件。-f<script文件>以指定的script文件来处理输入的文本文件。-n仅显示script处理后的结果,一般跟p动作搭配使用。-i使用处理后的结果修改文件。
动作说明:
- a:在指定行后面插入内容
- i:在指定行前面插入内容
- d:删除指定行
- c :替换指定行
- p :打印指定行的数据,通常需要跟
-n选项搭配使用 - s :替换指定字符,兼容vim的替换语法,例如 1,20s/old/new/g
元字符集
sed支持一般的正则表达式,下面是支持的正则语法:^行的开始 如:/^sed/匹配所有以sed开头的行。$行的结束 如:/sed$/匹配所有以sed结尾的行。.匹配一个非换行符的任意字符 如:/s.d/匹配s后接一个任意字符,然后是d。*匹配零或多个字符 如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。[]匹配一个指定范围内的字符,如/[Ss]ed/匹配sed和Sed。[^]匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。\(..\)保存匹配的字符,如s/(love)able/\1rs,loveable被替换成lovers。&保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。\<单词的开始,如:/<love/匹配包含以love开头的单词的行。\>单词的结束,如/love>/匹配包含以love结尾的单词的行。x\+重复字符x,至少1次,如:/o\+/匹配至少有1个o的行。x\{m\}重复字符x,m次,如:/o\{5\}/匹配包含5个o的行。x\{m,\}重复字符x,至少m次,如:/o\{5,\}/匹配至少有5个o的行。x\{m,n\}重复字符x,至少m次,不多于n次,如:/o\{5,10\}/匹配5-10个o的行。
a|i:在指定行位置添加行
1 | python@xxx:~/test$ cat testfile |
默认情况下-e参数可以省略:
1 | python@xxx:~/test$ cat testfile|sed '2a\newline' |
<script>中的内容最好用单引号括起来,如果脚本内容不存在空白字符也可以省略单引号。
在第二行之前添加一行:
1 | python@xxx:~/test$ sed '2i newline' testfile |
最后一行加入 # This is a test:
1 | python@xxx:~/test$ sed '$a # This is a test' testfile |
同时添加多行:
1 | python@xxx:~/test$ cat testfile|sed '2a\newline1\ |
d:删除指定行
将 /etc/passwd 的内容列出行号,并将第 2~5 行删除!
1 | [root@www ~]# nl /etc/passwd | sed '2,5d' |
只删除第2行:
1 | nl /etc/passwd | sed '2d' |
删除第3到最后一行:
1 | nl /etc/passwd | sed '3,$d' |
删除/etc/passwd所有包含/usr/sbin/nologin的行,其他行输出:
1 | python@xxx:~/test$ nl /etc/passwd | sed '/\/usr\/sbin\/nologin/d' |
c:替换指定行
将第2-5行的内容替换成为『No 2-5 number』:
1 | python@xxx:~/test$ nl /etc/passwd | sed '2,5c No 2-5 number' |
p:仅显示指定行
不加-n选项时,除了输出匹配行,还同时会输出所有行,所以需要加-n选项。
仅列出 /etc/passwd 文件内的第 5-7 行:
1 | python@xxx:~/test$ nl /etc/passwd | sed -n '5,7p' |
搜索 /etc/passwd有root关键字的行:
1 | python@xxx:~/test$ cat /etc/passwd | sed -n '/root/p' |
打印/etc/passwd有以root和bin开头之间的行:
1 | python@xxx:~/test$ cat /etc/passwd | sed -n '/^root/,/^bin/p' |
打印从第五行开始到第一个包含以/var/mail开始的行之间的所有行:
1 | python@xxx:~/test$ nl /etc/passwd | sed -n '5,\/var\/mail/p' |
s:字符串替换
语法:
1 | sed 's/要被取代的字串/新的字串/g' |
不论什么字符,紧跟着s命令的都被认为是新的分隔符.
sed 's#10#100#g'表示把所有10替换成100,“#”在这里是分隔符,代替了默认的“/”分隔符。
提取本机所有的ip地址:
1 | [root@VM_0_9_centos ~]# ifconfig | grep 'inet ' |
对于以root和bin开头之间的行,每行的末尾添加sed test:
1 | python@xxx:~/test$ cat /etc/passwd | sed '/^root/,/^bin/s/$/--sed test/' |
y:单字符替换
跟s一样也用于替换,不过s替换的是整体,y替换的是每一字母对应的单个字母
把data中的第一行至第三行中的a替换成A,b替换成B,c替换成C:
1 | sed '1,3y/abc/ABC/' data |
示例:
1 | python@ubuntu:~/test$ echo "123" | sed 'y/13/34/' |
hHgG模式空间&保持空间
h命令是将当前模式空间中内容覆盖至保持空间,H命令是将当前模式空间中的内容追加至保持空间
g命令是将当前保持空间中内容覆盖至模式空间,G命令是将当前保持空间中的内容追加至模式空间
模拟tac命令:
1 | python@ubuntu:~/test$ cat log.txt |
1!G第1行不 执行“G”命令,从第2行开始执行。
$!d,最后一行不删除(保留最后1行)
下图P表示模式空间,H代表保持空间:
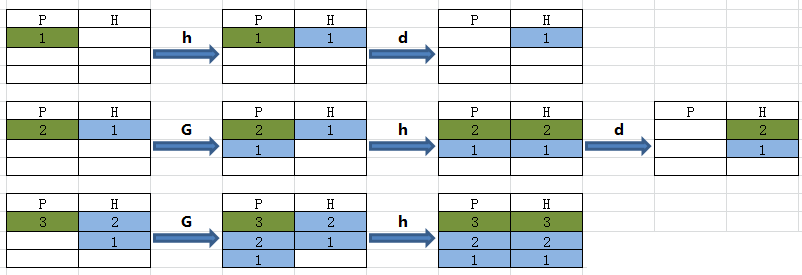
递增序列:
1 | python@ubuntu:~/test$ seq 3 |
多次指定-e选项进行多点编辑
删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell:
1 | nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/' |
删除一个文件以#开头的行和空行:
1 | python@xxx:~/test$ nl abc -ba |
也可以通过;实现
1 | python@ubuntu:~/test$ nl /etc/passwd | sed '3,$d;s/bash/blueshell/' |
选项-i直接修改文件内容
默认情况下sed命令仅仅只是将处理结果显示在控制台,加-i选项则会修改文件内容。
将 regular_express.txt 内每一行结尾若为 . 则换成 !
1 | [root@www ~]# cat regular_express.txt |
awk命令
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法:
1 | awk [选项参数] 'script' var=value file(s) |
选项参数说明:
- -F fs or –field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 - -v var=value or –asign var=value
赋值一个用户定义变量。 - -f scripfile or –file scriptfile
从脚本文件中读取awk命令。
基本用法
1 | awk '{[pattern] action}' file |
每行按空格或TAB分割,输出文本中的1、4列:
1 | python@ubuntu:~/test$ cat log.txt |
格式化输出:
1 | python@ubuntu:~/test$ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt |
-F指定分割字符
1 | awk -F #-F相当于内置变量FS, 指定分割字符 |
使用:分割,取/etc/passwd文件每个用户对应shell:
1 | python@ubuntu:~/test$ awk -F: '{print $1,$7}' /etc/passwd |
同时使用:和/l两个分隔符分割/etc/passwd文件
1 | python@ubuntu:~/test$ awk -F '[:\/]' '{print $1,$7}' /etc/passwd |
-v设置变量
1 | awk -v # 设置变量 |
例子:
1 | python@ubuntu:~/test$ cat log.txt |
-f指定awk脚本
1 | awk -f {awk脚本} {文件名} |
脚本模块:
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
1 | $ cat score.txt |
awk脚本如下:
1 | $ cat cal.awk |
我们来看一下执行结果:
1 | $ awk -f cal.awk score.txt |
AWK工作原理
AWK 工作流程可分为三个部分:
- 读输入文件之前执行的代码段(由BEGIN关键字标识)。
- 主循环执行输入文件的代码段。
- 读输入文件之后的代码段(由END关键字标识)。
命令结构:
1 | awk 'BEGIN{ commands } pattern{ commands } END{ commands }' |
下面的流程图描述出了 AWK 的工作流程:
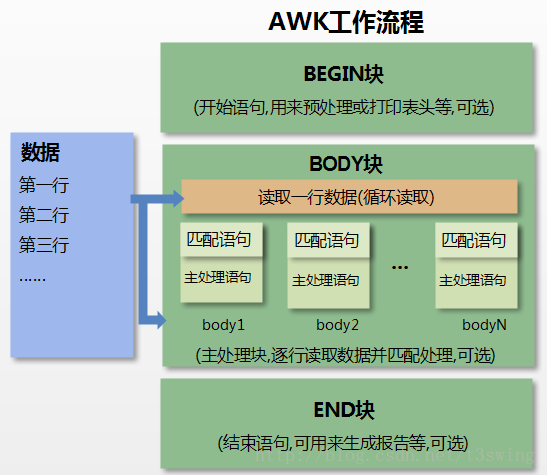
- 1、通过关键字 BEGIN 执行 BEGIN 块的内容,即 BEGIN 后花括号 {} 的内容。
- 2、完成 BEGIN 块的执行,开始执行body块。
- 3、读入有 \n 换行符分割的记录。
- 4、将记录按指定的域分隔符划分域,填充域,**$0** 则表示所有域(即一行内容), 1 ∗ ∗ 表 示 第 一 个 域 , ∗ ∗ 1** 表示第一个域,** 1∗∗表示第一个域,∗∗n 表示第 n 个域。
- 5、依次执行各 BODY 块,pattern 部分匹配该行内容成功后,才会执行 awk-commands 的内容。
- 6、循环读取并执行各行直到文件结束,完成body块执行。
- 7、开始 END 块执行,END 块可以输出最终结果。
运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| && | 逻辑与 |
| ~ 和 !~ | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / % | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ – | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
过滤第一列大于2的行
1 | $ awk '$1>2' log.txt #命令 |
过滤第一列等于2的行
1 | $ awk '$1==2 {print $1,$3}' log.txt #命令 |
过滤第一列大于2并且第二列等于’Are’的行
1 | $ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #命令 |
内建变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
格式化变量说明:
- %s 输出字符串
- %i 输出整数
- %f 输出浮点数
%-5s 格式为左对齐且宽度为5的字符串代替(-表示左对齐),不使用则是又对齐。
%-4.2f 格式为左对齐宽度为4,保留两位小数。
1 | python@ubuntu:~/test$ awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt |
输出顺序号 NR, 匹配文本行号
1 | python@ubuntu:~/test$ awk '{print NR,FNR,$1,$2,$3}' log.txt |
指定输出分割符
1 | python@ubuntu:~/test$ cat log.txt |
忽略大小写
1 | $ awk 'BEGIN{IGNORECASE=1} /this/' log.txt |
正则字符串匹配
~ 表示模式开始。// 中是模式。
输出第二列包含 “th”,并打印第二列与第四列:
1 | python@ubuntu:~/test$ awk '$2 ~ /th/ {print $2,$4}' log.txt |
输出包含”re”的行:
1 | python@ubuntu:~/test$ awk '/re/' log.txt |
!表示取反
输出第二列不包含 “th”,并打印第二列与第四列:
1 | python@ubuntu:~/test$ awk '$2 !~ /th/ {print $2,$4}' log.txt |
输出不包含”re”的行:
1 | python@ubuntu:~/test$ awk '!/re/' log.txt |
一些实例
计算文件大小
1 | $ ls -l *.txt | awk '{sum+=$6} END {print sum}' |
从文件中找出长度大于80的行
1 | awk 'length>80' log.txt |
打印九九乘法表
1 | seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}' |
访问日志分析
日志格式
1 | python@ubuntu:~/test$ head access.log -n1 |
示例:
1 | 1.数据清洗 |
awk编程
条件语句IF&ELSE
IF 条件语句语法格式如下:
1 | if (condition) |
也可以使用花括号来执行一组操作:
1 | if (condition) |
判断数字是奇数还是偶数:
1 | python@ubuntu:~/test$ awk 'BEGIN {num = 10; if (num % 2 == 0) printf "%d 是偶数\n", num }' |
IF - ELSE 条件语句语法格式如下:
1 | if (condition) |
在条件语句 condition 为 true 时只需 action-1,否则执行 action-2。
1 | python@ubuntu:~/test$ awk 'BEGIN { |
可以创建多个 IF - ELSE 格式的判断语句来实现多个条件的判断:
1 | $ awk 'BEGIN { |
输出结果:
1 | python@ubuntu:~/test$ awk 'BEGIN { |
循环语句For&While
For 循环的语法如下:
1 | for (initialisation; condition; increment/decrement) |
下面的例子使用 For 循环输出数字 1 至 5:
1 | python@ubuntu:~/test$ awk 'BEGIN { for (i = 1; i <= 5; ++i) print i }' |
While 循环的语法如下:
1 | while (condition) |
下面是使用 While 循环输出数字 1 到 5 的例子:
1 | python@ubuntu:~/test$ awk 'BEGIN {i = 1; while (i < 6) { print i; ++i } }' |
在下面的示例子中,当计算的和大于 50 的时候使用 break 结束循环:
1 | $ awk 'BEGIN { |
输出结果为:
1 | python@ubuntu:~/test$ awk 'BEGIN { |
Continue 语句用于在循环体内部结束本次循环,从而直接进入下一次循环迭代。
下面的例子输出 1 到 20 之间的偶数:
1 | python@ubuntu:~/test$ awk 'BEGIN {for (i = 1; i <= 20; ++i) {if (i % 2 == 0) print i ; else continue} }' |
Exit 用于结束脚本程序的执行。
该函数接受一个整数作为参数表示 AWK 进程结束状态。 如果没有提供该参数,其默认状态为 0。
下面例子中当和大于 50 时结束 AWK 程序。
1 | $ awk 'BEGIN { |
输出结果为:
1 | python@ubuntu:~/test$ awk 'BEGIN { |
awk数组
AWK的数组底层数据结构是散列表,索引可以是数字或字符串。
数组使用的语法格式:
1 | array_name[index]=value |
创建数组并访问数组元素:
1 | $ awk 'BEGIN { |
删除数组元素语法格式:
1 | delete array_name[index] |
下面的例子中,数组中的 google 元素被删除(删除命令没有输出):
1 | $ awk 'BEGIN { |
AWK 本身不支持多维数组,不过我们可以很容易地使用一维数组模拟实现多维数组。
如下示例为一个 3x3 的三维数组:
1 | 100 200 300 |
以上实例中,array[0][0] 存储 100,array[0][1] 存储 200 ,依次类推。为了在 array[0][0] 处存储 100, 可以使用字符串0,0 作为索引: array[“0,0”] = 100。
下面是模拟二维数组的例子:
1 | $ awk 'BEGIN { |
执行上面的命令可以得到如下结果:
1 | array[0,0] = 100 |
在数组上可以执行很多操作,比如,使用 asort 完成数组元素的排序,或者使用 asorti 实现数组索引的排序等等。
AWK 用户自定义函数
自定义函数的语法格式为:
1 | function function_name(argument1, argument2, ...) |
以下实例实现了两个简单函数,它们分别返回两个数值中的最小值和最大值。
文件 functions.awk 代码如下:
1 | # 返回最小值 |
执行 functions.awk 文件,可以得到如下的结果:
1 | $ awk -f functions.awk |
AWK 内置函数
AWK 内置函数主要有以下几种:
- 算数函数
- 字符串函数
- 时间函数
- 位操作函数
- 其它函数
算数函数
| 函数名 | 说明 | 实例 |
|---|---|---|
| atan2( y, x ) | 返回 y/x 的反正切。 | $ awk 'BEGIN { PI = 3.14159265 x = -10 y = 10 result = atan2 (y,x) * 180 / PI; printf "The arc tangent for (x=%f, y=%f) is %f degrees\n", x, y, result }'输出结果为:The arc tangent for (x=-10.000000, y=10.000000) is 135.000000 degrees |
| cos( x ) | 返回 x 的余弦;x 是弧度。 | $ awk 'BEGIN { PI = 3.14159265 param = 60 result = cos(param * PI / 180.0); printf "The cosine of %f degrees is %f.\n", param, result }'输出结果为:The cosine of 60.000000 degrees is 0.500000. |
| sin( x ) | 返回 x 的正弦;x 是弧度。 | $ awk 'BEGIN { PI = 3.14159265 param = 30.0 result = sin(param * PI /180) printf "The sine of %f degrees is %f.\n", param, result }'输出结果为:The sine of 30.000000 degrees is 0.500000. |
| exp( x ) | 返回 x 幂函数。 | $ awk 'BEGIN { param = 5 result = exp(param); printf "The exponential value of %f is %f.\n", param, result }'输出结果为:The exponential value of 5.000000 is 148.413159. |
| log( x ) | 返回 x 的自然对数。 | $ awk 'BEGIN { param = 5.5 result = log (param) printf "log(%f) = %f\n", param, result }'输出结果为:log(5.500000) = 1.704748 |
| sqrt( x ) | 返回 x 平方根。 | $ awk 'BEGIN { param = 1024.0 result = sqrt(param) printf "sqrt(%f) = %f\n", param, result }'输出结果为:sqrt(1024.000000) = 32.000000 |
| int( x ) | 返回 x 的截断至整数的值。 | $ awk 'BEGIN { param = 5. result = int(param) print "Truncated value =", result }'输出结果为:Truncated value = 5 |
| rand( ) | 返回任意数字 n,其中 0 <= n < 1。 | $ awk 'BEGIN { print "Random num1 =" , rand() print "Random num2 =" , rand() print "Random num3 =" , rand() }'输出结果为:Random num1 = 0.237788 Random num2 = 0.291066 Random num3 = 0.845814 |
| srand( [Expr] ) | 将 rand 函数的种子值设置为 Expr 参数的值,或如果省略 Expr 参数则使用某天的时间。返回先前的种子值。 | $ awk 'BEGIN { param = 10 printf "srand() = %d\n", srand() printf "srand(%d) = %d\n", param, srand(param) }'输出结果为:srand() = 1 srand(10) = 1417959587 |
字符串函数
| 函数 | 说明 | 实例 |
|---|---|---|
| gsub( Ere, Repl, [ In ] ) | gsub 是全局替换( global substitution )的缩写。除了正则表达式所有具体值被替代这点,它和 sub 函数完全一样地执行。 | $ awk 'BEGIN { str = "Hello, World" print "String before replacement = " str gsub("World", "Jerry", str) print "String after replacement = " str }'输出结果为:String before replacement = Hello, World String after replacement = Hello, Jerry |
| sub(regex,sub,string) | sub 函数执行一次子串替换。它将第一次出现的子串用 regex 替换。第三个参数是可选的,默认为 $0。 | $ awk 'BEGIN { str = "Hello, World" print "String before replacement = " str sub("World", "Jerry", str) print "String after replacement = " str }'输出结果为:String before replacement = Hello, World String after replacement = Hello, Jerry |
| substr(str, start, l) | substr 函数返回 str 字符串中从第 start 个字符开始长度为 l 的子串。如果没有指定 l 的值,返回 str 从第 start 个字符开始的后缀子串。 | $ awk 'BEGIN { str = "Hello, World !!!" subs = substr(str, 1, 5) print "Substring = " subs }'输出结果为:Substring = Hello |
| index( String1, String2 ) | 在由 String1 参数指定的字符串(其中有出现 String2 指定的参数)中,返回位置,从 1 开始编号。如果 String2 参数不在 String1 参数中出现,则返回 0(零)。 | $ awk 'BEGIN { str = "One Two Three" subs = "Two" ret = index(str, subs) printf "Substring \"%s\" found at %d location.\n", subs, ret }'输出结果为:Substring "Two" found at 5 location. |
| length [(String)] | 返回 String 参数指定的字符串的长度(字符形式)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。 | $ awk 'BEGIN { str = "Hello, World !!!" print "Length = ", length(str) }'输出结果为:Substring "Two" found at 5 location. |
| blength [(String)] | 返回 String 参数指定的字符串的长度(以字节为单位)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。 | |
| substr( String, M, [ N ] ) | 返回具有 N 参数指定的字符数量子串。子串从 String 参数指定的字符串取得,其字符以 M 参数指定的位置开始。M 参数指定为将 String 参数中的第一个字符作为编号 1。如果未指定 N 参数,则子串的长度将是 M 参数指定的位置到 String 参数的末尾 的长度。 | $ awk 'BEGIN { str = "Hello, World !!!" subs = substr(str, 1, 5) print "Substring = " subs }'输出结果为:Substring = Hello |
| match( String, Ere ) | 在 String 参数指定的字符串(Ere 参数指定的扩展正则表达式出现在其中)中返回位置(字符形式),从 1 开始编号,或如果 Ere 参数不出现,则返回 0(零)。RSTART 特殊变量设置为返回值。RLENGTH 特殊变量设置为匹配的字符串的长度,或如果未找到任何匹配,则设置为 -1(负一)。 | $ awk 'BEGIN { str = "One Two Three" subs = "Two" ret = match(str, subs) printf "Substring \"%s\" found at %d location.\n", subs, ret }'输出结果为:Substring "Two" found at 5 location. |
| split( String, A, [Ere] ) | 将 String 参数指定的参数分割为数组元素 A[1], A[2], . . ., A[n],并返回 n 变量的值。此分隔可以通过 Ere 参数指定的扩展正则表达式进行,或用当前字段分隔符(FS 特殊变量)来进行(如果没有给出 Ere 参数)。除非上下文指明特定的元素还应具有一个数字值,否则 A 数组中的元素用字符串值来创建。 | $ awk 'BEGIN { str = "One,Two,Three,Four" split(str, arr, ",") print "Array contains following values" for (i in arr) { print arr[i] } }'输出结果为:Array contains following values One Two Three Four |
| tolower( String ) | 返回 String 参数指定的字符串,字符串中每个大写字符将更改为小写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 | $ awk 'BEGIN { str = "HELLO, WORLD !!!" print "Lowercase string = " tolower(str) }'输出结果为:Lowercase string = hello, world !!! |
| toupper( String ) | 返回 String 参数指定的字符串,字符串中每个小写字符将更改为大写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 | $ awk 'BEGIN { str = "hello, world !!!" print "Uppercase string = " toupper(str) }'输出结果为:Uppercase string = HELLO, WORLD !!! |
| sprintf(Format, Expr, Expr, . . . ) | 根据 Format 参数指定的 printf 子例程格式字符串来格式化 Expr 参数指定的表达式并返回最后生成的字符串。 | $ awk 'BEGIN { str = sprintf("%s", "Hello, World !!!") print str }'输出结果为:Hello, World !!! |
| strtonum(str) | strtonum 将字符串 str 转换为数值。 如果字符串以 0 开始,则将其当作十进制数;如果字符串以 0x 或 0X 开始,则将其当作十六进制数;否则,将其当作浮点数。 | $ awk 'BEGIN { print "Decimal num = " strtonum("123") print "Octal num = " strtonum("0123") print "Hexadecimal num = " strtonum("0x123") }'输出结果为:Decimal num = 123 Octal num = 83 Hexadecimal num = 291 |
**注:**Ere 部分可以是正则表达式。
1、gsub、sub 使用
1 | $ awk 'BEGIN{info="this is a test2012test!";gsub(/[0-9]+/,"||",info);print info}' |
2、查找字符串(index 使用)
使用了三元运算符: 表达式 ? 动作1 : 动作2
1 | $ awk 'BEGIN{info="this is a test2012test!";print index(info,"11111")?"ok":"no found";}' |
3、正则表达式匹配查找(match 使用)
1 | $ awk 'BEGIN{info="this is a test2012test!";print match(info,/[0-9]+/)?"ok":"no found";}' |
4、截取字符串(substr使用)
从第 4 个 字符开始,截取 10 个长度字符串。
1 | $ awk 'BEGIN{info="this is a test2012test!";print substr(info,4,10);}' |
5、字符串分割(split使用)
1 | $ awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}' |
分割 info,将 info 字符串使用空格切分为动态数组 tA。注意 awk for …in 循环,是一个无序的循环。 并不是从数组下标 1…n ,因此使用时候需要特别注意。
时间函数
| 函数名 | 说明 | 实例 |
|---|---|---|
| mktime( YYYY MM DD HH MM SS[ DST]) | 生成时间格式 | $ awk 'BEGIN { print "Number of seconds since the Epoch = " mktime("2014 12 14 30 20 10") }'输出结果为:Number of seconds since the Epoch = 1418604610 |
| strftime([format [, timestamp]]) | 格式化时间输出,将时间戳转为时间字符串 具体格式,见下表. | $ awk 'BEGIN { print strftime("Time = %m/%d/%Y %H:%M:%S", systime()) }'输出结果为:Time = 12/14/2014 22:08:42 |
| systime() | 得到时间戳,返回从1970年1月1日开始到当前时间(不计闰年)的整秒数 | awk 'BEGIN{now=systime();print now}'输出结果为:1343210982 |
strftime 日期和时间格式说明符:
| 序号 | 描述 |
|---|---|
| %a | 星期缩写(Mon-Sun)。 |
| %A | 星期全称(Monday-Sunday)。 |
| %b | 月份缩写(Jan)。 |
| %B | 月份全称(January)。 |
| %c | 本地日期与时间。 |
| %C | 年份中的世纪部分,其值为年份整除100。 |
| %d | 十进制日期(01-31) |
| %D | 等价于 %m/%d/%y. |
| %e | 日期,如果只有一位数字则用空格补齐 |
| %F | 等价于 %Y-%m-%d,这也是 ISO 8601 标准日期格式。 |
| %g | ISO8610 标准周所在的年份模除 100(00-99)。比如,1993 年 1 月 1 日属于 1992 年的第 53 周。所以,虽然它是 1993 年第 1 天,但是其 ISO8601 标准周所在年份却是 1992。同样,尽管 1973 年 12 月 31 日属于 1973 年但是它却属于 1994 年的第一周。所以 1973 年 12 月 31 日的 ISO8610 标准周所在的年是 1974 而不是 1973。 |
| %G | ISO 标准周所在年份的全称。 |
| %h | 等价于 %b. |
| %H | 用十进制表示的 24 小时格式的小时(00-23) |
| %I | 用十进制表示的 12 小时格式的小时(00-12) |
| %j | 一年中的第几天(001-366) |
| %m | 月份(01-12) |
| %M | 分钟数(00-59) |
| %n | 换行符 (ASCII LF) |
| %p | 十二进制表示法(AM/PM) |
| %r | 十二进制表示法的时间(等价于 %I:%M:%S %p)。 |
| %R | 等价于 %H:%M。 |
| %S | 时间的秒数值(00-60) |
| %t | 制表符 (tab) |
| %T | 等价于 %H:%M:%S。 |
| %u | 以数字表示的星期(1-7),1 表示星期一。 |
| %U | 一年中的第几个星期(第一个星期天作为第一周的开始),00-53 |
| %V | 一年中的第几个星期(第一个星期一作为第一周的开始),01-53。 |
| %w | 以数字表示的星期(0-6),0表示星期日 。 |
| %W | 十进制表示的一年中的第几个星期(第一个星期一作为第一周的开始),00-53。 |
| %x | 本地日期表示 |
| %X | 本地时间表示 |
| %y | 年份模除 100。 |
| %Y | 十进制表示的完整年份。 |
| %z | 时区,表示格式为+HHMM(例如,格式要求生成的 RFC 822或者 RFC 1036 时间头) |
| %Z | 时区名称或缩写,如果时区待定则无输出。 |
位操作函数
| 函数名 | 说明 | 实例 |
|---|---|---|
| and | 位与操作。 | $ awk 'BEGIN { num1 = 10 num2 = 6 printf "(%d AND %d) = %d\n", num1, num2, and(num1, num2) }'输出结果为:(10 AND 6) = 2 |
| compl | 按位求补。 | $ awk 'BEGIN { num1 = 10 printf "compl(%d) = %d\n", num1, compl(num1) }'输出结果为:compl(10) = 9007199254740981 |
| lshift | 左移位操作 | $ awk 'BEGIN { num1 = 10 printf "lshift(%d) by 1 = %d\n", num1, lshift(num1, 1) }'输出结果为:lshift(10) by 1 = 20 |
| rshift | 右移位操作 | $ awk 'BEGIN { num1 = 10 printf "rshift(%d) by 1 = %d\n", num1, rshift(num1, 1) }'输出结果为:rshift(10) by 1 = 5 |
| or | 按位或操作 | $ awk 'BEGIN { num1 = 10 num2 = 6 printf "(%d OR %d) = %d\n", num1, num2, or(num1, num2) }'输出结果为:(10 OR 6) = 14 |
| xor | 按位异或操作 | $ awk 'BEGIN { num1 = 10 num2 = 6 printf "(%d XOR %d) = %d\n", num1, num2, xor(num1, num2) }'输出结果为:(10 bitwise xor 6) = 12 |
其他函数
| 函数名 | 说明 | 实例 |
|---|---|---|
| close(expr) | 关闭管道的文件 | `$ awk ‘BEGIN { cmd = “tr [a-z] [A-Z]” print “hello, world !!!” |
| delete | 用于从数组中删除元素 | $ awk 'BEGIN { arr[0] = "One" arr[1] = "Two" arr[2] = "Three" arr[3] = "Four" print "Array elements before delete operation:" for (i in arr) { print arr[i] } delete arr[0] delete arr[1] print "Array elements after delete operation:" for (i in arr) { print arr[i] } }'输出结果为:Array elements before delete operation: One Two Three Four Array elements after delete operation: Three Four |
| exit | 终止脚本执行,它可以接受可选的参数 expr 传递 AWK 返回状态。 | $ awk 'BEGIN { print "Hello, World !!!" exit 10 print "AWK never executes this statement." }'输出结果为:Hello, World !!! |
| flush | 刷新打开文件或管道的缓冲区 | |
| getline | 读入下一行 | 使用 getline 从文件 marks.txt 中读入一行并输出:$ awk '{getline; print $0}' marks.txt,AWK 从文件 marks.txt 中读入一行存储到变量 0 中。在下一条语句中,我们使用 getline 读入下一行。因此AWK读入第二行并存储到 0 中。最后,AWK 使用 print 输出第二行的内容。这个过程一直到文件结束。 |
| next | 停止处理当前记录,并且进入到下一条记录的处理过程。 | 当模式串匹配成功后程序并不执行任何操作:$ awk '{if ($0 ~/Shyam/) next; print $0}' marks.txt |
| nextfile | 停止处理当前文件,从下一个文件第一个记录开始处理。 | 首先创建两个文件。 file1.txt 内容如下:file1:str1 file1:str2 file1:str3 file1:str4文件 file2.txt 内容如下:file2:str1 file2:str2 file2:str3 file2:str4现在我们来测试 nextfile 函数。$ awk '{ if ($0 ~ /file1:str2/) nextfile; print $0 }' file1.txt file2.txt输出结果为:file1:str1 file2:str1 file2:str2 file2:str3 file2:str4 |
| return | 从用户自定义的函数中返回值。请注意,如果没有指定返回值,那么的返回值是未定义的。 | 创建文件 functions.awk,内容如下:function addition(num1, num2) { result = num1 + num2 return result } BEGIN { res = addition(10, 20) print "10 + 20 = " res }执行该文件:$ awk -f functions.awk 10 + 20 = 30 |
| system | 执行特定的命令然后返回其退出状态。返回值为 0 表示命令执行成功;非 0 表示命令执行失败。 | $ awk 'BEGIN { ret = system("date"); print "Return value = " ret }'输出结果为:Sun Dec 21 23:16:07 IST 2014 Return value = 0 |
vim全套笔记
VIM快速复习
什么是 vim?
Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。vim 的官方网站 (http://www.vim.org)
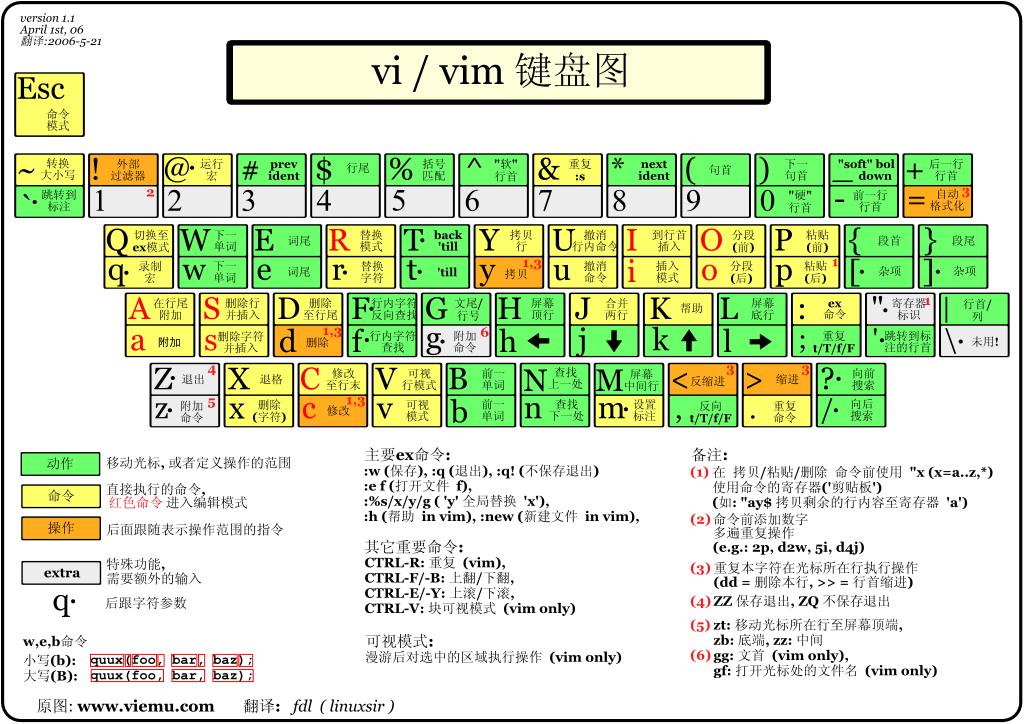
vim 键盘图:
基本上vi可以分为三种状态:
- 命令模式(command mode)
- 插入模式(Insert mode)
- 底行模式(last line mode)
按:冒号即可进入last line mode
1 | :set nu 列出行号 |
从command mode进入Insert mode
按i在当前位置编辑
按a在当前位置的下一个字符编辑
按o插入新行,从行首开始编辑
按R(Replace mode):R会一直取代光标所在的文字,直到按下 ESC为止;(常用)
按ESC键退回command mode
h←j↓k↑l→前面加数字移动指定的行数或字符数
1、翻页bu上下整页,ud上下半页
1 | ctrl+b:上移一页。 |
2、行定位
1 | 7gg或7G:定位第7行首字符。(可能只在Vim中有效) |
3、当前行定位
1 | $:移动到光标所在行的“行尾”。 |
4、编辑
1 | x:剪切当前字符 |
多行编辑,vim支持,vi不支持
按ctrl+V进入块模式,上下键选中快,按大写G选择到末尾,上下左右键移动选择位置
按大写I进去编辑模式,输入要插入的字符,编辑完成按ESC退出
选中要替换的字符后,按c键全部会删除,然后输入要插入的字符,编辑完成按ESC退出
选中要替删除的字符后,按delete键,则会全部删除
按shift+V可进入行模式,对指定行操作
vim练习
1、创建目录/tmp/test,将/etc/man.config复制到该目录下
1 | # mkdir -p /tmp/test |
2、用vim编辑man.config文件:
1 | vim man.config |
3、设置显示行号; 移动到第58行,向右移动40个字符,查看双引号内的是什么目录;
1 | :set nu |
4、移动到第一行,并向下查找“bzip2”这个字符串,它在第几行;
1 | 移动到最后一行,并向上查找该字符串; |
5、将50行到100行之间的man更改为MAN,并且 逐个挑选 是否需要修改;
1 | 若在挑选过程中一直按y,结果会在最后一行出现改变了几个man? |
6、修改完后,突然反悔了,要全部复原,有哪些方法?
1 | 一直按u键 |
7、复制65到73这9行的内容(含有MANPATH_MAP),并且粘贴到最后一行之后;
1 | 65gg或65G到该行后,9yy,G 移动到最后一行,p粘贴 |
8、21行到42行之间开头为#符号的批注数据不要了,如何删除;
1 | 21G到该行 22dd |
9、将这个文件另存为man.test.config的文件
1 | :w man.test.config |
10、到第27行,并且删除15个字符,结果出现的第一个字符是什么?
1 | 27gg 后15x |
11、在第一行新增一行,在该行内输入“I am a student ”
1 | gg到第一行 O输入即可 说明:o是在当前行之后插入一行,O是在当前行之前插入一行 |
12、保存并退出
1 | :wq |
vi/vim的三种模式
vi/vim主要分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。
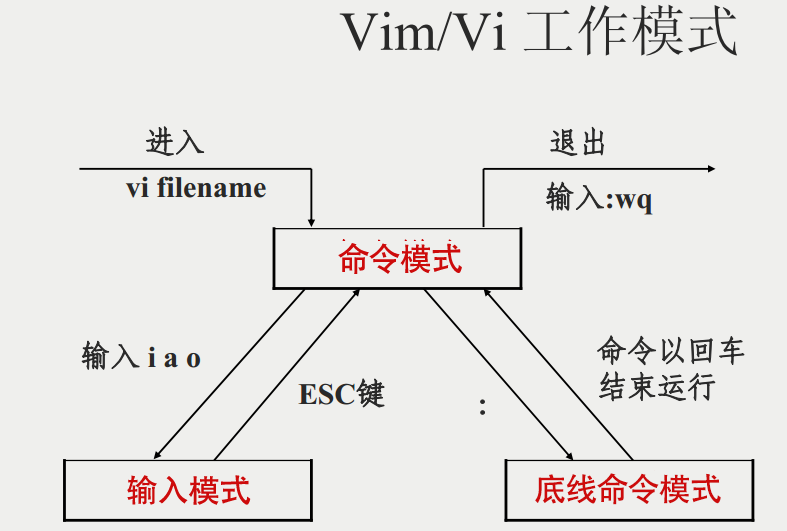
这三种模式的作用分别是:
命令模式
用户刚刚启动 vi/vim,便进入了命令模式。 任何时候,不管用户处于何种模式,只要按一下ESC键,即可使Vi进入命令模式;
此状态下敲击键盘动作会被Vim识别为命令,输入: 可切换到底线命令模式,以在最底一行输入命令。
若想要编辑文本:启动Vim,进入了命令模式,按下i,切换到输入模式。
输入模式
在命令模式下输入插入命令i、附加命令a 、打开命令o、修改命令c、取代命令r或替换命令s都可以进入文本输入模式。在该模式下,用户输入的任何字符都被Vi当做文件内容保存起来,并将其显示在屏幕上。在文本输入过程中,若想回到命令模式下,按键ESC即可。
底行模式
在命令模式下按下:(英文冒号)就进入了底行命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
- q 退出程序
- w 保存文件
按ESC键可随时退出底线命令模式。
vim基础操作
进入输入模式(Insert mode)
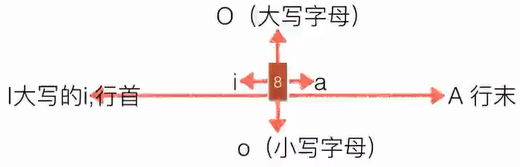
i: 插入光标前一个字符
I: 插入行首
a: 插入光标后一个字符
A: 插入行未
o: 向下新开一行,插入行首
O: 向上新开一行,插入行首
在进入输入模式后, vi 画面的左下角处会出现『–INSERT–』的字样
进入替换模式(Replace mode)
- r : 只会取代光标所在的那一个字符一次
- R: 会一直取代光标所在的文字,直到按下ESC为止
在进入输入模式后, vi 画面的左下角处会出现『–REPLACE–』的字样
命令模式下常用命令
移动光标
| 移动光标的方法 | |
|---|---|
| h 或 向左箭头键(←) | 光标向左移动一个字符 |
| j 或 向下箭头键(↓) | 光标向下移动一个字符 |
| k 或 向上箭头键(↑) | 光标向上移动一个字符 |
| l 或 向右箭头键(→) | 光标向右移动一个字符 |
| 向下移动 30 行,可以使用 “30j” 或 “30↓” 的组合按键 | |
| [Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) |
| [Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) |
| [Ctrl] + [d] | 屏幕『向下』移动半页 |
| [Ctrl] + [u] | 屏幕『向上』移动半页 |
| + | 光标移动到非空格符的下一行 |
| - | 光标移动到非空格符的上一行 |
| n | 表示空格光标向右移动这一行的 n 个字符。例如 20 则光标会向后面移动 20 个字符距离。 |
| 0 或功能键[Home] | 这是数字『 0 』:移动到这一行的最前面字符处 (常用) |
| $ 或功能键[End] | 移动到这一行的最后面字符处(常用) |
| H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
| M | 光标移动到这个屏幕的中央那一行的第一个字符 |
| L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
| G | 移动到这个文档的最后一行(常用) |
| nG | n 为数字。移动到这个文件的第 n 行。例如 20G 则会移动到这个文件的第 20 行(可配合 :set nu) |
| gg | 移动到这个文档的第一行,相当于 1G |
| n | n 为数字。光标向下移动 n 行(常用) |
删除操作
| 删除操作 | 删除后会添加到剪切板,相当于剪切 |
|---|---|
| x, X | x为向后删除一个字符 (相当于 [del] 按键), X为向前删除一个字符(相当于 [backspace] ) |
| nx | n 为数字,连续向后删除 n 个字符。例如10x表示连续删除 10 个字符。 |
| dd | 删除光标所在的一整行(常用) |
| ndd | n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 |
| d1G | 删除光标所在行到首行的所有数据 |
| dG | 删除光标所在行到最后一行的所有数据 |
| d$ | 删除光标所在位置到该行的最后一个字符 |
| d0 | 删除光标所在位置到该行的最前面一个字符 |
撤销&复原&重复
| 撤销&复原 | |
|---|---|
| u | 撤销操作,相对于普通编辑器里面的ctrl+z |
| Ctrl+r | 恢复操作,相对于普通编辑器里面的ctrl+y |
| . | 就是小数点!可重复前一个动作 |
复制&粘贴
| 复制&粘贴 | |
|---|---|
| yy | 复制光标所在行 |
| nyy | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行 |
| y1G | 复制光标所在行到第一行的所有数据 |
| yG | 复制光标所在行到最后一行的所有数据 |
| y0 | 复制光标所在的那个字符到该行行首的所有数据 |
| y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
| p, P | p 为将已复制的数据在光标下一行贴上,P 则为贴在光标上一行! |
合成行
- J: 将光标所在行与下一行的数据结合成同一行
搜索
| 搜索 | |
|---|---|
| /word | 向光标之下寻找一个名称为 word 的字符串。 |
| ?word | 向光标之上寻找一个字符串名称为 word 的字符串。 |
| n | 代表重复前一个搜寻的动作,根据前面输入的/word还是?word向下或向上搜索下一个匹配的字符串。 |
| N | 表示反向搜索,与n的搜索方向相反。 |
替换
| 替换 | |
|---|---|
| :n1,n2s/word1/word2/g | 在第 n1 与 n2 行之间寻找word1并替换为word2!比如『:100,200s/vbird/VBIRD/g』表示在100到200行之间将vbird替换为VBIRD |
:1,$s/word1/word2/g 或 :%s/word1/word2/g |
$表示最后一行,%s表示所有行。 |
:1,$s/word1/word2/gc 或 :%s/word1/word2/gc |
gc中的c表示取代前显示提示字符给用户确认 (confirm) ! |
底行命令模式的常用操作
| 底行命令模式 | |
|---|---|
| :w | 保存编辑数据 |
| :w! | 若文件属性为『只读』时,强制写入该文件。不过,到底能不能写入, 还是跟你对该文件的文件权限有关啊! |
| :q | 离开 vi |
| :q! | 若曾修改过文件,又不想储存,使用 ! 为强制离开不储存文件。 |
| 惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ | |
| :wq | 储存后离开,若为 :wq! 则为强制储存后离开 |
| ZZ | 若文件没有更动,则不储存离开,若文件已经被更动过,则储存后离开! |
| :w [filename] | 另存为 |
| :r [filename] | 将另一个文件『filename』的数据加到光标所在行后面 |
| :n1,n2 w [filename] | 将 n1 到 n2 行的内容储存成 filename 这个文件。 |
| :! command | 暂时离开 vi 到指令行模式下执行 command 的显示结果!例如 『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的文件信息! |
| :set nu | 会在每一行的前缀显示该行的行号 |
| :set nonu | 取消行号显示 |
示例:
1 | 将当前路径插入到光标的下一行 |
可视模式
v 进入字符可视化模式: 文本选择是以字符为单位的。
V 进入行可视化模式: 文本选择是以行为单位的。
Ctrl+v 进入块可视化模式 : 选择一个矩形内的文本。
可视模式下可进行如下操作:
| 可视模式操作 | |
|---|---|
| A | 在选定的部分后面插入内容 |
| I | 在选定的部分前面插入内容 |
| d | 删除选定的部分 |
| c | 删除选定的部分并进入插入模式(有批量替换效果) |
| r | 把选定的部分全部替换为指定的单个字符 |
>> |
向右缩进一个单位,更适合行可视化模式 |
<< |
向左缩进一个单位,更适合行可视化模式 |
gu |
选中区域转为小写 |
gU |
选中区域转为大写 |
g~ |
大小写互调 |
可视模式下,选中的区域是由两个端点来界定的(一个在左上角,一个在右下角),在默认情况下只可以控制右下角的端点,而使用o按键则可以在左上角和右下角之间切换控制端点。
Linux系统启动过程
Linux系统的启动过程可以分为5个阶段:
- 内核的引导。
- 运行 init。
- 系统初始化。
- 建立终端 。
- 用户登录系统。
加载内核
当计算机打开电源后,首先是BIOS开机自检,按照BIOS中设置的启动设备(通常是硬盘)来启动。
操作系统接管硬件以后,首先读入 /boot 目录下的内核文件。

启动初始化进程init
内核文件加载以后,就开始运行第一个程序 /sbin/init,它的作用是初始化系统环境。
init程序首先是需要读取配置文件/etc/inittab。
CentOS 各版本init配置文件的位置:
- SysV: init, CentOS 5之前, 配置文件: /etc/inittab。
- Upstart: init,CentOS 6, 配置文件: /etc/inittab, /etc/init/*.conf。
- Systemd: systemd, CentOS 7,配置文件: /usr/lib/systemd/system、 /etc/systemd/system。
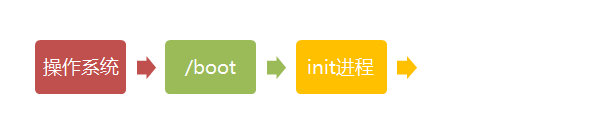
由于init是第一个运行的程序,它的进程编号(pid)就是1。其他所有进程都从它衍生,都是它的子进程。
确定运行级别
许多程序需要开机启动。它们在Windows叫做”服务”(service),在Linux就叫做”守护进程”(daemon)。
init进程的一大任务,就是去运行这些开机启动的程序。
但是,不同的场合需要启动不同的程序,比如用作服务器时,需要启动Apache,用作桌面就不需要。
Linux允许为不同的场合,分配不同的开机启动程序,这就叫做”运行级别”(runlevel)。也就是说,启动时根据”运行级别”,确定要运行哪些程序。

Linux系统有7个运行级别(runlevel):
- 运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
- 运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登陆
- 运行级别2:多用户状态(没有NFS)
- 运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式
- 运行级别4:系统未使用,保留
- 运行级别5:X11控制台,登陆后进入图形GUI模式
- 运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
可以使用运行级别执行关机或重启:
1 | init 0 关机 |
加载开机启动程序
在init的配置文件中有这么一行: si::sysinit:/etc/rc.d/rc.sysinit它调用执行了/etc/rc.d/rc.sysinit,而rc.sysinit是一个bash shell的脚本,它主要是完成一些系统初始化的工作,rc.sysinit是每一个运行级别都要首先运行的重要脚本。
它主要完成的工作有:激活交换分区,检查磁盘,加载硬件模块以及其它一些需要优先执行任务。
1 | l5:5:wait:/etc/rc.d/rc 5 |
这一行表示以5为参数运行/etc/rc.d/rc,/etc/rc.d/rc是一个Shell脚本,它接受5作为参数,去执行/etc/rc.d/rc5.d/目录下的所有的rc启动脚本,/etc/rc.d/rc5.d/目录中的这些启动脚本实际上都是一些连接文件,而不是真正的rc启动脚本,真正的rc启动脚本实际上都是放在/etc/rc.d/init.d/目录下。
而这些rc启动脚本有着类似的用法,它们一般能接受start、stop、restart、status等参数。
/etc/rc.d/rc5.d/中的rc启动脚本通常是K或S开头的连接文件,对于以 S 开头的启动脚本,将以start参数来运行。
而如果发现存在相应的脚本也存在K打头的连接,而且已经处于运行态了(以/var/lock/subsys/下的文件作为标志),则将首先以stop为参数停止这些已经启动了的守护进程,然后再重新运行。
这样做是为了保证是当init改变运行级别时,所有相关的守护进程都将重启。
至于在每个运行级中将运行哪些守护进程,用户可以通过chkconfig或setup中的”System Services”来自行设定。
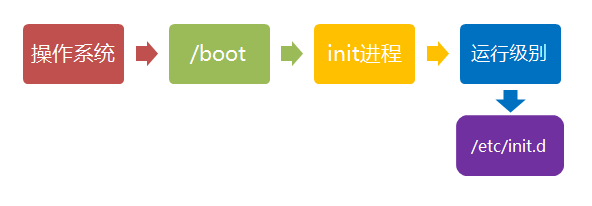
用户登录
一般来说,用户的登录方式有三种:
- (1)命令行登录
- (2)ssh登录
- (3)图形界面登录
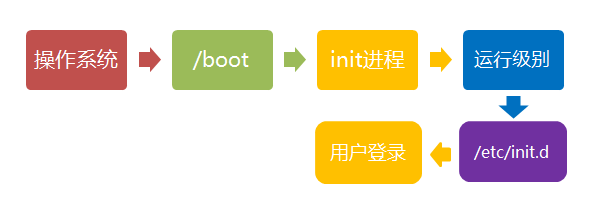
对于运行级别为5的图形方式用户来说,他们的登录是通过一个图形化的登录界面。登录成功后可以直接进入 KDE、Gnome 等窗口管理器。
而本文主要讲的还是文本方式登录的情况:当我们看到mingetty的登录界面时,我们就可以输入用户名和密码来登录系统了。
Linux 的账号验证程序是login,login会接收mingetty传来的用户名作为用户名参数。
然后login会对用户名进行分析:如果用户名不是root,且存在 /etc/nologin 文件,login 将输出 nologin 文件的内容,然后退出。
这通常用来系统维护时防止非root用户登录。只有/etc/securetty中登记了的终端才允许 root 用户登录,如果不存在这个文件,则root用户可以在任何终端上登录。
/etc/usertty文件用于对用户作出附加访问限制,如果不存在这个文件,则没有其他限制。
图形模式与文字模式的切换方式
Linux预设提供了六个命令窗口终端机让我们来登录。
默认我们登录的就是第一个窗口,也就是tty1,这个六个窗口分别为tty1,tty2 … tty6,你可以按下Ctrl + Alt + F1 ~ F6 来切换它们。
如果你安装了图形界面,默认情况下是进入图形界面的,此时你就可以按Ctrl + Alt + F1 ~ F6来进入其中一个命令窗口界面。
当你进入命令窗口界面后再返回图形界面只要按下Ctrl + Alt + F7 就回来了。
如果你用的vmware 虚拟机,命令窗口切换的快捷键为 Alt + Space + F1F6. 如果你在图形界面下请按Alt + Shift + Ctrl + F1F6 切换至命令窗口。
login shell
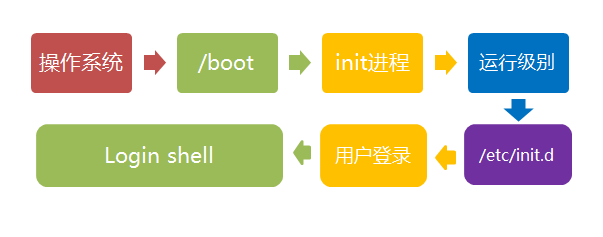
shell,简单说就是命令行界面,让用户可以直接与操作系统对话。用户登录时打开的shell,就叫做login shell。
(1)命令行登录:首先读入 /etc/profile,这是对所有用户都有效的配置;然后依次寻找下面三个文件,这是针对当前用户的配置。
1 | ~/.bash_profile |
需要注意的是,这三个文件只要有一个存在,就不再读入后面的文件了。比如,要是 ~/.bash_profile 存在,就不会再读入后面两个文件了。
(2)ssh登录:与第一种情况完全相同。
(3)图形界面登录:只加载 /etc/profile 和 /.profile。也就是说,/.bash_profile 不管有没有,都不会运行。
Linux关机
1 | sync 将数据由内存同步到硬盘中。 |
最后总结一下,不管是重启系统还是关闭系统,首先要运行sync命令,把内存中的数据写到磁盘中。
关机的命令有 shutdown –h now halt poweroff 和 init 0 , 重启系统的命令有 shutdown –r now reboot init 6。
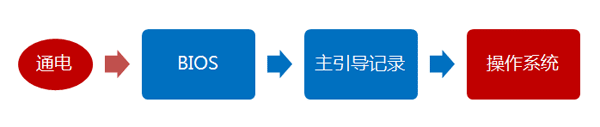
计算机启动的流程
boot是bootstrap(鞋带)的缩写,它来自一句谚语:
“pull oneself up by one’s bootstraps”
字面意思是”拽着鞋带把自己拉起来”,这当然是不可能的事情。最早的时候,工程师们用它来比喻,计算机启动是一个很矛盾的过程:必须先运行程序,然后计算机才能启动,但是计算机不启动就无法运行程序!
早期真的是这样,必须想尽各种办法,把一小段程序装进内存,然后计算机才能正常运行。所以,工程师们把这个过程叫做”拉鞋带”,久而久之就简称为boot了。
计算机的整个启动过程分成四个阶段。
第一阶段:BIOS
上个世纪70年代初,“只读内存”(read-only memory,缩写为ROM)发明,开机程序被刷入ROM芯片,计算机通电后,第一件事就是读取它。
BIOS全称是Basic Input/Output System,即基本输入输出系统,即下图芯片里的程序。

硬件自检
BIOS程序首先检查,计算机硬件能否满足运行的基本条件,这叫做”硬件自检”(Power-On Self-Test),缩写为POST。
如果硬件出现问题,主板会发出不同含义的蜂鸣,启动中止。如果没有问题,屏幕就会显示出CPU、内存、硬盘等信息。
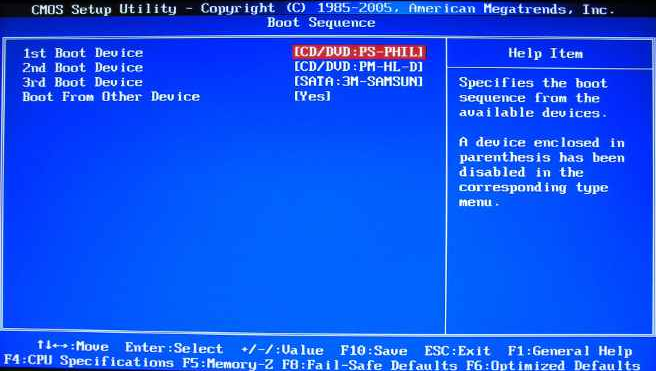
启动顺序
硬件自检完成后,BIOS把控制权转交给下一阶段的启动程序。
下一阶段的启动程序根据BIOS设置项Boot Sequence(启动顺序)决定,排在前面的设备就是优先转交控制权的设备。
第二阶段: 主引加粗样式导记录
BIOS按照”启动顺序”,把控制权转交给排在第一位的储存设备。
这时,计算机读取该设备的第一个扇区,也就是读取最前面的512个字节。如果这512个字节的最后两个字节是0x55和0xAA,表明这个设备可以用于启动;如果不是,表明设备不能用于启动,控制权于是被转交给”启动顺序”中的下一个设备。
这最前面的512个字节,就叫做“主引导记录”(Master boot record,缩写为MBR)。
主引导记录组成
主引导记录由三个部分组成:
(1) 第1-446字节:调用操作系统的机器码。
(2) 第447-510字节:分区表(Partition table),共64字节。
(3) 第511-512字节:主引导记录签名(0x55和0xAA)。
其中,第二部分”分区表”的作用,是将硬盘分成若干个区。
分区表
硬盘分区有很多好处。每个分区可以安装不同的操作系统,”主引导记录”因此必须知道将控制权转交给哪个区。
分区表的长度只有64个字节,里面又分成四项,每项16个字节。所以,一个硬盘最多只能分四个一级分区,又叫做”主分区”。
每个主分区的16个字节,由6个部分组成:
(1) 第1个字节:如果为0x80,就表示该主分区是激活分区,控制权要转交给这个分区。四个主分区里面只能有一个是激活的。
(2) 第2-4个字节:主分区第一个扇区的物理位置(柱面、磁头、扇区号等等)。
(3) 第5个字节:主分区类型。
(4) 第6-8个字节:主分区最后一个扇区的物理位置。
(5) 第9-12字节:该主分区第一个扇区的逻辑地址。
(6) 第13-16字节:主分区的扇区总数。
最后的四个字节(“主分区的扇区总数”),决定了这个主分区的长度。也就是说,一个主分区的扇区总数最多不超过2的32次方。
如果每个扇区为512个字节,就意味着单个分区最大不超过2TB。再考虑到扇区的逻辑地址也是32位,所以单个硬盘可利用的空间最大也不超过2TB。如果想使用更大的硬盘,只有2个方法:一是提高每个扇区的字节数,二是增加扇区总数。
第三阶段:硬盘启动
这时,计算机的控制权就要转交给硬盘的某个分区了,这里又分成三种情况。
情况A:卷引导记录
上一节提到,四个主分区里面,只有一个是激活的。计算机会读取激活分区的第一个扇区,叫做“卷引导记录“(Volume boot record,缩写为VBR)。
“卷引导记录”的主要作用是,告诉计算机,操作系统在这个分区里的位置。然后,计算机就会加载操作系统了。
情况B:扩展分区和逻辑分区
随着硬盘越来越大,四个主分区已经不够了,需要更多的分区。但是,分区表只有四项,因此规定有且仅有一个区可以被定义成”扩展分区”(Extended partition)。
所谓”扩展分区”,就是指这个区里面又分成多个区。这种分区里面的分区,就叫做”逻辑分区”(logical partition)。
计算机先读取扩展分区的第一个扇区,叫做“扩展引导记录”(Extended boot record,缩写为EBR)。它里面也包含一张64字节的分区表,但是最多只有两项(也就是两个逻辑分区)。
计算机接着读取第二个逻辑分区的第一个扇区,再从里面的分区表中找到第三个逻辑分区的位置,以此类推,直到某个逻辑分区的分区表只包含它自身为止(即只有一个分区项)。因此,扩展分区可以包含无数个逻辑分区。
但是,似乎很少通过这种方式启动操作系统。如果操作系统确实安装在扩展分区,一般采用下一种方式启动。
情况C:启动管理器
在这种情况下,计算机读取”主引导记录”前面446字节的机器码之后,不再把控制权转交给某一个分区,而是运行事先安装的“启动管理器”(boot loader),由用户选择启动哪一个操作系统。
Linux环境中的启动管理器例如Grub。
第四阶段:操作系统
控制权转交给操作系统后,操作系统的内核首先被载入内存。
以Linux系统为例,先载入/boot目录下面的kernel。内核加载成功后,第一个运行的程序是/sbin/init。它根据配置文件(Debian系统是/etc/initab)产生init进程。这是Linux启动后的第一个进程,pid进程编号为1,其他进程都是它的后代。
然后,init线程加载系统的各个模块,比如窗口程序和网络程序,直至执行/bin/login程序,跳出登录界面,等待用户输入用户名和密码。
至此,全部启动过程完成。
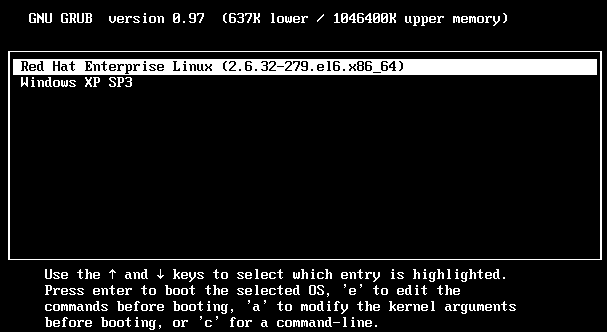
单用户模式修改Centos系统root密码
步骤如下:
重启linux系统
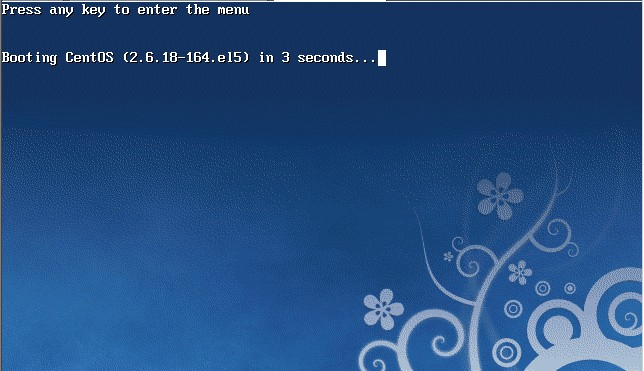
3 秒之内要按一下回车,出现如下界面
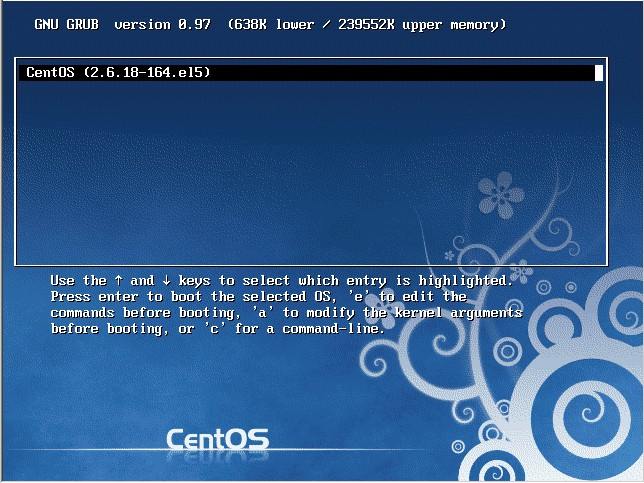
按向下方向键移动到第二行,按”e”进入编辑模式
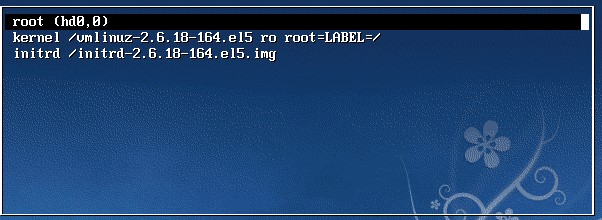
在 第二行最后边输入 single,用空格与前面内容隔开

回车

最后按”b”启动,启动后就进入了单用户模式了
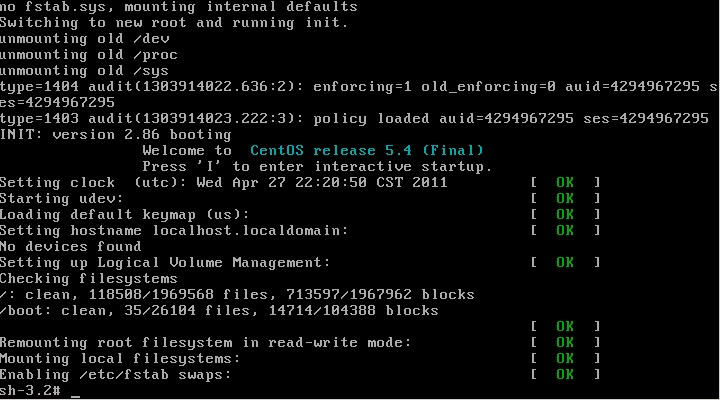
进入到单用户模式后,就可以使用passwd命令任意更改root密码了:

救援模式修改Ubuntu系统root密码
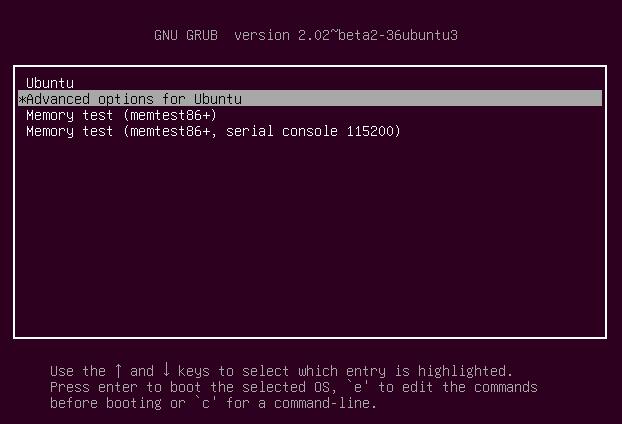
重启,按住shift键,出现如下界面,选中如下选项
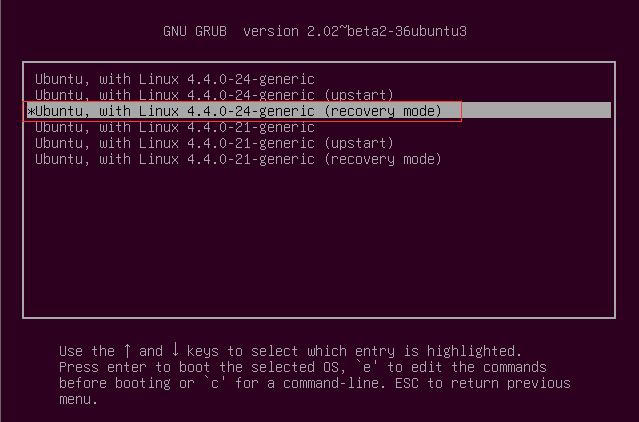
按回车键进入如下界面,然后选中最新的recovery mode选项
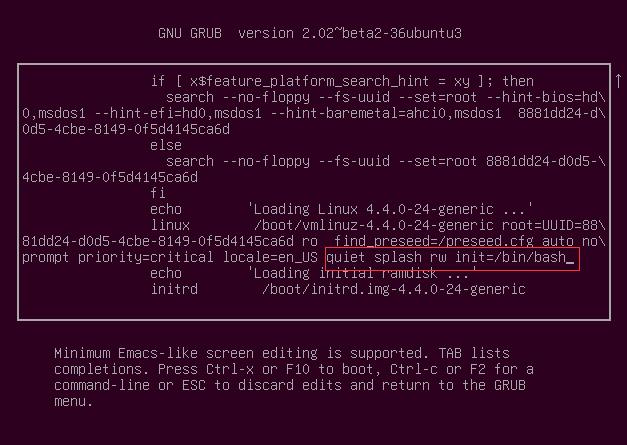
按e进入如下界面,找到图中红色框的recovery nomodeset并将其删掉,再在这一行的后面输入
1 | quiet splash rw init=/bin/bash |

接着按F10或者Ctrl+x 后出现如下界面,在命令行内输入passwd后进行修改密码即可
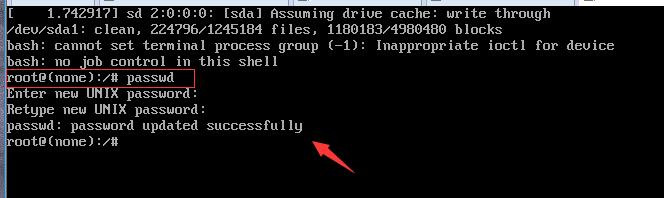
修改完之后重启系统。
虚拟机
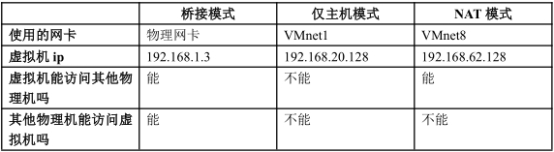
三种网络模式
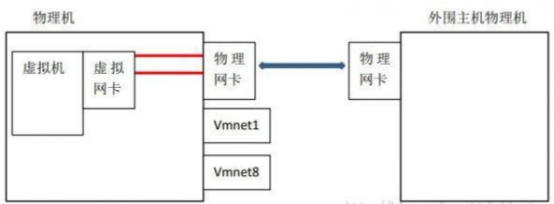
桥接
在网络网卡上安装了一个桥接协议,让这块网卡处于混杂模式,可以同时连接多个网络的做法。
桥接下,类似于把物理主机虚拟为一个交换机,所有桥接设置的虚拟机连接到这个交换机的一个接口上,物理主机也同样查在这个交换机当中,所以所有桥接下网卡与网卡都是交换模式的,相互可以访问而不干扰。
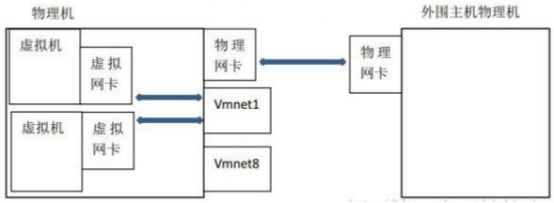
Host-only(仅与主机通信)
虚拟机使用VMnet1网卡与主机单独组网,主机对于虚拟机相当于路由器
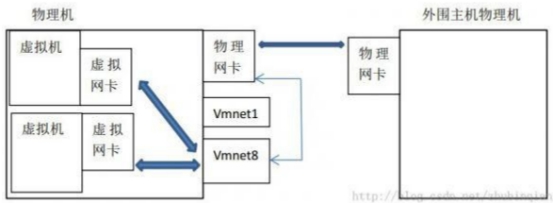
NAT
虚拟机使用VMnet8网卡与主机单独组网,主机对于虚拟机相当于路由器,VMnet8网卡通过NAT地址转换协议与物理机网卡通信
常见问题
修改静态地址后发现无法ping外网
1 | 需要设置网关 |
虚拟机克隆后eth0消失
1 | 直接修改 /etc/sysconfig/network-script/ifcfg-eth0 |


