
Python数据挖掘

课程设计
从构建数据挖掘思维的角度出发,为你详解数据挖掘,具体分为三大部分:
基础知识准备(模块一)。带你建立对数据挖掘的全局认知,学习课程中可能会涉及的一些基础知识(包括必备的Python语言知识,以及如何搭建Python环境),帮你快速进入状态。
数据挖掘过程(模块二)。授人以鱼不如授人以渔,重点是让你能够在思想和行为上都做足准备,全面细致地了解数挖掘方法的实施过程。同时,我也会讲到数据挖掘过程中的每一个步骤都会遇到哪些坑,帮你加强思考、少走弯路,明白从理论到实战,“数据挖掘”这个词是如何一步步变具体的。
算法详解(模块三~模块七)。涉及数据挖掘的分类、聚类、回归、关联分析这四大问题,以及一些自然语言处理的知识。重点介绍每个算法的理念、优缺点、应用场景,配合一些简短的代码来说明该如何使用,让你能够快速上手应用。每个模块的最后一个课时,我会通过为本课程设计的实践案例,来带你处理一个实际问题。
课程最后整理一些数据挖掘的开源工具和学习资源:如果你不会写代码,也可以先使用这些工具来进行数据挖掘;如果你希望在数据挖掘方面有更加深入的学习和理解,那么这些资源也会帮到你。
| 23 word2vec:让文字可以进行逻辑运算 |
|---|
| 24 实践5:使用fastText 进行新闻文本分类 |
| 彩蛋:数据挖掘工程师如何进阶 |
| 结语:培养数据挖掘思维,终身学习 |
什么是数据挖掘?
这个问题看似很简单,但似乎也很难有一个明确的答案。
“数据驱动”早已被各大互联公司奉为圭臬,并且很多大公司都建有成熟的数据仓库、数据分析平台、数据挖掘平台、数据运营平台,数据驱动业务的做法已经成为常态,数据挖掘的重要性不言而喻。
今日头条借助数据挖掘为用户推荐对他们更有价值、更加个性化的新闻;滴滴依靠数据挖掘算法来规划、寻找最优化路线;美团外卖凭借数据挖掘算法进行热度预估和订单分派,等等。几乎每一个你所用到的App背后都有数据挖掘的身影。
而且近些年,数据挖掘在许多传统型公司也得到极高重视,它们纷纷成立数字化转型部门,期望搭上时代的数字化列车为业务赋能。
银行,期望借助数据挖掘来对贷款、信用卡等业务进行风险控制;
金融基金公司,通过数据挖掘来提高基金及金融产品的收益;
大型商超公司,希望用数据挖掘来寻找最佳的进货和销售配比;
能源电力公司,希望借助数据挖掘来分析风力发电站建设的位置以及机组的安全评估,等等。
这样的例子不胜枚举,金融、零售、医药、制造、交通、通信、能源等,几乎所有的行业都会应用到数据挖掘,就业市场对数据挖掘人才的需求远远没有饱和。
如果非要给数据挖掘一个定义的话,那么我认为数据挖掘就是寻找数据中隐含的知识并用于产生商业价值。也就是说,它是我们在数据中(尤其是在大量的数据中)找到一些有价值,甚至是非常有价值的东西的一种手段。
为什么要做数据挖掘?
数据挖掘的产生动因主要有以下3点。
海量数据。随着互联网技术的发展,数据的生产、收集和存储也越来越方便,海量数据因此产生。比如,我们常用的微信,每天要产生超过380亿条数据;今日头条每天要发布上百万的新文章;淘宝每天有上千万的包裹要发出。
维度众多。在一个多维度的数据中,每增加一个维度都会增加数据分析的复杂程度。比如点外卖事件涉及的维度就有:浏览饭店的菜品(形式有文字、图片或语言、视频等)、浏览时间、下单价 格、交易处理、分配配送员及GPS信息、完成订单后的评价等。
问题复杂。通常用数据挖掘解决的问题都比较复杂,很难用一些规则或者简单的统计给出结果。如果让开发者写一个微波炉的智能控制逻辑,我想难度不是很大,即便是有十几个,甚至几十个按 钮的控制中心也不过是多花费一点时间而已。但如果编写一段代码来区分某图片中是否有一只猫 咪,那要考虑的问题就太多了,使用传统的方法很难解决,而这恰恰是数据挖掘所擅长的。
以上是我们进行数据挖掘的初衷,在后续的课程中你也会看到,随着这些问题的出现,它们在数据挖掘中是如何被解决的。
数据挖掘有什么用处?
既然数据挖掘是一种方法,那就要用它去解决一些问题。下面我就来具体讲一下你最关心的,也是最实际的问题,数据挖掘到底有什么用处。
1.分类问题
分类问题是最常见的问题。比如新闻网站,判断一条新闻是社会新闻还是时政新闻,是体育新闻还是娱乐新闻?这就是一个分类问题,也就是对已知类别的数据进行学习,为新的内容标注一个类别。

新闻 |
大家正在搜:全国房 |
|---|

新闻 军事 国内 国际 体育 NBA 英超 中超
财经 股票 基金 外汇 娱乐 明星 电影 星座
新浪导航栏图
2.聚类问题
聚类与分类不同,聚类的类别预先是不清楚的,我们的目标就是要去发现这些类别。聚类的算法比较适合一些不确定的类别场景。
比如我们出去玩,捡了一大堆不同的树叶回来,你不知道这些树叶是从什么树上掉落的,但是你可以根据它们的大小、形状、纹路、边缘等特征给树叶进行划分,最后得到了三个较小的树叶堆,每一堆树叶都属于同一个种类。
3.回归问题
简单来说,回归问题可以看作高中学过的解线性方程组。它的最大特点是,生成的结果是连续的,而不像分类和聚类生成的是一种离散的结果。
比如,使用回归的方法预测北京某个房子的总价(y),假设总价只跟房子的面积(x)有关,那么我们构建的方程式就是ax+b=y。。如何根据已知x和y的值解出a和b就是回归问题要解决的。回归方法是通过构建一个模型去拟合已知的数据(自变量),然后预测因变量结果。
4.关联问题
关联问题最常见的一个场景就是推荐,比如,你在京东或者淘宝购物的时候,在选中一个商品之后,往往会给你推荐几种其他商品组合,这种功能就可以使用关联挖掘来实现。

京东组合购买推荐图
到这里,我们清楚了数据挖掘可以解决哪些问题,那具体应该怎么做呢?
数据挖掘怎么做?
数据挖掘,也是有方法论的。实际上,数据挖掘经过了数十年的发展和无数专家学者的研究,有很多人提出了完整的流程框架,这对于我们来说简直是福音。当然,如果你在使用的过程中觉得这些东西有问题,或者还有改进的空间,那也不要惧怕权威,尽信书则不如无书嘛。
在这里,我讲一个应用最多的CRISP-DM (Cross-industry Standard Process for Data Mining,跨行业数据挖掘标准流程)方法论,不要被这么长的名字吓到,这里我们先简单地了解数据挖掘的操作步骤有哪些,后面我也会逐一详细讲解。
下面我们就来看一下,如何依照这6个步骤进行数据挖掘。

CRISP-DM流程图
1.业务理解(Business Understanding)
想象你在一个外贸公司上班,有一天,你的老板突然给你说:“小明啊,你能不能训练一个模型来预测一下明年公司的利润呢?”
这就是一个业务需求了,若要解决这个问题,首先要弄明白需求是什么,这就是业务理解,或者也可以叫作商业理解。比如,你要搞清楚什么是利润、利润的构成是什么样的、利润受什么影响,同时老板说的利润是净利润还是毛利润等问题。
业务理解,主旨是理解你的数据挖掘要解决什么业务问题。任何公司启动数据挖掘,都是想为业务赋能,因此我们必须从商业或者从业务的角度去了解项目的要求和最终的目的,去分析整个问题涉及的资源、局限、设想,甚至是风险、意外等情况。从业务出发,到业务中去。
2.数据理解(Data Understanding)
明白了问题,还要明白解决问题需要什么数据。比如这个时候,你的老板又跟你说了:“小明啊,我想改改需求,能不能多做几个模型,把竞品公司明年的利润也都算算,我想对比一下。”然而“巧妇难为无米之炊”,你根本就没有这个数据,这个需求也就无从完成了。
数据理解阶段始于数据的收集工作,但我认为重点是在业务理解的基础上,对我们所掌握的数据要有一个清晰、明确的认识,了解有哪些数据、哪些数据可能对目标有影响、哪些可能是冗余数据、哪些数据存在不足或缺失,等等。
需要注意的是,数据理解和业务理解是相辅相成的,因此你在制定数据挖掘计划的时候,不能只是单纯地谈需求,这也是大多数初入门的数据挖掘工程师容易忽略的。数据理解得不好,很可能会导致你对业务需求的错误评估,从而影响后续进度甚至是结果。
3.数据准备(Data Preparation)
完成上面两个步骤后,我们就可以准备数据了。你需要找销售要销售数据,找采购要采购数据,找财务要各种收入、支出数据,然后整理所有需要用到的数据,想办法补全那些缺失的数据,计算各种统计值,等等。数据准备就是基于原始数据,去构建数据挖掘模型所需的数据集的所有工作,包括数据收集、数据清洗、数据补全、数据整合、数据转换、特征提取等一系列动作。
事实上,在大多数的数据挖掘项目中,数据准备是最困难、最艰巨的一步。如果你的数据足够干净和完整,那么在建模和评估阶段所付出的精力就越少,甚至都不必去使用什么复杂的模型就可以得到足够好的效果,所以这个阶段也是十分重要的。
4.构建模型(Modeling)
也可以叫作训练模型,在这一阶段,我们会把准备好的数据喂给算法,所以这个阶段重点解决的是技术方面的问题,会选用各种各样的算法模型来处理数据,让模型学习数据的规律,并产出模型用于后续的工作。
对于同一个数据挖掘的问题类型,可以有多种方法选择使用。如果有多重技术要使用,那么在这一任务中,对于每一个要使用的技术要分别对待。一些建模方法对数据的形式有具体的要求,比如SVM算法只能输入数值型的数据,等等。因此,在这一阶段,重新回到数据准备阶段执行某些任务有时是非常必要的。
5.评估模型(Evaluation)
在模型评估阶段,我们已经建立了一个或多个高质量的模型。但是模型的效果如何,能否满足我们的业务需求,就需要使用各种评估手段、评估指标甚至是让业务人员一起参与进来,彻底地评估模型,回顾在构建模型过程中所执行的每一个步骤,以确保这些模型达到了目标。在评估之后会有两种情况,一种是评估通过,进入到上线部署阶段;另一种是评估不通过,那么就要反过来再进行迭代更新了。
6.模型部署(Deployment)
整理了数据,研究了算法模型,并通过了多方评估,终于到了部署阶段。此时可能还要解决一些实际的问题,比如长期运行的模型是否有足够的机器来支撑,数据量以及并发程度会不会造成我们部署的服务出现问题,等等。但是,关于数据挖掘的生命周期可能还远未结束,关于一些特殊情况的出现可能仍然无法处理,以及在后续的进程中,随着新数据的生产以及变化,我们的模型仍然会发生一些变化。所以部署是一个挖掘项目的结束,也是一个数据挖掘项目的开始。
Python的介绍
Python是一门面向对象、直译式编程语言,编写简单、上手迅速,开源扩展包十分丰富,所以在数据挖掘的前沿科研和工业领域都广受欢迎,有着瑞士军刀般的价值。利用Python,可以非常方便地开展各种领域的数据挖掘工作。
在后续的课时中,如果没有特殊说明,一般使用的是Python 3的语法。因为Python 3相比2有了很大的调整和改进,对中文的支持也更加友好。
下面我们先来看一下为什么要用Python进行数据挖掘。
Python的优、缺点
1.优点
简单易学:Python的代码比较简洁、语法比较规范,甚至有点像伪代码,很容易上手。如果你有其他编程语言基础的话,那么学习Python就会变得很快了。如果你没有学过,也不要担心,市面上关于Python入门的课程非常多,足够满足你的需求。
开源:因为用户可以免费使用,所以不管是在工作中,还是在学习中,使用Python的人群都很多,这使得各种更新包层出不穷。
可移植性好:在不同的平台都可以运行,不管是MacOS、Windows 还是Linux,唯一需要注意的是运行环境的配置。比如Python中各种包的依赖关系,如果处理不好将导致程序无法运行,要注意避免。下一课时我会介绍一种常用的包管理办法。
可扩展性:Python拥有丰富的第三方库,不管是文件操作、网络编程、各种数据库,还是3D图形编程都可以运用到。
2.缺点
通常来说Python的缺点就1个,为了使语言更加简便易懂,Python在底层做了很多工作,所以其运行速度比C、Java等要慢很多。如果非要说还有什么缺点,我认为,由于各种扩展库太庞大,导致配置这些相关包有些困难,比如不同版本的包可能存在不兼容的情况,甚至是Python语言本身,在从2.x 版本升级到3.x版本后,很多语句和功能都发生了变化,无法跨版本运行。
知道了Python的特点之后,我们来了解一下它的数据类型,这对我们编写代码有很大的帮助。
Python 支持的数据类型
Python 支持的数据类型,如下表所示:
| 类型名 | 说明 | 描述 |
|---|---|---|
| str | 字符串类型 | 一段字符串 |
| int | 整型 | 整数,比如1、2、3 |
| float | 浮点型 | 比如0.1、0.315 |
| bool | 逻辑值 | true or false |
| complex | 复数 | 数学上的概念 |
| bytes | 字节型 | 原始的数据类型,可以理解为01代码 |
| list | 列表 | 有序可修改的列表 |
| tuple | 元组 | 元组比较特别,它是一个不可以修改的有序列表 |
| set | 集合 | 无序,唯一的值的合集 |
| dict(map) | 字典 | 类似于map |
Python的数据类型有一个特色,在声明一个变量的时候可以不声明它的类型,而是在赋值时才确定类型。同时在声明的容器型变量(如下面提到的列表、字典等)中,内部的元素类型也是任意的。
由于列表、集合和字典将非常频繁地使用,尤其是在我们的数据挖掘过程中,数据通常都会以向量的方式表示、存储在列表中。所以掌握这些数据类型,以及它们的各种扩展方法是非常有好处的。在这里我会对上述常用的三种数据进行详细的说明,当然数据结构类型远远不止这几种情况,如果你有兴趣,可以找其他资料进行深入了解学习。
1.列表(list)
列表可以理解为是一个有序可重复的数组,主要用于按顺序存放我们的数据。
首先,来举个例子,下面是一个为列表赋值的语句:
通过该语句生成了一个列表,即list,里面有5个元素,但它们的类型不一样,前2个是字符串,后3个是数字。
列表中的元素是有序的,每个元素都有一个位置标记,并且元素可以重复。比如下面这两个语句,即用列表的位置下标来获取对应的元素并输出。我们输出list[0]会得到’one‘这个单词,因为one存放在了list的第0个位置,而输出list[4]会得到数字5,因为数字5存放在了list的第4个位置,注意,在计算机语言中,一般位置标识都是从0开始的。

列表的基本操作主要有添加、删除、修改等功能,同时Python还提供了一系列的扩展功能,如查询列表长度、列表运算,等等。
添加元素
删除元素
修改元素、查询列表长度、列表的运算以及判断某一元素是否在列表中
例如 list[2] = ‘three’ len(list) list1+list2 list1 * 2 x in list
除了上述的操作,列表还有很多已经实现好的方法可供你使用,比如列表排序、找到最大值和最小值、逆序排列等。由于功能模块非常多,当大家有需要的时候可以根据自己的需求进行查询,我就不在这里-阐述了。
2.集合(set)
集合是一个无序的不重复序列,可以使用大括号(}或者set()函数创建集合。需要注意的是,创建一个空集合必须用set()而不能用{},因为{}是用来创建一个空字典的。
比如,我们要新建一个叫abc的集合:
添加元素
删除元素
3.字典(dict)
字典中存放的每一个元素实际上是一个键值对(key:value),其中key是不能重复的,存入相同的key,它的value会被替换成最新的。dict={}代表使用大括号声明一个空字典。
字典中的元素可以是任意类型,比如数值、字符串、列表,甚至是字典:
向字典中添加键值对
从字典中删除键值对
了解了数据类型,就可以进行简单的语句书写了,不过每种语言都有自己的书写习惯,所以在正式进入代码编写前,我要给你说明一下Python的四个注意事项。
编写Python代码的注意事项
1.标识符
标识符就是你定义的名称,包括类名、变量名,等等。在Python中,标识符的大小写是敏感的,且第一个字符必须是字母表中的字母或“_”。在Python3中,甚至中文也可被用作变量名。
当然,Python有一些自留标识符,比如def、true、false等,我们不能再使用这些作为标识符。
2.注释
注释是为了方便阅读代码写的内容,这些内容将不会被解释器解释执行。Python中有两种注释方法:
第一种是注释单行,可以使用“#”,出现在“#”后面的该行内容将变成注释(如上面代码块中“#输出one”等),不会被运行;
第二种是注释一段,可以使用“或者””来处理多行注释,比如:
1 | ''' |
3.使用缩进来标记代码块
在很多编程语言中,比如C++和Java,都是使用大括号0}来对代码段进行分割的,但是在Python中不需要,而是使用缩进来对代码段进行控制。所以在编写Python代码的时候,一定要非常注意缩进规范。
如果你使用IDE(Integrated Development Environment,集成开发环境)来编辑代码,一般都会有缩进提醒,但使用文本编辑器就可能会经常遇到缩进的问题了。
比如下面这段正确的代码,就是使用缩进来标记的:
1 | if a>b: |
如果写成对齐的样子就会出错,无法输出结果:
1 | if a>b: |
如果一行代码实在太长,你需要把它分割成多行来写,可以使用“\”进行连接,比如:
1 | num = num + \ |
如果是在括号里的内容,那就不需要使用“”,直接换行就行了。
4.导入其他模块
在Python的扩展中,有很多第三方编写的模块,并且我们在组织大型项目代码的时候,也会把代码分成好多的模块,这里就涉及导入或者说是引用的问题了。
这时候要用到两个命令 import或者from..import。import的主要作用是导入整个模块,或者导入模块中的模块;而from…import是从某个模块中导入某个方法(函数),比如:
1 | import tensorflow as tf |
到这里,Python的基本知识你就都了解了,可以开始学习语句,进行代码编写了。
常用语句
Python的语句有很多种,在这里我只给大家介绍3种常用的,包括条件语句、循环语句和pass语句,剩下的语句,如运算符、各种函数功能模块,大家可以通过搜索资料自行学习。
1.条件语句
条件判断是最常用到的方法,可以用来各种情况的判定,从而影响语句的执行,使用方法如下:
if条件:
执行
elif条件:
执行
else:
执行
1 | if a>b and a>c: |
2.循环语句
循环语句相关的主要有while语句、for语句、continue 语句、break语句。
- while 循环
1
2
3while a>b:
print(a)
b=b+1 - for循环
1
2for i in range(0,100):
print(i)
continue 跳过
1 | for i in range(0,100): |
- break终止循环
1 | for i in range(0,100): |
3.pass 语句
在Python中有一个特别的语句,那就是pass语句,该语句代表什么都没有,主要用于一些特殊的位置。如果在一段代码中必须要写一些语句,又不能产生任何影响,就可以使用pass语句。
比如我们想写一个代码,当i<50的时候什么都不做,就可以这么写:
1 | for i in range(0,100): |
在实际编写代码的时候,有些位置你可能想要写一些功能,但是还没有想好要怎么写,比如你定义了一个函数,但是函数的具体内容还没确定,此时就可以预留出一些位置暂时写上pass语句,从而不会影响代码的运行。
工欲善其事,必先利其器。想用Python写出漂亮的代码,没有合适的编辑器怎么行。下面我就给你介绍5种Python编辑器,希望你能找到合适的工具。
Python的编辑器
1.PyCharm
PyCharm是由大名鼎鼎的JetBrains开发的,它是一款Python专用IDE,不用说它的功能十分强大,开发版是免费的,通常可以满足一般开发者的需求,但如果你有大型项目开发的需求,那么可以选择购买一个专业版的。

PyCharm 界面图
2.Spyder
推荐这个IDE的不多,但是在Anaconda(下一课时会具体介绍)中集成了这个IDE,而且是免费的,所以在测试环境下,我经常就使用它进行代码编写,它的功能没有PyCharm那么强大,但对于日常实验也够用了。

Spyder界面图
3.VIM
关于VIM我就不多做介绍了,在Linux系统上,尤其是服务器上,最常用的文本编辑软件。

VIM界面图
4.Sublime
SublimeText是一款用于代码、标记和散文的精致文本编辑器,它与VIM一样都属于文本编辑器,界面简洁清爽,反应十分迅速,但其优势是扩展了代码开发的功能,支持代码高亮、语法提示等功能。
Sublime 界面图
5.Jupyter Notebook
Jupyter Notebook 是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
它的好处就是轻量,而且对于数据的可视化非常友好,对于一些小型实验,或者数据分析,使用Jupyter Notebook 非常方便。
在Anaconda 里面也集成了Jupyter Notebook,有兴趣的同学可以深入探索。

Jupyter Notebook 界面图
标准库
Python的标准库是其核心的扩展,其中包括了操作系统接口、文件操作、输入输出流、文本处理等功能。
这里先推荐两个能帮助我们学习常用包的方法:
比如,对math 模块使用dir(math),可以看到math模块里所有方法的名称,结果如下:
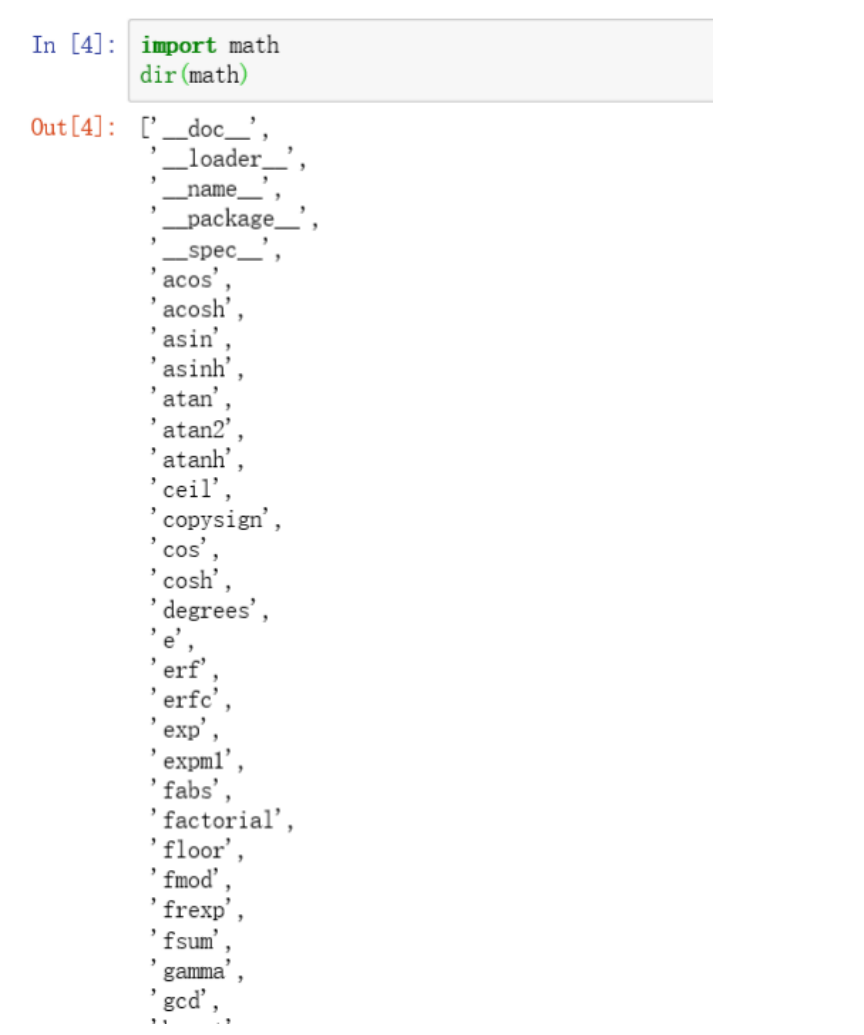
math 模块里面所有方法的名称图
使用help(math),可以看到math模块的描述,以及各个方法的介绍,结果如下:
math 模块的描述图
在写代码的时候如果忘记某个功能的名字或者不知道有哪些功能,就可以通过上面两个方法去查看。
接下来,我要介绍一下数据挖掘中常用的6个模块,及其应用场景,请见下表:
| 模块名称 | 模块简介 | 应用场景 |
|---|---|---|
| 数学模块(math) | 包含很多科学计算方法,如平方根、对数计算、三角函数,等等 | 在数据挖掘中,经常要对数据进行标准化、求统计值等处理,math模块基本上包含了所用的基本操作 |
| 日期时间模块(datetime) | 主要用于处理时间类型的数据,如时间数据格式化、时间的获取、时间数据与字符串的转换,等等 | 数据通常都会带有时间戳,有时,时间也是一种重要的特征。如新闻中,有新闻的发生时间、发布时间等,就会用到该模块 |
| 随机模块(random) | 主要可以进行随机数的生成,随机选取 | 在进行数据采样、数据生成时经常会用到这些随机方法 |
| 文件操作模块(file) | 主要提供了文件操作,包括文件的读取和写入等,在处理本地数据时,通常都会用到这些操作 | 数据挖掘的样本通常都会被存放在文件中,所以文件操作也是基本技能之一 |
| 正则匹配模块(re) | 可以使用正则表达式来进行字符串的匹配、检测等,其编写方法可以在网上搜索一下 | 在处理文本数据时,经常需要用到正则匹配来进行文本的检索 |
| 系统接口模块(sys) | 主要实现了与操作系统交互的一些功能,如获取当前操作系统的情况、设置编码格式等,编写完整的程序通常都会用到 | 系统接口模块主要是为了获取系统的各种数据 |
第三方库
除了有应用广泛的标准库,Python的魅力之一就是拥有庞大的第三方库,代码之丰富,大大简化了大家开发的过程。这里我列出了在数据挖掘、机器学习项目中一些常用的项目库,如果你对某一个库感兴趣,想要深入学习,可以先从官网入手了解。当然,第三方库的内容远远不止这么一点,随着工作的深入,你将会接触到各种各样的第三方库,感受到什么是众人拾柴火焰高。
- 基础模块
我将给你推荐4款常用且功能强大的科学运算基础工具包,请见下表:
| 名称 | 含义 |
|---|---|
| NumPy. | Python 语言扩展程序库,支持大量的维度数组与矩阵运算。 |
| SciPy. | 集成了数学、科学和工程的计算包,它用于有效计算Numpy矩阵,使Numpy和Scipy协同工作。 |
| Matplotlib | 专门用来绘图的工具包,可以使用它来进行数据可视化。 |
| pandas | 数据分析工具包,它基于NumPy构建,纳入了大量的库和标准数据模型。 |
机器学习
机器学习常用的库也有4个,包含了基础数据挖掘、图像处理与自然语言处理常用算法。它们可以支撑日常工程中的常见算法处理方案,所以非常推荐你使用,请见下表:
| 名称 | 含义 |
|---|---|
| scikit-learn | 基于SciPy进行延伸的机器学习工具包,包含大量的机器学习算法模型,有6大基本功能:分类、回归、聚类、数据降维、模型选择和数据预处理。 |
| OpenCV | 非常庞大的图像处理库,实现了非常多的图像和视频处理方法,如图像视频加载、基础特征获取、边缘检测等,处理图像通常都需要其支持。 |
| NLTK | 比较传统的自然语言处理模块,自带很多语料,以及全面的传统自然语言处理算法,比如字符串处理、卡方检验等,非常适合自然语言入门使用。 |
| Gensim | 包含了浅层词嵌入的文本处理模块,以及常用的自然语言处理相关方法,如TF-IDF、word2vec等模型。 |
深度学习平台
这里我再介绍3个深度学习的平台,你可以根据自己的需求进行了解,请见下表:
| 平台名称 | 开发平台 | 优点 |
|---|---|---|
| TensorFlow | 谷歌 | 相对成熟、应用广泛、服务全面、提供学习视频和其认证计划。 |
| PyTorch | 支持更加快速地构建项目。 | |
| PaddlePaddle | 百度 | 中文文档全面,对于汉语的相关模型比较丰富。 |
使用任何一个框架都可以构建深度学习项目,在实际的应用中,根据自己的需要进行选择即可。
除了上面介绍的模块,还有很多相关的模块,在这里我就不-介绍了,等到具体应用时我会针对相应的算法再讲一些其他的模块。接下来,我们介绍一种模块的安装方法。
使用pip安装扩展包
pip是一个特殊的模块,可以用它来安装扩展包。使用pip可以对Python扩展包进行查找、下载、安装、卸载等。在Python 3.6中,pip已经成为一个自带的模块,如果你不确定你的Python中是否有该模块,可以执行以下命令:
升级pip到最新版,命令如下:
用pip安装扩展包,以安装TensorFlow为例,命令如下:
1 | pip install tensorflow |
用pip卸载某个模块,命令如下:
在pip库中搜索某个模块,命令如下:
用pip显示已安装的包,命令如下:
由于某些原因,使用pip自带的镜像源可能会出现让你抓狂的下载中断问题,我们可以自己配置成国内的镜像源。在安装某个模块时,如需临时切换镜像源,命令如下:
pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple
用pip更新配置文件,修改默认源,命令如下:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
常用镜像源
镜像源在数据挖掘中也比较常用,我列举了一些常用的,就不介绍了,如果你感兴趣可以去了解一下,请见下表:
由于Python方便、好用,所以在机器学习、数据挖掘领域受到了广泛的追捧。但是各种资源代码包层出不穷,更新的包多、频率快,就会出现缺少对应代码包、版本不兼容等问题,因此选择一款好用的编辑器就变得非常重要了。
为了避免不必要的问题,我为你推荐一款叫作Anaconda的软件。
什么是Anaconda
Anaconda 是包管理器,也是环境管理器,更是Python的编辑器。其致力于为用户提供最便捷的方式来使用Python,进行数据科学计算和机器学习。这个免费的软件安装起来非常方便,涵盖的源码包、工具包之多,以及适用的平台之广,使得该软件在安装、运行和升级等复杂的科学数据运算和机器学习环境方面变得极其简单。
当前流行的三个开源软件库 sklearn、TensorFlow和sciPy都支持 Anaconda,不仅如此,你还可以在网上找到该软件的免费交流论坛,随时进行讨论学习。
因为这是一个开源的工具,所以它拥有众多用户。许多数据科学运算工程都在使用Anaconda,其中不乏一些大公司的项目,例如Amazon Web Services'Machine Learning AMIs、Anaconda for Microsoft on Azure and Windows,等等。
为什么要用Anaconda
当我第一次接触到Anaconda的时候,就被它深深地吸引了,它很大程度上解决了我之前提到的Python 资源更新多且快的痛点。
- 依赖包安装方便
预装150+依赖包,提供250+可选开源依赖包,可以直接使用命令 conda install,也可以使用pip install 命令安装,非常方便。甚至可以使用 conda build 来构建你自己的依赖包,之后把它上传到anaconda cloud、PyPi或者其他的资源站上面,分享给大家使用。
- 多平台支持
在日常使用的Linux系统、Windows系统和 MacOS系统上都有对应的Anaconda版本,不管是32位还是64位都是可以的。不光如此,还有图形界面版本,对使用图形桌面系统的同学很友好
- 多环境切换
使用Anaconda 可以依据不同的项目依赖构建多套互不干扰的环境,随时切换,而不用担心各个环境之间的冲突。
不仅如此,使用Anaconda配置好的环境还可以进行打包储存,迁移项目到其他机器上的时候,只需要把打包的环境一并移到新的服务器上,就可以一键安装整个已经配置好的环境,不需要再重新建设了,非常方便。
你现在一定迫不及待地想要使用Anaconda,下面我就来介绍一下它的常用功能。
如何使用Anaconda
进入 Anaconda 的官网,根据自己的需求下载对应的Anaconda版本。

Anaconda 官网图
本课时我就以64位的Windows版本为例,给大家演示如何安装Anaconda。
安装的过程是傻瓜式的,基本上是一路“Next”和“Iagree”就可以结束了。如果你想使用命令行安装模式,那么可以选择shell命令来进行控制,也是十分简单的。
安装完成后,我们打开Anaconda的 Navigator,可以看到如下的界面。

Anaconda的界面图
这里会有一个初始化的环境base。除了环境配置以外,内部还搭载了很多实用的模块,包括Jupyter Notebook、Spyder、Qt Console等,对这些内容我就不再做详细介绍了,感兴趣的同学可以去官网了解学习。
如果我们想使用这个界面工具去创建环境,可以切换到Environments的tab页:
Environments的tab页图
你可以使用页面下方的Create按钮去创建一个新的环境,也可以用命令行的方式创建,具体操作如下:
(1)在命令行中配置Anaconda环境;
(2)在Windows中打开命令行工具CMD;
(3)使用conda创建一个环境,执行命令如下。
conda create –name python-my python=3.7
接下来就是自动安装环节,静静等待安装完成,然后来激活这个环境,命令如下:
激活之后,这些配置环境变量的内容就生效了,命令也都可以直接使用。如果要安装一些包,可以直接使用Anaconda的命令代替 pip,比如:
如果我们想要切换到其他的环境,可以使用下面的命令来注销当前环境:
完成注销之后再使用激活方法来激活新的环境。
如果你想看一下电脑上有没有其他的环境,可以使用以下命令:
在环境已激活的情况下使用conda导出已有环境,导出命令如下:
conda env export > environment.yaml
在创建环境的时候,直接使用移到其他服务器上的yaml文件即可:
conda env create -f environment.yaml
激活环境,然后打开Spyder 试试前面是否已经安装成功了,执行命令如下:
import numpy as np
import matplotlib.pyplot as plt
labels = [‘G1’, ‘G2’, ‘G3’, ‘G4’, ‘G5’]
men_means = [20, 35, 30, 35, 27]
women_means = [25, 32, 34, 20, 25]
men_std = [2, 3, 4, 1, 2]
women_std = [3, 5, 2, 3, 3]
width = 0.35
fig, ax = plt.subplots()
ax.bar(labels, men_means, width,yerr=men_std, label=’Men’)
ax.bar(labels, women_means, width, yerr=women_std, bottom=men_means,
label=’Women’)
ax.set_ylabel(‘Scores’)
ax.set_title(‘Scores by group and gender’)
ax.legend()
plt.show()
如果成功运行,将在界面右侧的输出框显示一个柱状图:
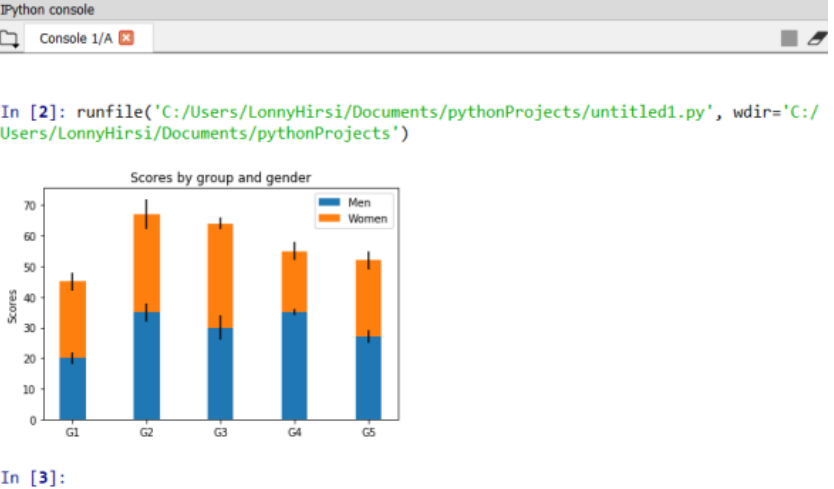
柱状图

数据挖掘的流程图
这些准备有两个方面:业务理解和数据理解。
数据挖掘是一种方法,在这个方法中虽然说技术是一个重点,但归根到底,你的方法要去解决问题,空有技术而没有问题是没办法去实施方法的。所以,在开始数据挖掘的时候,要确保你对业务及其数据有充分的理解。如果你仅仅按照自己的想法,而没有对业务与数据进行充分理解,很可能导致你的理解与业务有较大的偏差,所做出的结果与业务的需求不符合导致返工,或者是因为对数据的了解不全面导致缺乏关键数据而影响最后的结果,甚至是任务难以进行,最后项目流产。
经过这一步的准备,要明确你对于要解决的问题的所有可知信息。但是,要想真的理解业务、理解数据,我觉得还有一个更重要的,那就是思想准备,所以,在这里我把前置准备分成了三项:思想问题、业务背景与目标、把握数据。
思想问题
1.避免对业务的轻视
要做什么样的人,要先去按照那样的人去思考,而不是要先像那样的人。比如,你要健身减肥,很多人都是先去买一套健身服装、健身器材,然后办一张健身房卡,但是自己的思想并没有转变成一个健身人士的思想,那么最终健身减肥的效果也就可想而知了。所以你做数据挖掘,一定要避免这样的思想问题–我学了很多的算法,穿着程序员的衣服,背着程序员的电脑,我就是一个优秀的数据挖掘工程师了。
这个事情看起来好像很容易,很多人会说:“我当然知道业务的需求是什么样的,不然我干吗要做数据挖掘呢?”
在实际的公司组织中,有些公司的数据分析师或者算法工程师是与业务部门在一起的,而有些则是分开的。其实不管是否在同一个部门,如果数据挖掘人员没能够真正理解业务场景与挖掘需求,很有可能会与业务人员产生分歧,以至于你觉得做了很多的工作,每天都加班加点,你的挖掘项目充满了技术含量,数据充分、算法丰富、结果翔实,最后业务却不认账,说你做得不好,效果没有达到预期,做出来的东西对业务的价值不大。
轻视业务是很容易犯的问题。
我在刚做这些工作的时候也犯过不少类似的错误。一个业务方提需求,而我也没有仔细去询问业务的真正想法,按照我自己对业务的理解去做模型。最后呢,如果拿准确率这样的线下指标去看似乎效果很不错,但是放进业务去做测评却无法满足业务的需要,导致不得不推倒重做。
所以要始终牢记,数据挖掘的本质是一种方法,这个方法要去解决问题,一定要源于业务需求,服务业务需求。如果脱离具体业务去做,那做得再好、再漂亮也没有太大的价值。
如果要做一个成功的数据挖掘项目,你就要去深入学习业务,明白业务的关键点,在项目的需求阶段与业务方进行充分的沟通,在发现偏差时及时调整,甚至在制定OKR的时候也与业务方来共同制定,这样在做项目的时候才不会出现南辕北辙的问题。不要觉得你是一名技术人员,学习业务对你帮助不大。
2.明白可以为和不可以为
做技术,有一个很容易进入的误区,那就是相信“技术万能”,技术可以解决一切问题。一个业务需求来了,你明白了业务的要求以及目标,还需要明白数据挖掘要解决的点在哪里。
“技术万能”的工程师会相信数据挖掘或者说算法可以解决任何问题,对于各种各样的难题,认为只要有数据就可以解决。
然而事实上,技术在业务上绝不是万能的,甚至由于公司不同、业务不同、流程不同,所做的数据挖掘流程和数据挖掘目标也千差万别。
比如说你在做一个OTA酒店消歧的项目,在酒店业务中有一个痛点就是不同的供应商提供的酒店信息可能存在一些区别,以至于需要消耗大量的人工去做比对决策。
这个问题场景看似很符合数据挖掘的解决范畴,然而实际上却有各种各样的情况:
数据可能是残缺的导致无法使用算法处理;
不同供应商提供的同一家酒店名称可能是中文,可能是英文,甚至是日文、法文、泰文,不同语种间无法使用同样的模型来解决,而如果每一个语种都做一个模型又没有足够的数据做支撑;
不同的供应商提供的信息可能是不对等的,有的供应商会提供电话和邮件,有的则没有这个字段,然而这些对准确率影响也很大,这也无法使用一套解决方案来完全解决所有问题。
总结一下,说数据挖掘不是万能的主要有两个原因。
第一个是数据不完美。
虽然数据挖掘的理念很美好,但现实总是残酷的,完美的数据是不存在的,至少现在是不存在的。每一个公司都只是掌握了部分数据,有些甚至没有多少数据,还需要去外面爬取数据来进行处理。从总体上来看,似乎我们的数据量很大、很充足,但数据的真实性、准确性、完整性具体到每一条数据的时候或者某一个需求的时候,是不完美的,甚至是匮乏的。你要解决这些问题需要付出大量的工作,甚至超出了业务本身,这就会造成入不敷出的情况,这个项目开展的必要性可能就要受到质疑了。
第二个是业务条件不完美。
数据挖掘项目通常都是跨团队的协作项目,譬如说我带领的数据挖掘部门既不生产数据,也不存储数据,但是我们却是对数据处理应用最多的部门,这当然有赖于业务部门以及其他技术部门之间的配合和协作。
再说上面那个酒店业务的例子,如果我们投入大量的人力,比如说经过长达一年的研究和调试,当然可以产出一个效果更好的模型,甚至是直接输出结果。然而这个周期对于业务来说太久了,业务没有办法等待一年以获得一个足够好的结果。况且由于数据的限制,这一年后半段时间的努力可能只有很小幅度的提升。所以我们又跟业务进行了更深入的讨论,以更改目标,最后确定了目标是提升酒店运营人员的效率,而不是直接输出一个完整的结果。
这样我们就可以在三个月甚至是更短的时间内产出一个效果还不错,而业务也可以使用的模型方案,同时加入业务开发的一些流程,最后我们的项目降低了酒店运营60%的人力成本。
所以说,数据挖掘只能在有限的资源与条件下去提供最大化的解决方案,不要忘记我们的初衷,去解决业务需求,而不是以“技术万能”为导向,最终导致项目陷入泥潭消耗过大,甚至是项目流产,而偏离了我们解决业务问题的初心。
要避免这种问题的产生,需要与业务方进行深入的沟通,同时对你所掌握的数据有充分的认识,对业务的难点和重点有明确的区分。建立需求多方评估机制,让业务专家与技术专家参与进来,评估需求的合理性以及你的数据情况,确认问题是否可以通过数据挖掘得到有效解决;或者是对需求进行拆解,以最大化在数据限制和业务限制前提下的项目效果。
业务背景与目标
解决了上面两个想法上的误区后,要明确你的业务需求就变得相对简单了。因为你的思想已经发生了变化,你已经是一个具备业务视角的数据挖掘工程师了。
自然而然的,你在进行数据挖掘之初就要去明确业务背景和业务目标,更好地契合业务的需要。
数据挖掘是一种方法,需求的产生必然是因为某种分析需求、某个问题或者某个业务目标的需求。如果你一开始就不能对问题进行准确的定位,那么后面该如何使用合适的数据选择合适的算法,都是无稽之谈。
假设你现在是一个自媒体平台,自媒体作者会在上面发布文章,很多用户会来看这些内容,从而产生互动行为,比如说点赞、收藏、分享、评论等。这些会刺激作者继续创作,而作者持续发布好内容又会吸引更多的用户来浏览,在这个环节中,作者的贡献是一个重要的部分。
所以这里业务提出了一个需求,要对发布内容的自媒体做一个贡献度评级模型。这个目标虽然确定了,但是这个贡献度到底该如何去衡量?对于一个作者来说,他的贡献度体现在他的内容上,但是CTR(点击率)高的内容贡献度高,还是有独特观点的内容贡献度高?或是能引发讨论的内容贡献度高,还是技术深度更深的内容贡献度高?是发布内容的频率高贡献度高,还是发布的内容够长贡献度高?这里面还有很多需要思考的事情。
如果数据挖掘工程师自行去理解业务,那很可能出现偏差,和业务方的需求产生分歧。所以这时你就应该展开沟通,并成立专家小组来对目标进行评审。
在沟通的过程中了解到,我们的业务背景是在打造品牌影响力的时候,发现很多用户对我们的内容产生了质疑,因为有些作者为了提升自己的点击率,故意使用一些标题、低俗图片等手段,并且频繁地生产无意义的内容,造成了用户的反感。在这样一个背景下,你的业务方希望能够对作者形成一种分级制度,让那些写有深度、有内涵内容的作者能够被评为更高的级别,而那些标题党作者的级别则会降低。
那么接下来,我们对数据的收集就要围绕着这个点去展开了。
把握数据
在核对好需求之后,紧接着你就要对数据来进行了解,这一步有点类似可行性分析。巧妇难为无米之炊,如果你的数据无法支撑挖掘需求,那这件事也就没办法解决了。
所以作为一个数据挖掘工程师,还需要对你要用到的数据了如指掌。收集、存储、转换数据都是十分重要的环节,如果这些环节存在问题,那么整个项目的进度都会被拖慢。
在这个步骤中,你要考虑所有可以用到的数据,哪些可以用来做你的模型,可以用来回答业务的问题,哪些对这个需求来说是没有什么价值的。
数据的质量、数量、可靠性、完整性,以及部分数据缺失是否会导致模型的效果不好,某些关键数据是否会严重影响业务问题等,这些问题都是你需要搞清楚的。
从粗粒度到细粒度,你对数据的认知应该有这样几个层级。
1.是否有数据
是否有这样一个数据集来支持你做这样一个模型,来完成这样一个需求,来回答业务的问题。
2.有多少数据
光有数据还不行,还得看到底有多少数据,是一条、十条,还是一万条、一亿条,数量的不同也会影响你的处理方式。
3.是什么样的数据
亦或者说,你的数据都有哪些属性可以被用到。比如上面的例子,一条数据就是一个作者所写的一条内容、各种互动指标等信息。到了这一层,你需要考虑的是这些维度是否可以支持完成业务需求,是否与所提出的问题有关系。
4.标签
这个是针对特定的项目,比如说有监督学习任务,那么每条数据都需要有结果的标注,这也是你的模型或者算法要学习的结果。如果只有数据,而没有对应的标签标注,那机器学习也是比较困难的。
确认了这些数据的问题后,你才可以说对数据有了初步的了解,接下来,可以按部就班地进行下一步:准备数据了。
看完了这一课时的内容后,不知道你是不是改变了对数据挖掘的看法?想想自己做的业务需求是什么样子的,你是否能做好对应的准备呢?如果你是业务方,那又该如何跟工程师做好沟通呢?
总结
这一课时讲解了数据挖掘步骤的第一步,如果用一个词来总结的话,那就是“做好准备”。这里所讲的准备分成三个方面:
思想准备,确保自己已经具备了一个专业的数据挖掘工程师的思维模式;
理解业务,确保与业务需求方的充分沟通,对业务需求的充分理解,知道什么可以做,什么不可以做;
理解数据,确保对可以掌握的数据有全面的了解,知道哪些数据有用,哪些数据没用。
准备数据
在对业务和数据有了清醒的认识之后,你就要开始收集、处理数据了。这个环节看起来好像是一个非核心环节,实际上在整个过程中却是最重要、最耗时的环节。
就如2008年北京奥运会的成功离不开城市规划、场馆建设、志愿者招募等一系列准备工作一样,数据准备在数据挖掘中同样也承担着这样一个重要的角色。原始的数据通常不可能跟你的算法所适配,而且其本身也存在着各种各样的问题,如不够准确、格式多样、部分特征缺失、标准不统一、特殊数据、错误数据等,这些问题都将在一定程度上影响你后续算法模型的训练和实施。
为了避免上述麻烦,我将带你一步步避坑,准备出合适模型的数据。
找到数据
在一个公司中,数据往往会有很多的存在形式,比如它们所属的业务部门不一样,使用的数据库类型就可能不一样,存储数据的方式也有可能不一样等问题。所以,对于你要做的项目来说,就可能需要很多不同来源的数据。你要知道每个项目需要什么数据,并从哪里获取。尽管在一些大的公司存在数据平台部门、数据仓库部门,但这仍然不能保证你所需要的数据只用一种方法就能获取到。所以在这一步,可能需要你掌握一些数据库的使用技巧,如常用的关系型数据库MySQL、大数据使用的Hbase、Hive、搜索引擎数据库ES、内存数据库Redis,还有图数据库,如Neo4j或者JanusGraph等,甚至还要跟各种业务部门沟通协商以获取数据。数据库的内容我就不在本课时中-一介绍了,如果感兴趣你可以去官网深入了解。
当你从各种地方收集到所需要的数据之后,最好是能够把它们进行简单的整理,如用统一的id把数据整合在一起等,以便后面查询和使用。
准备好需要的数据后,就要对它们进行一系列的加工,从而达到后期训练模型的要求。
数据探索
在该阶段,为了尽可能获得足够多的特征,你要对数据进行分析、预处理以及转换等基础工作,以构建出更加贴合你所要预测结果的特征,这使得数据维度大量扩展,所以我把这个环节叫作把数据变多或者数据升维。
假设你要做一个给新闻内容分类的项目,已经从数据仓获取了新闻内容、新闻标题、新闻发布时间等数据,并从运营部门获得了运营给这些新闻标注的分类数据。这时候你要做的就是把数据变多,可以进行如下操作:
把内容进行分词,这样就获得了一个分词后的字段;
把分词后的内容进行词语的统计,看看哪个词出现得更多;
同样地把标题进行分词,进行词语的统计;
还可以对词语的词性进行标注,获得一份词性数据;
你可以找到一些特殊的词,比如名人的名字、机构的名字、地点的名字等一些信息。
通过这些处理,可以看到你的数据是否存在问题,比如异常值、数据的偏差、缺失,等等。如果是数值型的数据,还可以通过计算均值、方差、中位数、标准差、最大值、最小值等去探索、扩展。
有了足够多的数据,接下来就要对其进行整理,提取对项目最有用的部分。
数据清洗
终于讲到了这个,在整个数据准备,甚至是整个数据挖掘过程中,最烦琐、最头疼的步骤-一数据清洗。如同你打扫卫生时,会把不需要的东西扔掉,需要的东西留下来摆放整齐一样,数据清洗步骤就是要做这样一个工作,处理扩展后的数据、解决所发现的问题,同时又要顾及处理后的数据是否适合应用于下一个步骤,所以我也把这一步骤称作把数据变少。
数据清洗主要包含如下5个方面的内容:
1.缺失值的处理
在美好的童话世界中,我们的数据都是完完整整的,拿来即用。实际上,在工作中最常见的一个问题就是数据的缺失,比如一条新闻可能只有正文没有标题、发布地点、发布时间等任意数据。你需要区分这些数据缺失的情况,因为有些是业务所允许的缺失,而有些则是错误情况导致的。通过分析,了解数据缺失的原因以及数据缺失的影响范围,这会关系到你后面如何来处理缺失值。
关于缺失值的处理,一般就3种情况:删掉有缺失值的数据;补充缺失值;不做处理。当然这些处理方式也依赖于数据是否可以被补充、缺失值是否重要,以及你所选用的算法能否处理缺失的情况等因素。
2.异常值的处理
异常值通常说的是那些与样本空间中绝大多数数据分布差距过大的数据,这些数据的产生通常有2种情况:
错误的情况,比如医院录入病人病历的时候,忘了给数字输入小数点,导致某个人的身高显示为173米,等等;
正常的情况,就需要重视了。比如在平均充值为100元的游戏中,有人充了100万元,这是一个真实的结果,但是如果直接使用到模型中可能会影响到平均值的计算,影响模型训练的效果;再比如只有1000万在线用户的App,突然拥有十亿的在线用户,这就有可能是应用网络受到了攻击,等等。
不同情况的异常值有不同的处理办法:
数据本身的错误,需要对数据进行修正,或者直接丢弃;
数据是正确的,需要根据你的业务需求进行处理。如果你的目标就是发现异常情况,那么这种异常值就需要保留下来,甚至需要特别关照。如果你的目标跟这些异常值没有关系,那么可以对这些异常值做一些修正,比如限定最大值和最小值的标准等,从而防止这些数据影响你后面模型的效果。
3.数据偏差的处理
这也是非常常见的问题。没有什么数据是非常对等和均衡的,越是天然的数据越是符合正态分布的规律。比如UGC内容(User Generated Content,用户生成内容)的质量,质量较差的内容占大多数,质量好的占少数,质量非常好的是少之又少。这是一种正常的现象,但是对于算法模型来说,有些算法会倾向于预测占比较大的数据,比如说质量好的内容只占2%,而质量差的内容占到了98%,模型倾向于给出质量差的结果。如果给出所有的结果都是“差”,那该模型的准确率也能达到98%了,可这并不是我们想要的结果。
数据偏差可能导致后面训练的模型过拟合或者欠拟合,所以处理数据偏差问题也是你在数据清洗阶段需要考虑的。如果你需要比较均衡的样本,那么通常可以考虑丢弃较多的数据,或者补充较少的数据。在补充较少的数据时,又可以考虑使用现有数据去合成一些数据,或者直接复制一些数据从而增加样本数量。当然了,每一种方案都有它的优点和缺点,具体的情况还是要根据目标来决定,哪个对目标结果的影响较小就采取哪种方案。
4.数据标准化
在处理完数据的问题之后,你就该对数据的标准进行整理了,这可以防止某个维度的数据因为数值的差异,而对结果产生较大的影响。在有些算法中,每一个维度的数据标准都需要进行统一;而在另外一些算法中,则需要统一数据的类型。比如在预测一个地区的房价时,房屋的面积可能是几十到几百的数值范围,房屋的房间数可能是个位数,而地区平均单价可能是以万为单位的。一个处理方法是你把这些维
度的数据都进行标准化,比如把这些数据都规范到0~1的区间,这样使用不同的单位来衡量的数据就变得一致了。
5.特征选择
特征选择就是尽可能留下较少的数据维度,而又可以不降低模型训练的效果。一个项目中,数据的维度可能会有成百上千,比如一个文本中,每一个词或者每一个字都是一个维度,那么要用一个向量去表示一篇文章,这个向量可能需要有上万个维度,所以你要排除掉那些不重要的部分,把重要的部分保留下来。
也许你会认为数据的维度越多越好,但实际上,维度越多,数据就会越稀疏,模型的可解释性就会变差、可信度降低。过多维度还会造成运算的缓慢,尤其是一些运算量较大的算法,同时那些多余的维度可能会对模型的结果产生不好的影响,如某个维度的数据跟结果实际上并没有什么关系,数据也呈现出一种随机的情况,如果没有把这部分数据排除掉,就可能会对某些算法产生影响。
这个时候就需要用到特征选择的技巧,比如自然语言处理里的关键词提取,或者去掉屏蔽词,以减少不必要的数据维度。对于数值型的数据,可以使用主成分分析等算法来进行特征选择,如果你对这部分内容有兴趣,可以在网上找一些资料进行更深入的学习。
构建训练集与测试集
在数据进入模型之前,你还需要对其进行数据采样处理。如果说前面的部分是为了给模型提供一个好的学习内容,那么数据采样环节则是为了评估模型的学习效果。
在训练之前,你要把数据分成训练集和测试集,有些还会有验证集。
如果是均衡的数据,即各个分类的数据量基本一致,可以直接随机抽取一定比例的数据作为训练样本,另外一部分作为测试样本。
如果是非均衡的数据,比如在风控型挖掘项目中,风险类数据一般远远少于普通型数据,这时候使用分层抽样以保障每种类型的数据都可以出现在训练集和测试集中。
当然,训练集和测试集的构建也是有方法的,比如:
留出法,就是直接把整个数据集划分为两个互斥的部分,使得训练集和测试集互不干扰,这个是最简单的方法,适合大多数场景;
交叉验证法,先把数据集划分成n个小的数据集,每次使用n-1个数据集作为训练集,剩下的作为测试集进行n次训练,这种方法主要是为了训练多个模型以降低单个模型的随机性;
自助法,通过重复抽样构建数据集,通常在小数据集的情况下非常适用。
思想准备
准备数据可能是数据挖掘所有环节中,最苦、最累、耗时最长的一环了。由于实际生产中的数据,会存在各种各样的问题,一如我上面说的,数据缺失、异常、偏差等,而对于数据的准备其实没有一个统一的标准算法去解决。所以在这个环节,一定要保持认真仔细的态度以及平和的心态,做好数据准备工作是获得一个好结果的必由之路。
准备数据不是独立存在的过程。不是说,你一次性做完数据准备工作就结束了,后面的模型训练和模型评估环节与数据准备紧密相关,当你的模型出现错误,结果达不到预期,往往需要重新回到数据准备环节进行处理,反复迭代几次最终才能达到你期望的目标。
模型训练
在上一课时,我们解决了一系列又脏又累的数据问题,现在终于可以进入模型训练阶段了。
在数据挖掘中,算法是很多的,而且随着大家研究的深入,有越来越多的优秀算法被设计出来。所以,该怎么去选一个适合需求的算法呢?首先你得明白你面对的是什么问题,虽然算法众多,但是要解决的难题往往有共同点,针对每一类型的问题,就可以找到对应的算法,再根据算法的特性去进行选择。这一课时,我就来介绍一下在工作中最常遇到的一些问题。
分类问题
在内容理解场景下,我遇到最多的问题就是分类问题。一个用户写了一篇游记,我想对它做非常详细的理解,比如:
游记类别,是关于“滑雪”的,还是关于“徒步”的;
用户情感,是“正向”的,还是“负向”的;
内容质量,是“高”“中”,还是“低”;
内容风险,是“有风险”的,还是“无风险”的。
诸如此类给数据进行明确标签区分的问题都可以看作分类问题。
分类是有监督的学习过程。处理分类问题首先要有一批已经有标签结果的数据,经过分类算法的学习,就可以预测新的未知数据的分类。如果缺少这些已知的信息,那分类就没办法进行,要么考虑使用其他方法,如聚类算法,要么考虑处理数据,比如说人工进行标注。
分类问题中包括以下3种情况:
二分类。这是分类问题里最简单的一种,因为要回答的问题只有“是”或“否”。比如我在处理用户内容时,首先要做一个较大的分类判断,即一条内容是否属于旅游相关内容,这就是二分类问题,得出的结论是这条内容要么是旅游相关,要么不是旅游相关。
多分类。在二分类的基础上,将标签可选范围扩大。要给一条内容标注它的玩法,那种类就多了,比如冲浪、滑雪、自驾、徒步、看展等,其种类甚至多达成百上千个标签。
多标签分类。是在多分类基础上再升级的方法。对于二分类和多分类,一条内容最后的结果只有一个,标签之间是互斥的关系。但是多标签分类下的一条数据可以被标注上多个标签。比如一个人在游记里既可以写玩法,也可以写美食,这两者并不冲突。
由于分类问题众多,所以用来解决分类问题的算法也非常多,像KNN算法、决策树算法、随机森林、SVM等都是为解决分类问题设计的。看到这些名字你可能会感到陌生,但是不要担心,关于算法的具体细节,我会在后面的课时进行讲解。
聚类问题
跟分类不同,聚类是无监督的,也就是说没有已经标注好的结果数据供算法学习。你只知道一些数据,而且你需要为这些数据分组,甚至很多时候你连要划分多少个组都不清楚。比如,在一个旅游APP上有上千万的用户,你可能会需要把用户划分成若干个组,以便针对特定的用户群体去开发一些特定的功能,比如为爱滑雪的用户,推送一些滑雪的信息。但是用户数量很大,用户的属性也很多,这个时候你就要用到聚类分析。
聚类就是把一个数据集划分成多个组的过程,使得组内的数据尽量高度集中,而和其他组的数据之间尽量远离。这种方法是针对已有的数据进行划分,不涉及未知的数据。
既然是要划分小组,就要先看看小组之间可能存在的4种情况。
互斥:小组和小组之间是没有交集的,也就是说一个用户只存在于一个小组中。
相交:小组和小组之间有交集,那么一条数据可能既存在于A组,也存在于B组之中,如一个用户既可以爱滑雪,也可以爱爬山。
层次:一个大组还可以细分成若干个小组,比如将高消费用户继续细分,可以有累积高消费用户和单次高消费用户。
模糊:一个用户并不绝对属于某个小组,只是用概率来表示他和某个小组的关系。假设有五个小组,那么他属于这五个小组的模糊关系就是[0.5,0.5,0.4,0.2,0.7]。
所以,对应上面4种不同的小组情况,也有4种不同的聚类方法。
第一种:基于划分的聚类,通常用于互斥的小组。划分的方法就好像在数据之间画几条线,把数据分成几个小组。想象你的数据散落在一个二维平面上,你要把数据划分成三个类,那么在划分完之后,所有数据都会属于一个类别。
第二种:基于密度的聚类,可以用来解决数据形状不均匀的情况。有些数据集分布并不均匀,而是呈现不规则的形状,而且组和组之间有一片空白区域,这个时候用划分的方法就很难处理,但是基于密度的聚类不会受到分布形状的影响,只是根据数据的紧密程度去聚类。
第三种:基于层级的聚类,适用于需要对数据细分的情况。就像前面说的要把数据按照层次进行分组,可以使用自顶向下的方法,使得全部数据只有一个组,然后再分裂成更小的组,直到满足你的要求。如有从属关系,需要细分的数据,就非常适合这种方法。同样,也可以使用自底向上的方法,最开始每一条数据都是一个组,然后把离得近的组合并起来,直到满足条件。
最后一种:基于模型的聚类。这种聚类方法首先假设我们的数据符合某种概率分布模型,比如说高斯分布或者正态分布,那么对于每一种类别都会有一个分布曲线,然后按照这个概率分布对数据进行聚类,从而获得模糊聚类的关系。
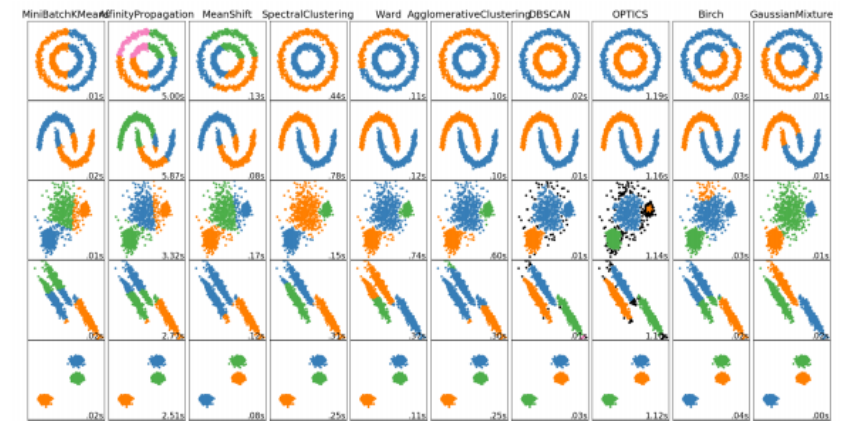
下面是我在scikit-learn官网上找的一张聚类算法对比图,通过数据图形化的形式,对比了针对不同类型的数据情况,使用各个聚类算法得到的结果。图中的每一行都是同一种数据通过不同算法得出的聚类结果,不同颜色表示使用了某个聚类算法之后,该数据集被聚成的类别情况,可以比较直观地理解某个算法适合什么样的数据集。比如第一行的数据分布是两个圆环,可以看到第四个、第六个、第七个和第八个算法的效果比较好,能够成功地按照两个圆环去聚成类别,而其他几种的效果就比较差了。
聚类算法对比图
回归问题
与分类问题十分相似,都是根据已知的数据去学习,然后为新的数据进行预测。但是不同的是,分类方法输出的是离散的标签,回归方法输出的结果是连续值。
那什么是离散的标签呢?“云青青欲雨”这个典型的分类问题,就能说明这一问题。根据特征“云青青”输出“雨”,雨、雪、阴、晴这类标签,就是不连续的。而回归就是要通过拟合数据找到一个函数,当你有一组新的数据时,就可以根据这个函数算出一个新的结果值。
回归的英文单词是Regression,有消退、复原的含义,这种方法是由生物统计学家高尔顿发明的。他在统计父母身高与子女身高的关系时发现,父母的身高都非常高或者都非常矮的情况下,子女身高经常出现衰退的情况,也就是高的父母孩子变矮,矮的父母孩子变高,有回归到平均身高的倾向。
我画了两幅图来说明回归的结果,就是要找到一条线:


回归分析图
这张图不是要进行对比,只是想告诉你不管是线性还是非线性的数据,都可以使用回归分析。
可以看到,数据散落在坐标系上,通过学习你可以得到一条线,较好地拟合了这些数据。这条线可能不通过任何一个数据点,而是使得所有数据点到这条线的距离都是最短的,或者说是损失最小的。根据这条线,如果给出一个新的x,那么你就能算出对应的y是多少。
事实上,回归方法和分类方法可以相互转化,比如:
在使用回归方法得到函数方程式以后,你可以根据对新数据运算的结果进行区间分段,高于某个阈值给定一个标签,低于该阈值给定另外一个标签。比如你使用回归方法预测完房价之后,不想让客户看到真实的房价,而是给予一个范围的感受,就可以设定高于500w的就是“高房价”标签,低于100w的就是“低房价”标签;
相反,对于通过分类方法得到的标签,你可以根据给定标签的概率值为其增加一些运算逻辑,将标签转换到一个连续值的结果上。
下面我再用一个表格总结一下分类和回归的情况,你在实际使用时可以根据自己的需要进行选择和处理。
分类问题和回归问题总结表
| 分类 | 回归 | |
|---|---|---|
| 输出 | 离散数据 | 连续数据 |
| 目的 | 寻找决策边界 | 找到最优拟合 |
关联问题
关联问题对应的方法就是关联分析。这是一种无监督学习,它的目标是挖掘隐藏在数据中的关联模式并加以利用。与分类和回归不同,关联分析是要在已有的数据中寻找出数据的相关关系,以期望能够使用这些规则去提升效率和业绩。比如在我们津津乐道的啤酒与尿布的故事中,通过分析销售产品的情况发现,很多购买尿不湿的人也会去买啤酒。你可能不知道这到底是出于什么原因,但是这背后却隐藏着巨大的经济效益,这个案例我会在后面的课时具体分析。
所以,关联分析被广泛地用于各种商品销售分析、相关推荐系统分析、用户行为分析等情况。比如我在第一课时中举的京东套装推荐的例子,就是利用这样的挖掘方法得到的结果,给用户进行各种套装推荐、搭配商品销售、特价组合等。但是在进行大量数据的关联分析时,你会发现各种奇怪的组合,这可能是数据偏差产生的影响,所以在最终结果应用的时候还需要加入一些知识校验。
说到这里,我已经把四大问题都介绍完了,每个问题都可以通过相应的机器学习算法来进行解决。但是,在实践的时候,很多问题不是靠一个算法、一个模型就能解决的,往往要针对具体的细节使用多个模型以获得最佳效果,所以就要用到模型集成。
模型集成
模型集成也可以叫作集成学习,其思路就是去合并多个模型来提升整体的效果。
既然是要合并多个模型,那么很容易想到训练多个并列的模型,或者串行地训练多个模型。下面我就来讲一下模型集成的3种方式。
- Bagging(装袋法):比如多次随机抽样构建训练集,每构建一次,就训练一个模型,最后对多个模型的结果附加一层决策,使用平均结果作为最终结果。随机森林算法就运用了该方法,这种算法我会在后面的课时具体介绍。这一方法的过程如下图所示:

装袋法图
- Boosting(增强法):这个就是串行的训练,即每次把上一次训练的结果也作为一个特征,不断地强化学习的效果。

增强法图
- Stacking(堆叠法):这个方法比较宽泛,它对前面两种方法进行了扩展,训练的多个模型既可以进行横向扩展,也可以进行串行增强,最终再使用分类或者回归的方法把前面模型的结果进行整合。其中的每一个模型可以使用不同的算法,对于结构也没有特定的规则,真正是“黑猫白猫,抓住老鼠就是好猫”。所以,在使用堆叠法时,就需要你在具体业务场景中不断地去进行尝试和优化,以达到最佳效果。
模型评估
在每次训练一个模型之后,尤其是现在的深度模型,通常要消耗大量的时间等待模型的产出,那种心情是可想而知的,谁都希望能够有一个好的结果。模型评估就是对你的模型进行多种维度的评估,来确认你的模型是否可以放到线上去使用。
这一课时,我将介绍一些常用的评估指标,其中会涉及一些比较难理解的名词和计算,不过不用担心,我会带你逐个突破难关。当然,我也准备了一个关于“训练一个小猪图片分类模型”的例子,让你能够更加直观地理解如何去评估模型。好了,我们先来看看这个例子。
假设我们训练了一个“识别图片是不是关于小猪”的分类模型,这是一个二分类器,当你给它一张图片的时候,它会告诉你这是一张小猪的图片,或者不是一张小猪的图片。我们有1000张图片用于测试该模型的效果,并且预先已经进行了人工的标注(这里假设人工标注的数据都是100%正确),每张图都会标注是或者不是小猪的图片,假设有800张标注“是”,200张标注“否”。
评估指标
混淆矩阵与准确率指标
准确率相关指标是在模型评估时最受关注的指标,它可以直接反映一个模型对于样本数据的学习情况,是一种标准化的检验。就像老师教给你10道计算题,然后又用这10道题来出考题,如果你都答对了,说明你已经学会了。准确率相关的指标就反映了这样一种结果,下面看看模型学习的直接效果。
我们把这1000张图放进分类器进行分类计算,每张图都会得到一个预测结果,通过对预测结果的统计可以知道,被模型预测为“是”的图片有770张,被模型预测为“否”的图片有230张。这个时候每张图上会有两个结果:一个人工标注结果、一个模型预测结果。根据这两个数据的统计,可以得到一个混淆矩阵:
| 样本1000份 | 模型预测:是 | 模型预测:否 |
|---|---|---|
| 人工标注:是 | 745 (TP) | 55 (FN) |
| 人工标注:否 | 25 (FP) | 175 (TN) |
矩阵中包含以下4种数值:
真阳性(True Positive,TP):小猪图被判定为小猪图。样本的真实类别是正例,并且模型预测的结果也是正例(在本案例中此数值为745)。
真阴性(True Negative,TN):不是小猪图被判定为不是小猪图。样本的真实类别是负例,并且模型将其预测成为负例(在本案例中此数值为175)。
假阳性(False Positive,FP):不是小猪图被判定为小猪图。样本的真实类别是负例,但是模型将其预测成为正例(在本案例中此数值为25)。
假阴性(False Negative,FN):小猪图被判定为不是小猪图。样本的真实类别是正例,但是模型将其预测成为负例(在本案例中此数值为55)。
根据上述混淆矩阵,我们可以计算一些数值。
准确率(Accuracy):是指所有预测正确的占全部样本的概率,即小猪图被预测成小猪,以及不是小猪被预测成不是小猪的结果,与所有图片的比值,公式为(TP+TN)/(TP+FP+FN+TN),在本案例中为(745+175)/(745+175+25+55)=0.92。
精确率(Precision):指的是预测正确的结果占所有预测成“是”的概率,即TP/(TP+FP)。精确率按照类别来计算,比如说对于“是小猪图”这个类别的精确率是745/(745+25)≈0.9675。
召回率(Recall):按照类别来区分,某个类别结果的召回率即该类别下预测正确的结果占该类别所有数据的概率,即TP/(TP+FN),在本案例中“是”类别召回率745/(74+55)=0.93。
F值(FScore):基于精确率和召回率的一个综合指标,是精确率和召回率的调和平均值。一般的计算方法是2(PrecisionRecall)/(Precision+Recall)。如果一个模型的准确率为0,召回率为1,那么F值仍然为0。
ROC曲线和AUC值:这个略微有点复杂,但也是一个非常常用的指标。仍然是基于混淆矩阵,但不同的是这个对指标进行了细化,构建了很多组混淆矩阵。
具体是怎么构建混淆矩阵的呢?仍然以这个小猪图分类为例,在有些模型的产出中,通常给出“是”和“否”的概率值(这两个概率值相加为1),我们根据概率值来判定最终的结果,那么这时就有个问题了,我们选多少概率值来判定结果?比如可以指定“是”的概率为0.1及以上时,就判定结果为“是”;“是”的概率小于0.1的时候,判定结果为“否”。那么,选定若干组判定的概率,就能得到若干组混淆矩阵。
那么在每一组混淆矩阵中,我们获取两个值:真正例率和假正例率。
真正例率:TP/(TP+FN)
假正例率:FP/(FP+TN)
使用这两个值在坐标系上画出一系列的点,纵坐标是真正例率,横坐标是假正例率,把这些点连起来形成的曲线就是ROC曲线(Receiver Operating Characteristic,接收者操作特征)。ROC曲线下方的面积是AUC值(Area Under Curve,曲线下面积),ROC曲线和AUC值可以反映一个模型的稳定性,当ROC曲线接近对角线时,说明模型输出很不稳定,模型就越不准确。

ROC曲线和AUC值图
十分重要的业务抽样评估
除了上面一系列的指标评估,我们还有一项重要的评估需要进行,那就是业务抽样。因为我们的模型是基于业务制定的,最终的效果还是要回归到业务上。
在理想的状况下,使用上面的指标基本可以判定模型的效果,但是在实际中还存在着一些问题,这通常都是由数据本身并不完美导致的。对于标注数据,人工标注通常也存在一定的错误率,而不是100%正确,所以在使用前面的指标进行评估的时候可能会与实际结果存在一些差异。进行业务抽样评估可以减弱这种情况,在多方背靠背评估之后再进行意见的统一,最终得到一个在业务上认可的准确率情况。
泛化能力评估
除了要求模型的准确情况,还有一项重要的能力也是我们非常重视的,那就是模型的泛化能力。泛化能力反映的是模型对未知数据的判断能力,就好像学生具备举一反三的能力,老师教了1+1=2.1+2=3,考试时出了一道1+1+1=3也能够计算正确,这就有良好的泛化能力。因为在数据挖掘中,数据的维度通常有很多,而且数据也都是非标准值,任意记录之间的数据都会存在着差异,所以泛化能力好的模型在数据存在着波动的情况下,仍然能够做出正确的判断。
- 过拟合与欠拟合
我们通过两个指标可以评估模型的泛化能力是好还是坏,那就是过拟合(overfitting)和欠拟合(underfitting)。
过拟合:模型在训练集上表现良好,而在测试集或者验证集上表现不佳。这就是说,模型对样本学习有些过度了,已经进入了死记硬背的程度,而不是掌握了普适规律,这个时候可以说泛化能力比较差。
欠拟合:在训练集和测试集上的表现都不好。这就是说模型连最基本的内容都没有学到,比如老师教你1+1=2、1+2=3,考试也考1+1=2,结果还是做错了。
下面我们再来看看小猪的例子。
通常情况下,我们的小猪图都像左侧一样,右侧有两张图,上面一张可以看出仍然是小猪图,但是后背上的线条有一个缺口,如果此时模型告诉我们,这个后背上有个缺口,这不是小猪图,那么这时就出现了过拟合(判断条件过于苛刻)。右下侧是一张小羊图,如果模型告诉我们这个也有四条腿,这个是小猪,那就是欠拟合(特征学习不完全)。

小猪例子图
关于泛化性能的评估,主要依赖于在不同的数据集上的准确结果之间的比较。要处理过拟合和欠拟合的问题,通常需要对我们的数据进行重新整理,总结出现过拟合和欠拟合的原因,比如是否数据量太少、数据维度不够丰富、数据本身的准确性较差等,然后调整数据重新进行训练。
其他评估指标
除了上述的两大类指标,还可以从以下几个方面来对模型进行评估。
模型速度:主要评估模型在处理数据上的开销和时间。这个主要是基于在实际生产中的考虑,由于模型的应用在不同的平台、不同的机器会有不同的响应速度,这直接影响了模型是否可以直接上线使用,关于更多模型速度相关的问题,我们将在下一课时模型应用中介绍。
鲁棒性:主要考虑在出现错误数据或者异常数据甚至~是~数据缺失时,模型是否可以给出正确的结果,甚至是否可以给出结果,会不会导致模型运算的崩溃。
可解释性:随着机器 学习算法越来越复杂,尤其是在深度学习中,模型的可解释性越来越成为一个问题。由于在很多场景下(比如金融风控),需要给出一个让人信服的理由,所以可解释性也是算法研究的一大重点。
评估数据的处理
关于数据集的处理,重点目标在于消减评估时可能出现的随机误差。在前面准备数据的课时内容中已经提过,这里我们再对一些方案详细介绍一下。
随机抽样:即最简单的一次性处理,把数据分成训练集与测试集,使用测试集对模型进行测试,得到各种准确率指标。
随机多次抽样:在随机抽样的基础上,进行n次随机抽样,这样可以得到n组测试集,使用n组测试集分别对模型进行测试,那么可以得到n组准确率指标,使用这n组的平均值作为最终结果。
交叉验证:交叉验证与随机抽样的区别是,交叉验证需要训练多个模型。譬如,k折交叉验证,即把原始数据分为k份,每次选取其中的一份作为测试集,其他的作为训练集训练一个模型,这样会得到k个模型,计算这k个模型结果作为整体获得的准确率。
自助法:自助法也借助了随机抽样和交叉验证的思想,先随机有放回地抽取样本,构建一个训练集,对比原始样本集和该训练集,把训练集中未出现的内容整理成为测试集。重复这个过程k 次、构建出k组数据、训练k个模型,计算这k个模型结果作为整体获得的准确率,该方法比较适用于样本较少的情况。
总结
在这里需要说明的是,这一课时我们所介绍的模型评估方法中,主要适用于分类模型,因为分类模型是一种有监督模型,所以通过指标来进行评测相对容易。对于无监督模型,由于本身没有非常明确的结果标准,所以也比较难找到一个衡量指标。
模型应用
在经过了与业务方多次沟通和迭代后,模型的效果终于获得了大家的一致认可,我们的模型进入了生产待命的状态,即将迎来曙光。不过需要注意的一点就是,我们的目标是业务需求,而数据挖掘产出的结果,不管是预测型的还是关联型的,都要结合业务场景,融入业务流程中去。
模型部署
我们的业务形态不同,部署的方案也就不同。你的模型可能独立部署成服务运行,也可能嵌入到其他的项目代码中去,但是都逃不脱一个本质,那就是回归业务。所以,在这个阶段,我们就要考虑具体的业务场景了:模型如何保存?如何根据业务需求优化?以及如何最终上线服务?下面为大家详细解答。
模型的保存
在有了优秀的模型之后,首先就是要把它保存好,以方便应用。我们要给它定义一个好的名字,甚至需要维护一个详细的文档来记录模型所使用的算法、训练数据、评估结果等信息。因为在整个过程中会进行很多次训练,产生很多的模型,或者要把很多的模型组合在生产中使用,同时还需要跟后面的重新训练进行效果的对比,有时候模型的训练和部署可能由不同的人来实施,如果保存时没有注意到这些问题,很有可能导致出现混乱的情况。
所以我们要制定好模型保存的规范,包括存放的位置、名字的定义、模型所使用的算法、参数、数据、效果等内容,防止发生比如遗忘、丢失、误删除,甚至是服务器崩坏等人为的事故,造成不必要的损失。
模型的优化
在模型训练阶段已经讲了一部分模型优化或者说提升效果的方法,为什么这里又出现了模型的优化呢?这主要是因为在模型部署应用阶段的很多限制条件在模型训练阶段并不会显现出来,模型训练阶段优化所追求的目标是效果要尽量好;而在模型应用阶段优化所追求的目标是在效果尽量不降低的前提下,适配应用的限制。
比如,在对时延要求比较高的场景下,如果业务应用无法忍受模型的响应时间,那么我们就需要想办法解决,是增加机器还是降低模型的复杂度以提高速度;还有,在对模型大小要求比较高的场景下,我们期望把人脸识别模型部署到一个摄像装置的小型存储芯片上面,那么模型的大小就会受到限制,需要考虑降低模型的参数维度等。
离线应用还是在线应用?
想想我们的业务需求,如果是要使用新闻分类的类别标签结果,实时分发到用户App中,那我们的分类模型就需要部署成在线的应用服务以实时响应新的内容请求。如果我们只是需要对一批已有的新闻数据进行分类处理,而之后只是使用这些结果而不会新增新闻内容,那我们的模型就可以离线运行,把存储的新闻处理完就可以了,或者是每隔一段时间去处理一下新的数据。
这里我主要来说一下在线应用。随着算力和业务需求的不断提升,~在~公司里有越来越多的在线服务需要数据挖掘模型的支撑。这里我画了一幅可能的服务架构:

在通常的业务中,有很多客户端在发起请求,我们要在不同的服务器或者Docker中部署多个环境及模型,然后使用Web框架和HTTP服务响应请求,当然中间还有一层负载均衡去处理请求负载转发,以平均服务器的压力。
一个方案
通常算法工程师或者数据挖掘工程师都忙于解决模型问题,到了模型部署阶段就头疼不已,尤其是需要大规模并行的线上服务,可能会耗费很多时间。我在这里介绍一个简单的部署方案,希望能够为大家节约一点时间。
Flask Web 框架:在日常的任务中可以使用Flask作为构建我们的Web服务框架,它是用Python来实现的。
Gunicorn HTTP 服务:可以理解成HTTP服务器,需要注意的是Gunicorn 只能运行在Linux 服务器上面。
Nginx 负载均衡:Nginx是一个功能很强大的Web服务项目,它可以用作负载均衡器,很多大公司都在使用。负载均衡用于通过集群中的多个服务器或实例将工作负载进行分布,目的是避免任何单一资源发生过载,进而将响应时间最小化、程序吞吐量最大化。在上图中,负载均衡器是面向客户端的实体,会把来自客户端的所有请求分配到集群中的多台服务器上。
客户端:业务的具体场景,可能是手机App,也可能是其他服务器应用,客户端会向托管用于模型预测的架构服务器发送请求。比如今日头条App页面下拉,将会调用推荐算法模型进行推荐内容的计算。
当然,这里的方案并不是唯一的,在实际的工作中也有很多其他的工具具备同样的功能,可以根据自己环境和需求灵活选用。如果是在一些大公司,这些环节可能甚至不需要你考虑,会有一些成熟的平台项目来帮你实施算法模块,不过了解一下对自己也有帮助。
项目总结
记录项目经历,学会总结和反思
在项目部署上线之后,我们的项目算是告一小小的段落了,但是不要忘了对我们的工作进行总结,整理一下文档。总结的内容包括:从项目的需求发起,到数据准备,再到模型训练、评估、上线,这些环节都遇到了什么样的问题,我们解决了什么问题,又有哪些问题尚未解决,如果在时间等条件充裕的情况下还可以做哪些尝试。同时认真地做一下反思,把整个项目中的重点知识内化成自己的能力。
良好的项目总结文档会带给我们很多便利,方便我们在项目迭代时查阅,同时也是对自己工作的总结,在做过很多项目之后,这些积累将成为你宝贵的经验与财富。
多考虑一点,如何适合更多场景
当你完成了一个又一个需求之后,会发现很多需求似曾相识,但是又总有不一样的点。所以我们的数据挖掘模型或结果能不能做成统一的服务,能不能应用在更多的地方?比如,我们在做标签系统之初,业务A有一个分类标签的需求,业务B有一个分类标签的需求,业务C有一个分类标签的需求,那我们就要一个一个地去做,A模型给A用,B模型给B用,C模型给C用。但是过了不久又有D来提一个
类似AB的需求,所以我们就开始规划一个面向全公司更底层的标签体系架构,以应对各种类似的业务。多考虑一点就可以把数据挖掘前置到业务需求之前,最终形成完整的业务数据闭环,而不需要再进行冗余的开发。
监控与迭代
模型终于部署上线,但这不是说我们的数据挖掘工作就已经结束了。如今社会变动的速度也十分迅速,我们已经做好的模型很可能在经过一段时间的运行之后就不再符合当前的线上情况了,有可能我们的产品形态、业务需求发生了变化,这在互联网公司再正常不过了。为了我们的模型保持良好的效果,需要有一份迭代计划去维护和更新我们的模型。
模型的监控
要了解什么时候该做出调整,我们需要有一套监控的策略。这里所说的模型监控不仅仅是对服务运行状况的监控,更是对于模型输出的结果进行监控,以查看模型在线上运行的效果是否符合预期,是否有比较大的变化。假设我们的新闻分类模型已经部署上线,每一条新闻流过将会被标注上若干个标签,然后进到推荐系统被召回排序分发给用户。
模型的监控可以从三个方面入手,分别是结果监控、人工定期复审以及Case收集与样本积累。
结果监控
结果监控主要是针对一些具体的指标进行监控,包括我们在评估环节用到的准确率、召回率等,另外还可以根据具体产出的结果在业务中的效果进行监控。
首先可以想到的是针对每天新闻的分类标签进行排名统计,来查看每个标签的占比情况与我们的初始数据是否接近;还可以监控到一些数据较少的类别是否能够被预测出来,这属于稳定性指标。
其次,在推荐系统中,我们还会有CTR(点击率预估)这样的总体指标,可以对标签与CTR的关系进行计算,来查看每个标签的CTR情况。
在一些App中还会有主动负反馈,让用户自己选择不喜欢的标签。通过分析这些数据可以知道我们的模型结果是否还符合业务场景,是否需要做出一些调整。在一些长期的大型项目中,我们甚至需要建设一些Debug平台,对这些数据进行持续的、可视化的监控,观察每天每周的变化情况。
人工定期复审
第二个方法就是定期进行人工复审,该方法主要针对业务需求准确率的情况进行评估,查看当前的模型效果是否还满足业务的需求,准确率情况是否有所变化,同时也可以跟业务进行沟通评估,确认当前的情况是否需要对模型进行重新训练。
Case 收集与样本积累
第三个,在整个监控的过程中,也需要进行Case的收集。通过具体的Case 我们可以知道当前的模型存在哪些问题,有些Case可能是由于模型本身的问题造成的;有些Case是由于我们的业务场景数据发生了变化造成的。通过对收集的Case进行分析,也可以知道我们需要往哪个方向去优化模型。同时,收集足够的Case也可以作为我们重新训练的样本积累,所以要注意在前期准备数据时遇到的数据不充分或者不准确的情况,也可以在收集环节重点关注,以补全我们上一版训练时的一些缺失情况,这样在下一次训练迭代时能够有更好的样本集。
重新开启
此时此刻,再回想一下最开始画的那张数据挖掘流程图。虽然我这里按照顺序一步步进行讲解,但实际上,每一个步骤并不是严格独立存在的,比如我们在准备数据阶段发现数据无法解决业务需求时,那就要返回去重新讨论业务需求与数据的问题;在训练模型阶段发现数据与模型无法匹配,或者如果要更换其他模型时,那要回到准备数据环节;如果在模型评估的时候发现效果达不到预期,那可能要回到准备
数据环节重新处理数据,甚至要回到理解业务阶段。而在这里,我们的模型已经上线应用,但不代表工作已经完全结束了。
我们的公司无时无刻不在发生着变化,用户群体、用户行为也在发生变化,数据采集的技术也在不断更新,所以我们的模型也不是一成不变的,在经过一段时间的运行之后,它的能力可能无法适配当前的情况,此时我们又要回到故事的开头,去思考业务,理解数据了。
所以说,时刻准备好重新开始。
总结
到了模型应用这一课时,关于数据挖掘流程相关的部分就已经讲完了。在这一课时,我介绍了一些关于模型保存、模型优化、模型部署的思路,又讲了关于项目总结,乃至模型监控等内容,知识点比较零散,难免会有一些疏漏和不足,不过这些都是平时工作中的一些总结,权当抛砖引玉。如果关于这部分内容有什么好的想法和实践,也欢迎你提出来,集思广益、共同进步。
下一课时,我们将进入具体的算法模块,介绍算法的思想、优缺点,看看如何使用这些算法。
KNN 算法
你好,从这一课时开始,我们将进入“模块三:分类问题”的学习。在算法部分,我会介绍一个跟算法思想相关的小例子,然后介绍算法的优缺点和适用场景,对于部分算法我将给出算法模块的调用方法,此外一些扩展的内容我会放在最后讲解。在每一个类型的算法最后,我都尽量安排一节小小的实践课,一起来看看数据挖掘是如何做的。
今天我要讲的这个算法是最近邻算法(K-NearestNeighbor),简称KNN算法。
- 一个例子
有一句老话叫作“物以类聚、人以群分”。想象我们在一个特别的社区里,一条清澈的小河从社区中心流过,小河左侧环境优美,住着一群有钱人,家家户户都是别墅;而小河的另一侧,住着大片贫民,用茅草和纸板搭建的临时住所密密麻麻的。这时有一个新的住户从外面搬进了这个社区,他住在了小河的左侧,此时社区里就传开了消息:“我们这又搬来了一户有钱人家。”可是谁都不认识他,也看不到他的银行账户,为什么就认定他是有钱人呢?那是因为他跟有钱人住在一起了。故事到了这里,也就说明了最近邻算法的思路:“你跟谁住得近,你就跟谁是同一类”。
算法原理
有了思路,我们再来看看原理,KNN算法是如何处理的。用一句话来解释KNN算法原理,那就是找到K个与新数据最近的样本,取样本中最多的一个类别作为新数据的类别。在前面的例子中,找到和新搬进来的一户人家住的距离最近的K户人家,看看K户人家中是有钱人多还是穷人多,取多的那个类别作为新搬来这户的类别。所以,显然他住在富人区,那附近就会有更多的富人。
这里面我们提到了一个距离最近,关于距离该怎么计算呢?最常见的一个计算方法就是欧式距离,即两点之间的连线,如果放在地图上就是两个房子的直线距离。当然除了欧式距离,还有很多距离计算的方式,比如曼哈顿距离、切比雪夫距离等。

算法的优缺点
如此简单的算法都有哪些优缺点呢?下面我结合使用场景进行分析。
优点
简单易实现:刚把KNN算法介绍完了,是不是很简单?从上面的内容可以看出来,KNN算法最后实际上并没有抽象出任何模型,而是把全部的数据集直接当作模型本身,当一条新数据来了之后跟数据集里面的每一条数据进行对比。
所以可以看到KNN算法的一些优点,首当其冲的就是这个算法简单,简单到都不需要进行什么训练了,只要把样本数据整理好了,就结束了,来一条新数据就可以进行预测了。
对于边界不规则的数据效果较好:可以想到,我们最终的预测是把未知数据作为中心点,然后画一个圈,使得圈里有K个数据,所以对于边界不规则的数据,要比线性的分类器效果更好。因为线性分类器可以理解成画一条线来分类,不规则的数据则很难找到一条线将其分成左右两边。
缺点
只适合小数据集:正是因为这个算法太简单,每次预测新数据都需要使用全部的数据集,所以如果数据集太大,就会消耗非常长的时间,占用非常大的存储空间。
数据不平衡效果不好:如果数据集中的数据不平衡,有的类别数据特别多,有的类别数据特别少,那么这种方法就会失效了,因为特别多的数据最后在投票的时候会更有竞争优势。
必须要做数据标准化:由于使用距离来进行计算,如果数据量纲不同,数值较大的字段影响就会变大,所以需要对数据进行标准化,比如都转换到0-1的区间。
不适合特征维度太多的数据:由于我们只能处理小数据集,如果数据的维度太多,那么样本在每个维度上的分布就很少。比如我们只有三个样本,每个样本只有一个维度,这比每个样本有三个维度特征要明显很多。
关于K的选取
K值的选取会影响到模型的效果。在极端情况下,如果K取1,由于富人区人均面积都很大,家里可能是别墅加后花园,富人与富人房子的距离相对较远,那个恰好住在河边的人可能跟河对面的一户贫民家最近,那么这个新人就会被判定为贫民。
如果K取值与数据集的大小一样,那么也可想而知,由于贫民的人数户数都远远多于富人,那么所有新进来的人,不管他住哪里都会被判定为贫民。这种情况下,最终结果就是整个样本中占多数的分类的结果,这个模型也就没有什么作用了。
用我们前面学过的内容来看,当K越小的时候容易过拟合,因为结果的判断与某一个点强相关。而K 越大的时候容易欠拟合,因为要考虑所有样本的情况,那就等于什么都不考虑。
对于K的取值,一种显而易见的办法就是从1开始不断地尝试,查看准确率。随着K的增加,一般情况下准确率会先变大后变小,然后选取效果最好的那个K值就好了。当然,关于K最好使用奇数,因为偶数在投票的时候就困难了,如果两个类别的投票数量是一样的,那就没办法抉择了,只能随机选一个。
所以选取一个合适的K值也是KNN算法在实现时候的一个难点,需要根据经验和效果去进行尝试。
尝试
接下来,我们尝试借助代码来使用KNN算法。今天的动手环节可能要多一点,因为还涉及一些周边的东西,所以我会把前后的代码都写上,包括数据集获取、数据的处理以及训练和预测等环节,在后面一些算法的动手环节就不需要再去重复了。
首先是导入我们所需要的依赖库:
1 | from sklearn import datasets #sklearn的数据集 |
在这里我们使用一个叫作鸢尾花数据集的数据,这个数据集里面有150条数据,共有3个类别,即Setosa 鸢尾花、Versicolour 鸢尾花和 Virginica 鸢尾花,每个类别有50条数据,每条数据有4个维度,分别记录了鸢尾花的花萼长度、花萼宽度、花瓣长度和花瓣宽度。
1 | iris=datasets.load_iris() |
下面是输出的结果:
1 | iris_y_predict = |
可以看到,该模型的准确率为0.9,其中第二个数据预测错误了。
经过上面的一个动手尝试,我们已经成功地实践了KNN算法,并使用它对鸢尾花数据进行了分类计算,不知道你是不是有点小激动?当然,关于里面的很多细节这里都没有涉及,希望大家接下来能够更加深入地去探索。
总结
这一小节,我们开始真正走进了一个算法之中,去研究算法的奥秘。当然,我期望以一种简单易学的方式向你介绍算法的原理,并去掉了那些让人头疼的计算公式。在这一节里,我介绍了KNN分类算法,从一个例子开始,然后引入了它的原理,并希望你能了解它的优缺点,对于后面的算法,我也会沿用这种方式去介绍。最后,我还写出了一段简单的代码,如果你已经在电脑上安装了Python,那你可以复制并直接运行它,当然我希望你能够自己去敲一遍代码,这样也能够加深你的印象。
决策树
今天是分类算法的第二课时,我们今天要介绍的是一个应用非常广泛的模型–决策树。首先我依然会从一个例子出发,看看女神是怎样决策要不要约会的;然后分析它的算法原理、思路形成的过程;由于决策树非常有价值,还衍生出了很多高级版本,在扩展内容里我也进行了简要的介绍。希望通过本课时的学习,你可以掌握决策树的思路以及使用方法,并能够尝试用它来解决遇到的问题。

- 一个例子
我们都知道女神身后有很多的追求者,她肯定不会和每个人都约会,因为时间不够,必须要好好管理自己的时间才行。于是女神给每个想要约会的人发信息说:“把你的简历发过来吧。”
简历收上来后,第一眼先看照片,颜值打几分?然后再看年收入,长得帅的就可以少挣点,毕竟“帅也可以当饭吃啊”。不帅的呢?那收入必须要求高一点,“颜值不够,薪资来凑”。薪资还差点的,再看看学历是不是研究生/985/211,看看身高有没有180......所以你就可以对号入座了,发现自己哪条都不符合,好了,去好好“搬砖”吧。
由此可知,女神的筛选条件有颜值、身高、收入、学历等,每一项都会对最后是否约会的结果产生影响,即女神通过对这几种条件的判断,决定是否要安排约会。
上面这个过程就是决策树的思路,下面我们来看一下决策树的具体原理。
算法原理
在已知的条件中,选取一个条件作为树根,也就是作为第一个决策条件,比如“颜值”分为帅和不帅两个结果,然后再看是否还需要其他判断条件。如果需要的话,继续构建一个分支来判断第二个条件,以此类推,直到能够推出一个结果,这个分支就结束了。
同样的,当我们把所有样本数据中出现的情况组合都构建入这棵树的时候,我们的算法也就完成了对样本的学习。最终形成的这棵树上,所有的叶子节点都是要输出的类别信息,所有的非叶子节点都是特征信息。当一个新的数据来了之后,就按照对应的判断条件,从根节点走到叶子节点,从而获得这个数据的分类结果。
比如,我帮女神收集了几份简历,然后按照条件整理出如下结果:
| 编号 | 颜值 | 年收入 | 身高 | 学历 |
|---|---|---|---|---|
| 1 | 帅 | 28w | 178 cm | 本科 |
| 2 | 不帅 | 100w | 176cm | 硕士 |
| 3 | 不帅 | 40w | 185 cm | 硕士 |
根据女神已经制定好的决策树,我们去预测一下这三个人能否获得约会资格。第一个人帅,那就从根节点走向左分支;再判断第二个条件:年收入只有28w,不到30w的标准,那就被淘汰了。第二个人不帅,走向右分支,年收入100w,那就可以继续往下进入左分支,身高176cm刚好过合格线,获得左分支的结果,顺利进入约会环节。第三个人不帅,年收入40w,那就进入右分支,还需要再看学历:是研究生,那还可以继续走向左分支,身高有185cm,那也成功获得约会资格。
这就是决策树最初的一个思路。但是这里有一个问题,我想你可能也会想到,那就是该如何选择一个特征作为根节点?下一次决策又该选取哪个特征作为节点?决策树算法使用了一种称作信息增益的方法来衡量一个特征和特征之间的重要性,信息增益越大表明这个特征越重要,那么就优先对这个特征进行决策。至于信息增益和信息熵是在信息论中涉及的内容,如果你有兴趣可以再进行详细学习。
在一种理想的情况下,我们构建的决策树上的每一个叶子节点都是一个纯粹的分类,也就是通过这条路径进入到这个叶子节点的所有数据都是同一种类别,但是这需要反复回溯修改非叶子节点的判定条件,而且要划分更多的分支来进行处理,所以实际上决策树实现的时候都采用了贪心算法,来寻找一个最近的最优解,而不是全局的最优解。
算法的优缺点
几个版本的决策树的比较
决策树最初的版本称为ID3(Iterative Dichotomiser 3),ID3的缺点是无法处理数据是连续值的情况,也无法处理数据存在缺失的问题,需要在准备数据环节把缺失字段进行补齐或者删除数据。后来有人提出了改进方案称为C4.5,加入了对连续值属性的处理,同时也可以处理数据缺失的情况。同时,还有一种目前应用最多的CART(Classification And Regression Tree)分类与回归树,每次分支只使用二叉树划分,同时可以用于解决回归问题。
关于这三种决策树,我列了一个对比的表格,可以看到它们之间的区别。
| 决策树 | 模型类型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处 |
|---|---|---|---|---|---|
| ID3(Iterative Dichotomiser 3) | 分类 | 多叉树 | 信息增益 | 不可以 | 不可以 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 可以 | 可以 |
| CART(Classification And Regression Tree) | 分类与回归 | 二叉树 | 基尼系数 | 可以 | 可以 |
这里的优缺点是针对CART树来讲,因为现在CART是主流的决策树算法,而且在sklearn工具包中使用的也是CART决策树。那么我们再看一下,决策树算法有什么优缺点。
优点
非常直观,可解释极强。在生成的决策树上,每个节点都有明确的判断分支条件,所以非常容易看到为什么要这样处理,比起神经网络模型的黑盒处理,高解释性的模型非常受金融保险行业的欢迎。在后面的动手环节,我们能看到训练完成的决策树可以直接输出出来,以图形化的方式展示给我们生成的决策树每一个节点的判断条件是什么样子的。
预测速度比较快。由于最终生成的模型是一个树形结构,对于一条新数据的预测,只需要按照条件在每一个节点进行判定就可以。通常来说,树形结构都有助于提升运算速度。
既可以处理离散值也可以处理连续值,还可以处理缺失值。
缺点
容易过拟合。试想在极端的情况下,我们根据样本生成了一个最完美的树,那么样本中出现的每一个值都会有一条路径来拟合,所以如果样本中存在一些问题数据,或者样本与测试数据存在一定的差距时,就会看出泛化性能不好,出现了过拟合的现象。
需要处理样本不均衡的问题。如果样本不均衡,某些特征的样本比例过大,最终的模型结果将会更偏向这些特征。
样本的变化会引发树结构巨变。
关于剪枝
上面提到的一个问题就是决策树容易过拟合,那么我们需要使用剪枝的方式来使得模型的泛化能力更好,所以剪枝可以理解为简化我们的决策树,去掉不必要的节点路径以提高泛化能力。剪枝的方法主要有预剪枝和后剪枝两种方式。
预剪枝:在决策树构建之初就设定一个阈值,当分裂节点的熵阈值小于设定值的时候就不再进行分裂了;然而这种方法的实际效果并不是很好,因为谁也没办法预料到我们设定的恰好是我们想要的。
后剪枝:后剪枝方法就是在我们的决策树已经构建完成以后,再根据设定的条件来判断是否要合并一些中间节点,使用叶子节点来代替。在实际的情况下,通常都是采用后剪枝的方案。
尝试
关于几个版本的决策树你已经有了大致的了解,那么下面我们来动手写一写使用决策树算法进行的代码。
在前面的部分我没有写更多的注释,这部分是关于包的引入和导入数据的,在前面的章节已经进行过介绍,这里主要是把引入的算法包进行了调整,其余的部分实际上没有什么修改,如果你忘了可以看一下前面的章节。
1 | from sklearn import datasets |
在模型训练时,我们设置了树的最大深度为4。
1 | clf = DecisionTreeClassifier(max_depth=4) |
根据上面的介绍,我们可以知道,经过调用fit方法进行模型训练,决策树算法会生成一个树形的判定模型,今天我们尝试把决策树算法生成的模型使用画图的方式展示出来。
1 | from IPython.display import Image |
经过运行上面的代码,就会输出下面这幅图,可以看到每一次的判定条件以及基尼系数,还有能够落入此决策的样本数量和分类的类别。

看完了模型,我们使用模型来对测试数据进行一下预测。这里调用的预测方法跟之前都是一样的,这里就不详细介绍了。
1 | iris_y_predict = clf.predict(iris_x_test) |
我们看一下输出的结果,可以看到第二个测试样本预测错误了,其他的都预测正确,准确率是90%。
1 | iris_y_predict = |
今天我们的代码主要实现了工具包中的决策树算法,同时新增了一块输出决策树模型的方法,你是否也想亲手来试一下呢?下面我再讲解一些扩展内容,看看决策树算法在后续的演进中都有什么样的变化。
扩展内容
随机森林:为了更好地解决泛化及树结构变动~等~问题,从决策树演进出来随机森林算法。根据我们前面讲的模型集成方法,随机森林就是使用了bagging方案构建了多棵决策树,然后对所有树的结果来进行平均计算以获得最终的结果。
GBDT:在随机森林的基础上,研究者又提出了梯度提升决策树算法(Gradient Boosting Decision Tree,GBDT),GBDT是基于boosting的策略。与随机森林一样的是,GBDT也会构建多棵决策树;但不同的是,GBDT构建的多棵树之间是有联系的,每个分类器在上一轮分类器的残差基础上进行训练。
XGBoost:一个非常火热的模型,有“机器学习大杀器”之称,在很多比赛中都获得了非常好的结果。但实际上XGBoost不算是一个算法,而是对GBDT的一种工程实现,它优化了GBDT里面的求解过程,并加入了很多工程上的优化项目,使得数据处理、运算速度等环节都有了很大的提升。
- 总结
这一小节的课程,我们讲解了第二个分类算法–决策树算法,首先从女神如何决策跟谁约会的问题出发,引出了决策树算法的原理,由于决策树算法非常容易理解,效果很好而且易于解释,所以研究者提出了各种各样的改进方案,并由决策树延伸出了很多新的优秀的算法。在尝试动手的环节,本课时加入了一些绘图的技巧,希望大家也能够掌握这部分的内容,这样也可以提升工作效率。
看完了决策树算法的介绍,不知道你是否对其中的细节还有什么疑惑?你可以在评论中写下来与大家一起讨论。
朴素贝叶斯
本节课讲解第三个分类算法–朴素贝叶斯,我依然以一个例子开头,带领你进入朴素贝叶斯算法的世界,通过算法原理、算法优缺点的讲解,带你算一算是否要买航空延误险。最后我们再动手来写一下代码,看看如何使用朴素贝叶斯来进行分类。
- 一个例子
最近看到一则新闻,王女士从2015年开始,凭借自己对航班和天气的分析,成功地购买了大约900次飞机延误险并获得延误赔偿,累计获得保险理赔金高达300多万元。那么她是怎么决定要买延误险的呢?
其实,航班延误最主要的原因就是天气变化,包括起飞地及降落地的天气;除此之外,也有机场和航空公司的原因。假设这些原因之间并没有互相影响,每一项对于飞机最终是否延误的影响都是独立的,王女士集齐过去的数据,就可以计算出每一个条件与飞机延误的概率。比如,在总体上延误的概率为20%,不延误的概率为80%。在飞机延误的情况下,“起飞地天气=晴天”的概率为20%,“降落地天气=雨天”的概率为40%,“机场=首都机场”的概率为35%,“航空公司=南方航空”的概率为5%;在不延误的情况下,这些属性的概率分别为60%、55%、45%、55%。
那么这个时候,有一架南方航空公司的航班,从北京飞往上海,北京天气是晴天,上海天气是雨天,那么,我们就可以根据上面的概率算出来不延误的综合概率=80%x60%x55%x45%x55%=0.0065412,延误的综合概率=20%x20%x40%x35%x5%=0.00028,从这个结果来看,不延误的可能性要高于延误的可能性,所以这次不需要买延误险。
算法原理
上面的这个例子就是我今天要介绍的算法–朴素贝叶斯分类器的思路,贝叶斯这个名字你应该很熟悉,这简直就是概率论的鼻祖,所以我们这个算法的原理也跟概率论脱不开干系。考虑我们分类所用到的特征和分类结果,朴素贝叶斯有一个假设前提,那就是所有的条件对结果都是独立发生作用的。就像我们上面预测是否要买延误险一样,起飞地的天气不会对降落地的天气有影响,同时起飞地和降落地的天气以及所造成的延误问题不会比他们单独发生时有任何区别。所以根据这个思想,出现了朴素贝叶斯概率公式:

在某些已知的情况下,获得某个分类的概率就等于在已知分类的情况下,某个属性的概率乘以分类的概率再除以属性的概率。具体到我们的例子上,如下所示:

我们需要获得的是左侧的结果,而右侧就是基于已有的样本数据可以计算出来。而根据上面提到的朴素贝叶斯的假设,最重要的就是下面这个转换:

于是,根据已经有的数据,我们可以计算出每一个特征对最终结果的概率情况,比如,有100条数据,结果延误的有20条,结果不延误的有80条。在延误的20条中,起飞地=晴天的有4条,那么在已知延误的情况下起飞地是晴天的概率为20%;在不延误的80条数据中,起飞地=晴天的有48条。那么在已知不延误的情况下,起飞地是晴天的概率为60%。依据这个方法,我们就可以计算出所有我们需要的概率值,像上面的例子中那样。
如何处理连续值
预测购买延误险的例子中使用的都是离散值,那么对于连续值该怎么处理呢?假设我们新增一个特征–机票的价格。这时,机票价格是一个连续值,我们可以假设机票这个特征服从正态分布,通过样本集计算出机票价格对应每一个分类的均值和方差,再根据比如密度函数,计算出新数据与均值的距离,从而获得一个概率值。关于这一块的处理细节,如果你有兴趣可以再查找一些详细的讲解。
关于平滑
对于离散值,有一个需要注意的地方:如果某一个属性值比如“航空公司=西藏航空”,由于数据比较少,在“分类=延误”的类别下没有出现过,那么按照上面的方法,不管其他的特征如何,P(“航空公司=西藏航空”|延误)=0,所有用到这个的结果都会是0。那么,这里就有一个数据准备环节的方法,称为“平滑”(Smoothing)。这时我们可以想到一个简单的平滑方案,那就是在分子分母中同时加上一个较小的值,来防止出现分子或分母为0的情况。除了我说的这种简便方法外,还有常用的拉普拉斯修正、古德-图灵估计法、Katz等平滑的方法,这里就不-介绍了。
已经清楚了算法的基本原理,接下来我们再看一下朴素贝叶斯算法有什么优缺点。
算法的优缺点
优点
逻辑清晰简单、易于实现,适合大规模数据。根据算法的原理,只要我们把样本中所有属性相关的概率值都计算出来,然后分门别类地存储好,就获得了我们的朴素贝叶斯模型。
运算开销小。根据上一条我们可以得知,所有预测需要用到的概率都已经准备好,当新数据来了之后,只需要获取对应的概率值,并进行简单的运算就能获得结果。
对于噪声点和无关属性比较健壮。噪声点和无关属性对算法影响较小,在很多邮件服务中仍然一直沿用这个方法进行垃圾邮件过滤。
预测过程快。由于所有需要用到的属性相关概率都已经计算出来了,在新数据到来需要预测的时候,只需要把对应的一些概率值取出来进行计算就可以获得结果,所用到的时间和空间都很小。
缺点
由于做了“各个属性之间是独立的”这个假设,同样该算法也暴露了缺点。因为在实际应用中,属性之间完全独立的情况是很少出现的,如果属性相关度较大,那么分类的效果就会变差。所以在具体应用的时候要好好考虑特征之间的相互独立性,再决定是否要使用该算法,比如,维度太多的数据可能就不太适合,因为在维度很多的情况下,不同的维度之间越有可能存在联合的情况,而不是相互独立的,那么模型的效果就会变差。
尝试
通过案例我们了解了算法的原理及其优缺点,下面动动手指尝试使用贝叶斯算法来解决问题吧。
本节的代码主要调整的部分就是引入的算法模块,其他部分在前面的实践中都已经写过,你实现起来应该已经轻车熟路了。
1 | from sklearn import datasets |
我们来看一下代码的输出结果,可以看到,这次仍然是第二个没有预测正确,模型的准确率为90%。
1 | iris_y_predict = |
这次的代码实践没有增加太多新的内容,你写起来应该非常轻松了。在实际的研究中,也有不少基于朴素贝叶斯算法发展出来的新方法,下面我们再来看一下朴素贝叶斯的扩展内容。
扩展内容
前面我们讲到,朴素贝叶斯是基于属性之间的独立性假设而进行构建的,但是实际上很多时候这种假设存在一定的局限,为了打破这些局限,于是衍生出了一些方法,下面我列举两个:
半朴素贝叶斯ODE(One Dependent Estimator):为了解决朴素贝叶斯中属性独立性假设在实际生活中不太适用的问题,新的研究方案尝试建立一些属性间的联系,假定属性有一定的相关性,从而产生的算法被称为半朴素贝叶斯方法。这里说的ODE就是其中的一种,在ODE中,假设每个属性最多依赖于一个其他的属性,这样修正了一些有依赖的情况,同时又没有增加太多的计算复杂性。
AODE (Averaged One Dependent Estimator):AODE其实是一种集成学习的方法。在ODE的基础上,使用bagging集成学习的思路,训练多个模型,其中每个模型都设置一种属性作为其他所有属性的关联属性,最后使用这多个模型的结果平均数值作为最终结果。
- 总结
讲到这里,我们这一课时的内容又要结束了,不知道你是否意犹未尽?我在这节课里讲解的朴素贝叶斯算法是一个非常简洁的算法,只需要进行比较简单的数学计算就可以获得我们所要的结果。在开头,我列举了一个关于计算是否要买延误险的例子,那么通过这一节的学习,你下次买机票的时候是不是也可以算一算自己是不是要买延误险了?这节课的动手实践部分比较简单,希望能够加深你的动手能力。
支持向量机(SVM)
今天要介绍的算法叫作支持向量机(Support Vector Machine,SVM)算法。这个算法在1995年就已经被发表出来了,由于在文本分类任务上面表现优异,SVM算法很快就如日中天,成为机器学习的主流算法。在后面很长一段时间里,都有大量的学者对它进行了深入研究和改进,甚至写了很多相关的书籍。下面我们从一个例子出发,去看看这个算法是基于什么样的思路产生的。
- 一个例子

秋天来了,丰收的季节到了。我们把收获的红豆和绿豆从豆荚里摘出来,然后铺在地上晾晒。大伯拉着红豆和绿豆来到一条公路附近,把绿豆铺在公路的左边,红豆铺在公路的右边。
后来,陆陆续续还有人来晒豆子,为了划分好红豆和绿豆,防止混合到一起,这个时候我们在红豆和绿豆之间画一根线,这样就可以比较明显地分出红豆和绿豆的界限。
在目前的情况下,红豆和绿豆的中间有一条宽阔的马路,你可以在马路上任意地画出一条线,只要不超出这个界限就可以分割红豆和绿豆了,但是,如果是斜着划线,那么只要铺的豆子足够长,这条线早晚会超出公路的范围,而把一些红豆划为绿豆,所以要划的线肯定要跟笔直公路平行,这样至少不管画多远都不会超出公路。而沿着公路,仍然有很多条线可以画,但是想到有些豆子可能不太听话,有时候会跑到公路上面一两颗,这样的话,当然是选马路中轴线作为我们的划分直线最好了。
算法原理
上面就是SVM支持向量机的思考来源,SVM要解决的就是怎么找到那条中轴线。虽然这个想法十分简单,然而具体做起来有很大的难度。实际上,在我们的数据中并没有一条公路,而是只有两堆豆子,SVM要解决的问题就是首先要找到一些线,这些线都可以分割红豆和绿豆;然后再找到正确的方向/斜率的那条线;最后确认马路的宽度,当然是越宽越好,这时候得到最优解–马路的中轴线。
比起其他分割线,这个马路的中轴线对于未知的数据宽容度最大,使用中轴线来作为分界线,当新数据发生了一些波动,超过了马路的边界,仍然不会对结果产生影响,因此它被认为是最优解,所以SVM 就是基于优美的数学推导不断探索最优解的一个算法。
到这里,我们已经知道了SVM的思考路径,然而SVM所涉及的内容远没有介绍完,下面我们再来看几个SVM所涉及的名词。

什么是超平面?
我们首先想一想什么是平面。根据定义,在三维空间中,平面就是到两个点距离相同的点的轨迹。一个平面没有厚度,而且可以把空间分割成两部分。而超平面就是在这个基础上进行的延伸,在维度大于三维的时候仍然满足上面的条件,而且它的自由度比空间维度小1。对于这样的一个数学概念,就称为超平面。通俗地讲,在二维中就是直线,在三维中是平面,在三维以上的维度中就是超平面。
什么是支持向量?
假设我们已经找到了一条线(不一定是最优的那条)可以分割红豆和绿豆,红豆和绿豆中距离这条线最近的几个样本点就被称为支持向量(Support Vector),这些点到这条线的距离称为间隔,SVM的思路就是要找到有最大间隔的那条线(超平面)。在决定最佳超平面时只有支持向量起作用,而其他数据点并不起作用,如果移动非支持向量,甚至删除非支持向量都不会对最优超平面产生任何影响。即支持向量对模型起着决定性的作用,这也是“支持向量机”名称的由来。
如何处理不清晰的边界?
在我们晒豆子的时候,不小心把一些豆子踢到了马路上,最后红豆和绿豆产生了一些交叉,甚至有一两个绿豆完全进入了红豆的区域,这大概也比较符合我们平时遇到的数据的情况。这时就有一个新的概念:软间隔,也就是说在这个间隔区域里允许出现一定数量的样本,我们就称为这个间隔为软间隔;像最开始那种划分非常清晰,在间隔中间没有任何红豆和绿豆的理想状态下,间隔就称为硬间隔。

像我上面画的这幅图,红豆和绿豆的分布间隔并不是那么明显,甚至有些红豆和绿豆都已经分布在同样的位置,这个时候使用硬间隔,不允许间隔中出现任何豆子明显是不现实的,我们永远没办法找到一条线来把这两种豆子划分清楚,更没办法找到一个硬间隔区间。在这种情况下,我们允许间隔区域有一定的豆子出现,从而作为软间隔区间来进行划分。
如何处理非线性可分?
上面我们画出的绿豆和红豆是线性可分的,可是在数据中,还有很多是线性不可分的情况。如下面这张图,我们在一个方形的广场上晾晒豆子,把豆子摆成方形,内圈是绿豆,外圈是红豆。这就没有办法画一条线把红豆和绿豆切分出来了。
在SVM中采取的办法是把不可划分的样本映射到高维空间中,让样本在高维空间中可以线性可分。当然了,在高维空间,比如在三维空间中,线性可分就是可以画一个平面把红豆和绿豆切分成两个部分。
试想本来落在地上的红豆和绿豆本来没办法划分,这个时候在广场的底部有一个巨大的风机,这个风机可以提供稳定的风,从豆子下方往上方吹。由于红豆和绿豆的密度和质量不同,当风机开动之后,红豆和绿豆飞起来;等待稳定之后,红豆和绿豆就会悬停在不同的高度上,这个时候我们就可以放一个巨大的平面进去,把红豆和绿豆划分开来。

当然了,在SVM中没有吹风机,在SVM中借助“核函数”来实现映射到高维的操作。常见的核函数有线性核函数、多项式核函数、高斯核函数等。使用核函数主要是模拟特征转化到高维空间的内积计算结果,在实现了映射到高维的同时,降低了计算量,同时也能够节省计算用的内存。
关于SVM算法的主体部分到这里讲得差不多了,当然,SVM里面的高深的数学原理我们还远未涉及,如果大家对公式的推导很感兴趣,可以找一些资料来进行学习。接下来我们看一下,对于实际的工作,我们该注意一下SVM有什么优缺点。
算法的优缺点
优点
有严格的数学理论支持,可解释性强。SVM所获得的结果是全局最优解而不是局部最优解,很多算法为了降低复杂性只给出了一个局部最优解,比如我们前面提到的“决策树算法”,而SVM的最优化求解所获得的一定是全局最优解。
算法的鲁棒性很好。由于计算主要依赖于关键的支持向量,所以只要支持向量没有变化,样本发生一些变化对算法没有什么影响。
缺点
训练所需要的资源很大。由于运算量与存储量都很高,SVM训练的开销也是巨大的,因此支持向量机只适合比较小的样本量,比如几千条数据,当样本量太大时训练资源开销过大。
只能处理二分类问题。经典的SVM算法十分简洁,正如上面的例子一样,画一条线分割两个类别,如果需要处理多类别的分类问题,需要使用一些组合手段。
模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。因此支持向量机目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务。
尝试
与之前的课时相同,下面我们亲自来练练手,用代码实现使用SVM算法。在本节的代码中,在数据获取与数据处理阶段仍然沿用了之前的方法,没有任何改动,主要的区别是我们引入的算法包为SVM 包,在进行分类时使用的是SVM分类器。
1 | from sklearn import datasets |
使用SVM算法得到的结果如下,可见第二个位置的预测仍然是错误的,这个位置的数据看来十分难分对。
1 | iris_y_predict = |
如果你有时间,尽量把代码亲手敲一遍以加深自己的印象,同时可以去sklearn网站上查看一下该算法的各种使用方法和接受参数,尝试进行一些改变,看看是否会有一些不同的结果。
- 总结
完成了我们的代码部分,我们这一课时的讲解就告一段落了。本课时我们介绍支持向量机SVM算法的基本内容,我觉得SVM是众多算法中最复杂的一个算法,当然这节课我屏蔽了那些艰涩的部分,期望能够以一种简单易懂的方式向你介绍SVM的原理。关于SVM的细节,尤其是数学上的推导我们没有涉及,如果你有兴趣可以进行更深入的学习。
人工神经网络
自从2016年Alpha Go打败了李世石,神经网络和深度学习就已经进入了广大人民群众的视野,这个方向已经变得越来越火热,各路专家层出不穷地改进算法以及预训练模型,让人眼花缭乱。但是实际上人工神经网络算法早在几十年前就已经有了,只不过随着算力的进步以及科学家们不懈的改良,现在有了更加优秀的效果和广阔的应用,那么今天我就来介绍一下人工神经网络的基础算法。先来看一个例子。
- 一个例子
人的大脑是一个很好的记忆、逻辑、运算、推理的设备,其实人工智能就是在不断地模拟大脑的判断逻辑,那么能不能构建一个算法来完全模拟生物学上大脑的运行方式以实现大脑的功能呢?伴随着这个思路,我们先来看看人的大脑是怎么构成和工作的。

人在刚出生的时候有2000亿的脑细胞,虽然脑细胞不会再生,而且在生命的过程中一直在死亡,但是活到100岁仍然会有27亿的脑细胞。在我们的脑细胞中,起到记忆和运算的功能单位是神经元,神经元包含了轴突和树突,树突负责接收信号、轴突负责发送信号。在不同的神经元之间依靠突触进行连接,一个神经元可能会与很多神经元连接,这样形成了错综复杂的关联关系,最终构成了我们的神经系统。
神经元可以发送电化学脉冲信号,如果信号足够强,会跨过突触间隙,到达另一个神经细胞,就可以激活神经细胞释放“化学物质”;如果信号强度不够强,则不会释放化学物质;同时多个输入信号可以进行叠加从而达到激活强度。不仅如此,神经元还可以形成新的连接,甚至改变连接。
算法原理
我们先考虑一个最简单的神经系统,这个神经系统里面总共有两层神经元:一层输入单元和一层输出单元。我们现在要根据已知数据去预测一个结果,这个结果符合方程:
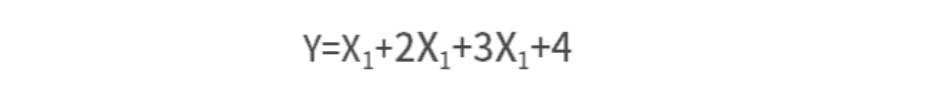
假设一个输入神经元处理一个特征,那么我们需要4个输入神经元、1个输出神经元输出结果,由此可知,我们构建的这个模型就会具备下图所示的结构,这个模型的目的就是去寻找从输入单元到输出单元这条线上的权重,来根据数据拟合结果,这就是一个最简单的人工神经网络模型ANN (Artificial Neural Network).

你会想,天呐,这不是在“坑”我吗?这不就是一个线性回归模型吗?是的,这个确实跟线性回归模型没有太大的区别。但是不要着急,我们再来看下面这张图:

这样是不是有点“网络”的意思了?我们在输入层和输出层之间加入了一个隐藏层,那么这个模型就可以处理非线性关系了。所以可想而知,根据不同的问题,可以加入多个隐藏层,由图中这种全连接改为部分连接,甚至是环形连接等。
所以,神经网络算法处理过程如下。
第一步,我们要预先设定一种网络结构和激活函数,这一步其实很困难,因为网络结构可以无限拓展,要知道什么样的结构才符合我们的问题需要做大量的试验。
第二步,初始化模型中的权重。模型中的每一个连接都会有一个权重,在初始化的时候可以都随机给予一个值。
第三步,就是根据输入数据和权重来预测结果。由于最开始的参数都是随机设置的,所以获得的结果肯定与真实的结果差距比较大,所以在这里要计算一个误差,误差反映了预测结果和真实结果的差距有多大。
最后一步,模型要调节权重。这里我们可以参与的就是需要设置一个“学习率”,这个学习率是针对误差的,每次获得误差后,连接上的权重都会按照误差的这个比率来进行调整,从而期望在下次计算时获得一个较小的误差。经过若干次循环这个过程,我们可以选择达到一个比较低的损失值的时候停止并输出模型,也可以选择一个确定的循环轮次来结束。
人工神经网络算法的大致流程就如上面介绍的这样,只要按照步骤去进行搭建就可以完成一个网络模型的构建。
关于激活函数
上面我提到了一个激活函数,这个词可以参考前面神经元的故事加以理解。神经元的激活需要电信号累加到一定的水平,这个神经元才会激活,所以我们在模拟神经网络的时候也需要有这样一个方法,在上层节点的输出和下层节点的输入中间加入一个激活函数,来实现这个功能。
如果没有激活函数,那不管有多少层网络,神经元之间也仍然是线性关系,就像没有隐藏层的时候一样,加入了非线性函数作为激活函数,这样深层次的网络就可以去拟合任意类型的函数了。常见的激活函数有ReLU、tanh、Sigmoid等,在不同的场景下可能需要不同的激活函数。
了解完了人工神经网络模型的基本原理,下面我们来了解了一下它的优缺点。
算法优缺点
优点
经过上面的介绍,我不知道你是否了解到了关于神经网络的一个巨大的优点,那就是可以像搭积木一样不断地扩展模型的边界,而对于内部具体的运行不需要加以太多的干涉。通过不同的搭建手段,神经网络几乎可以去模拟任何算法的结果,只要数据量够多,构建的模型够完善,最终都会有一个很好的结果。
缺点
然而神经网络的优点反过来想,也变成了它的缺点。首先神经网络缺乏可解释性,它的内部纷繁复杂,就像一个神奇的黑匣子,你告诉它数据,然后它告诉你结果,至于为什么会这样,它不做任何解释。所以在很多对解释性要求比较高的场景,比如信用评级、金融风控等情况下没办法使用。
其次,神经网络非常消耗资源,不管是数据、网络节点,还是硬件设备,要构建一套完美的神经网络模型开销是非常大的,不光训练时间长,还需要耗费很大的人力物力。
到这里,你应该已经对人工神经网络有了一个比较全面的认知,接下来进入我们的动手环节,用代码去实际感受神经网络的魅力。
尝试
在代码中,前半部分的数据处理环节仍然是使用的鸢尾花数据,与之前的处理没有任何区别。
1 | from sklearn import datasets |
后半部分,需要注意的是我们设置的参数,其中有一个比较重要的是hidden_layer_sizes,它用来设置隐藏层大小,长度就是隐藏层的数量。在第一次,我们设置的是[5,2]这个数组,这样我们的网络有两层隐藏层,第一层有5个神经元,第二层有2个神经元。
1 | clf = MLPClassifier(solver='lbfgs', alpha=1e-5, |
再看结果,这里需要注意一下,在第一次输出的时候,可以看到准确率只有20%,是不是让人大跌眼镜?不要担心,神经网络的重点就在这里,我们接着往下看。
1 | iris_y_predict = |
在第二次输出的时候,对于代码其他部分没有做任何调整,只是对hidden_layer_sizes进行了修改,改成了三个隐藏层,每个隐藏层有10个神经元,这个时候神奇的事情发生了,我们的准确率已经提升到了90%。
1 | iris_y_predict = |
到这里相信你对人工神经网络已经有了认识,并且学会了使用sklearn搭建一个简单的神经网络,在实际工作中可以应用这种算法去处理自己的工作。当然,上面的代码我们可以看到一个现象,在我们的网络规模增长了之后,效果就变得更好了,所以,人工神经网络的发展也展现出了“大力出奇迹”的现象。
扩展内容:大力出奇迹
近些年,人工神经网络重新大放异彩,并且有了一个新的名字–深度学习。研究深度神经网络的人越来越多,所以也构建出了很多优秀的模型,尤其是在图像处理和自然语言处理方面产生了巨大的成果。
在图像处理方面,原来有一个著名的比赛就是ImageNet大规模视觉识别挑战赛ILSVRC,除了模型本身的结构调整外,随着模型的隐藏层数量不断扩充,所用的参数量不断增加,预测的效果也越来越好,以至于在2017年图像识别的准确率已经达到了97%,超过了人类对图像的识别准确率,这个比赛也就此停止了。
在自然语言处理方面,最新的由Open AI推出的GPT-3模型,最大模式使用了45TB的数据量、1750亿的参数,这简直是一个爆炸级的数量。当然,要训练一个这样的模型所付出的算力也必然不菲。
可以看出,神经网络在大数据量,大规模网络的道路上一骑绝尘,虽然效果上有了长足的发展,但是也让很多个人和小公司望而却步。
- 总结
这节课又到了跟大家说再见的时候,在本小节的内容中,我们先认识了人的神经元,并了解了神经元的工作过程,从而引入到人工神经网络的构建上来。在介绍了人工神经网络的原理和优缺点之后,我在代码中展示了不同规模的神经网络对预测效果产生的影响。当然,现在火热的深度学习可不止这么一点内容,很多开源的框架不断涌现出来,比如TensorFlow、PyTorch、PaddlePaddle、MXNet等都是非常好用的深度学习框架,为我们构建和使用神经网络创造了极大的便利,在实际的工作中,通常也会选择这些框架来进行模型的构建和训练。如果你对深度学习有更多的兴趣,那可以在这些框架的官网找到更多的资料进行学习。
实践 1:使用 XGB 实现酒店信息消歧
前面我们讲解了数据挖掘思维,也介绍了一些数据挖掘所使用的算法,那么今天我们就从实际情况出发,看看数据挖掘该如何在工作中发挥作用。XGB算法我们在前面的章节已经做过一些了解,它是由决策树衍生出来的一种算法,在做实验和工业生产中都有非常好的效果。
有一天,酒店的业务人员突然找到我,说希望我们能够提供一个算法服务去为酒店信息做一个自动化的匹配,以通过算法的手段,找到那些确定相同的酒店和确定不同的酒店,这就是一个最基本的需求提案。
理解业务
遵循着我们前面所学的数据挖掘流程,首先来看下我们的业务需求。
刚一接到上面的需求提案,我或许没有办法立即给出一个结果,由于我本身并不是酒店业务人员,对于酒店业务的具体场景并不了解,所以这个事情能不能做、能够做到什么程度都不太明确,那么接下来我们就要跟业务方进行更加深入的沟通。
通过几次与酒店的技术和业务人员沟通,我终于弄明白了这个项目的背景:
当用户在马蜂窝打开一家选中的酒店时,不同供应商提供的预订信息会形成一个聚合列表准确地展示给用户。这样做首先避免同样的信息多次展示给用户影响体验,更重要的是帮助用户进行全网酒店实时比价,快速找到性价比最高的供应商,完成消费决策。
酒旅平台接入了大量的供应商,不同供应商会提供很多相同的酒店,但对同一酒店的描述可能会存在差异,比如:

而我们希望在用户视角看到如下图的内容,所以我们要对不同供应商提供的数据进行信息消歧。

在没有使用算法的时候,处理酒店信息主要以一些简单的规则进行匹配,规则的准确率较高,但是只能处理不到10%的数据,还有90%多的数据都需要运营人员进行人工对比。人工对文字和图片的内容相对比较敏感,但是对于数值型数据,比如经纬度却很难去判断,同时单个人工也很难掌握大量的地理位置信息知识,人工对比的成本之高可想而知。






理解数据
经过上面的沟通,我们已经大致了解了要解决的问题以及业务的背景是什么样子的。接下来,还要结合我们的数据来进行分析,以确定我们的问题是否能够得到解决。在查看数据的时候,我们发现了这样一些问题:
数据属性不同:由于有很多家供应商,他们提供的数据也各有特色。比如一些国内的供应商只提供了中文酒店名称,一些国外的供应商只提供了英文的酒店名称,而有些供应商会提供中英双语的名称;有些供应商会提供酒店的邮箱,有些供应商的数据里则没有这个字段。他们提供的数据属性存在很大的差异,这会影响到我们的特征处理。
数据形态不同:除了属性,数据的形态也有很多区别。有些供应商提供的国外酒店名称是当地的语言,比如日语,韩语,泰语等;有些供应商提供的名称中的数字可能是繁体数字,而有些提供的是罗马数字,有些是阿拉伯数字;有些供应商提供的描述是经过抽取的标签化描述,而有些提供的描述是酒店自己提供的大篇幅文字。这些字段虽然相同,但是内部存在着很大的差异,在做算法的时候也会产生很大的影响。
数据量大,全部对比不现实:在我们的数据库中,已经存在了数百万的酒店数据,而每一家供应商又会提供那么大一份数据。如果新数据要和库中的所有数据逐条进行对比,这是一个非常大的工程量,在处理时效上将无法完成要求。所以我们还需要更进一步沟通,以确定算法如何与业务进行结合,更好地发挥作用。
消歧错误带来的风险:对比一开始给出的例子,如果此时有一条数据是“桂林精品酒店(桂林火车站店),地址为环城西路67号”,这与上面的信息极其相似,如果我们在计算时恰好把这个数据也定义为与上面是同一家酒店,但实际上这是不同的两家酒店,如果用户订了第一个酒店,但是实际上下单的是第二家,当他去到第一家酒店入住发现找不到时候,用户的体验可想而知了。
通过上面的工作,我们再次与业务方一起确认算法解决方案,我们将提供一个算法服务以计算两条数据是否属于同一家酒店,并给出“是/不是/无法确定”三种可靠的结果。同时我们的目标设定为提升运营效率,而不是完全解决酒店信息消歧的问题,通过算法与运营人员的结合实现业务目标。
此外,由于中文内容占据了大部分,我们计划先对中文的内容进行处理,而其他语言暂时不做处理,这样以最短的时间先处理收益最高的部分。
准备数据与模型训练
根据上面的理解,我们需要处理的是一个“分类”任务。而我们所能够拿到的数据非常有限,一条数据包含了两个酒店的信息字段:酒店名称、酒店地址、酒店经纬度。因为这三个字段相对比较齐全,在一期项目中能够处理较大范围的内容。
所以在准备数据环节,很重要的一步就是要去构建我们的特征。除此以外还有这两家酒店是否为同一家的标注。
当然第一步,我们要先处理前面提到的数据格式问题,把所有的数字都转换成阿拉伯数字,把所有的繁体字都转换成简体字。
1 | # 过滤掉最后面的英文字符,并进行数字转换(转成阿拉伯数字),大小写转换(转成小写) |
由于酒店的名称和地址都是相对较短的文字,不像长篇的新闻文本或者游记等文本具有非常明确的主题,而是有比较规范的标准和结构,所以我们先从分词上进行处理,以把名称和地址分别处理成更细粒度的词汇来进行对比,以增加特征的维度。
先来看名称分词:
我们先来举个例子,思考我们该如何对这些酒店名称进行对比,比如:
A:7天酒店(酒仙桥店)
B:如家酒店(望京店)
显而易见地,我们会把这些内容拆解成我们可以处理的更加有信息含量的词汇,即:
7天–>如家
酒店—>酒店
酒仙桥店→-望京店
所以要想对比准确,我们首先要对这些信息进行精准地分词。经过对大量酒店名称进行分析,我们把酒店名称分为如下结构化字段:

再来看地址分词:
同样的,在处理地址信息的时候也是按照这种方案,把地址拆解成更加详细、更加细粒度的词汇分别处理。具体分词方式见下图:

经过了上述分词的细化,我们有了20多个维度可以进行对比。当然,使用文字本身是没有办法直接进行对比的,我们还要把文字对比转化成数值类型,这里就要用到距离计算方法了。为了进一步扩展特征维度,我们对每一种特征又加入了三种距离计算方案:Levenshtein 距离、Jaro-Winkler 距离、q-gram 距离。
当然距离计算的方案有很多,如果你对距离计算感兴趣,可以在网上查阅相关的资料,在Python中有一个开源工具包Similarity 已经实现了大部分的计算方法。
1 | # 计算Levenshtein距离 |
模型训练与评估
准备好了特征,构建好了特征向量,我们就可以开始训练我们的模型了,到这里想必你已经十分清楚了,接下来就是要对具体的参数进行调节,以达到最佳的效果。当然参数通常已经有一组默认值,即便你不去修改,也能获得还不错的效果。
下面开始我们的模型训练:
1 | import xgboost as xgb |
完成了模型训练,但是所得到的结果可能并不能符合我们的需求,比如说准确率不够高,或者召回率不够高,这时需要我们仔细分析什么原因导致的这个结果,是我们的特征提取的不够多还是我们的数据不够好?具体原因需要具体分析,但总归会慢慢达到理想的结果。
像我们前面所说的,一个数据挖掘项目从训练到上线可能要经过多次迭代,从数据准备到模型训练再到模型评估,反反复复优化与验证,以使得我们的模型效果与业务需求趋于一致。
由于在我们的业务场景中,对准确率的需求更高,所以最终我们跟业务方达成一致意见:根据我们给出的“是”和“否”的概率值区间来判断是否足够置信,对于置信结果直接进入到合并或者新增环节;对于不那么置信的结果,仍然进入到人工审核环节进行二次校验。
这样,我们的一期工作就告一段落了,经过这个项目成功节省了60%的运营人力。当然,这个项目还远没有结束,在后面的工作里,仍然在继续优化结果,同时探索诸如英文酒店的消歧工作,使用更多特征与模型来处理细节的场景,这里就不再详细介绍。
- 总结
关于酒店信息消歧的实践,本课时就介绍到这里,这节课我重点讲解了在做数据挖掘的时候,对业务的深入理解过程,用一个实例来演示如何随着我们理解的深入,进而一步步处理我们的数据以及解决问题的。受到篇幅的限制,这节课程中我并没有放入全部的代码,这部分的详细代码后面会放在代码库,有兴趣的同学可以在代码库中查看。
在我们的工作中,算法部分往往成了最简单的环节,如何去处理需求、如何去构建特征、如何调整我们的思路才是我想要传达给你的。经过这一次实践,我希望你能够对数据挖掘在实际工作中是如何进行的能够有一定的理解。在后面的课程中,每一个模块也都会有实践课程,到时我再带你–攻破。
k-means 聚类算法
关于分类算法,我的讲解已经告一段落,从这一小节开始,我们进入聚类算法的学习。不知道你是否对前面讲解的“什么是聚类问题”还有印象,我在这里再简单介绍一下。
聚类算法属于无监督学习,与分类算法这种有监督学习不同的是,聚类算法事先并不需要知道数据的类别标签,而只是根据数据特征去学习,找到相似数据的特征,然后把已知的数据集划分成几个不同的类别。
比如说我们有一堆树叶,对于分类问题来说,我们已经知道了过去的每一片树叶的类别。比如这个是枫树叶,那个是橡树叶,经过学习之后拿来一片新的叶子,你看了一眼,然后说这是枫树叶。而对于聚类问题,这里一堆树叶的具体类别你是不知道的,所以你只能学习,这个叶子是圆的,那个是五角星形的;这个边缘光滑,那个边缘有锯齿……这样你根据自己的判定,把一箱子树叶分成了几个小堆,但是这一堆到底是什么树叶你还是不知道的。
- 一个例子
今天我要介绍的聚类算法称为K-means算法。首先我还是讲一个小例子来介绍一下这个方法的思路。
假设我们在罪恶都市里,有三个区域,每个区域有一个帮派进行管理。每个帮派都有一个大佬,每个大佬都管理着一群小弟,小弟们也有不同的等级。大佬给高级小弟安排任务,高级小弟再给低级小弟安排任务,而低级小弟们负责具体实施。有些小弟可能就在自己的区域活动,管理本区域内的店铺、保障本区域的治安;有些小弟可能会负责跟其他两个帮派联络、洽谈地盘、交易等业务。
这个时候来了个国民警卫队要整治这个区域,所以他们希望能够把帮派的关系理清楚,但是有那么多人该从哪里入手呢?最好的方案当然是先把大佬抓到,然后看一下他都联系谁就一目了然了。但是国民警卫队也不知道谁是大佬,那要怎么办?
假设国民警卫队已经知道这里面有三个帮派,那么国民警卫队派人在每个区设一个点,先随便抓一个人,最开始可能抓到的只是一个边缘小弟,甚至有一些可能抓到的两个是同一个帮派。但是没关系,先假设他是大佬,看跟他联系密切的都是哪些人,然后再从这些人里找一个跟其他人联系更密切的人。就这样反复寻找,最后终于找到每个帮派的大佬,而大佬联系的那些人自然就是这个帮派的小弟了。

算法原理
上面的小故事可以看到一些K-means的思想。接着我们来具体介绍一下算法的原理。假设我们的数据总共有m条,我们计划分为3个类别。如果我们的数据有两个特征维度,那我们的数据就分布在一个二维平面上,如果有十个维度,就分布在一个十维的空间中。
第一轮,先随机在这个空间中选取三个点,我们称之为中心点,当然选取的三个点不一定是实际的数据点。接着计算所有的点到这三个点的距离,这里的距离计算仍然使用的是欧氏距离,每个点都选择距离最近的那个作为自己的中心点。这个时候我们就已经把数据划分成了三个组。使用每个组的数据计算出这些数据的一个均值,使用这个均值作为下一轮迭代的中心点。
后面若干轮重复上面的过程进行迭代,当达到一些条件,比如说规定的轮次或者中心点的变动很小等,就可以停止运行了。
K-means的算法原理就已经解释完了,也是非常简洁、易于理解,但是这里面有一些问题需要解决。
如何确定k值
在算法实现的过程中,我们面临的问题就是如何确定K值。因为在日常的情况下,我们也不知道这些数据到底会有多少个类别,或者分为多少个类别会比较好,所以在选择K值的时候比较困难,只能根据经验先拍一个数值。
有一个比较常用的方法,叫作手肘法。就是去循环尝试K值,计算在不同的K值情况下,所有数据的损失,即用每一个数据点到中心点的距离之和计算平均距离。可以想到,当K=1的时候,这个距离和肯定是最大的;当K=m的时候,每个点也是自己的中心点,这个时候全局的距离和是0,平均距离也是0,当然我们不可能设置成K=m。
而在逐渐加大K的过程中,会有一个点,使这个平均距离发生急剧的变化,如果把这个距离与K的关系画出来,就可以看到一个拐点,也就是我们说的手肘。
如下图,我在这里虚拟了一份数据,可以看到在K=4的时候就是我们的肘点,在这个肘点前平均距离下降迅速,在4之后平均距离下降变得缓慢。但是这个方法只能适用K值不那么大的情况,如果K值较大,如几千几万,那迭代的次数就太多了,当然你也可以选择一个比较大的学习率来加以改进。不过总体而言,需要消耗一定的时间。

要确定K值确实是一项比较费时费力的事情,但是也是必须要做的事情。下面我们来看看这个算法的优缺点。
算法优缺点
优点
简洁明了,计算复杂度低。K-means的原理非常容易理解,整个计算过程与数学推理也不是很困难。
收敛速度较快。通常经过几个轮次的迭代之后就可以获得还不错的效果。
缺点
结果不稳定。由于初始值随机设定,以及数据的分布情况,每次学习的结果往往会有一些差异。
无法解决样本不均衡的问题。对于类别数据量差距较大的情况无法进行判断。
容易收敛到局部最优解。在局部最优解的时候,迭代无法引起中心点的变化,迭代将结束。
受噪声影响较大。如果存在一些噪声数据,会影响均值的计算,进而引起聚类的效果偏差。
尝试
和前面一样,在对K-means算法有了一定了解之后,我们来动手尝试通过代码来实际感受K-means算法的效果。这次我们使用的仍然是鸢尾花数据集,当然,由于是聚类,我们不需要使用标签数据,只需要使用特征数据就可以了。
1 | from sklearn import datasets |
通过运行上面的代码,会输出下面的这幅图像,当然,我们的鸢尾花数据集的属性有四个维度,这里输出的图像我们只使用了两个维度,但是仍然可以看出通过K-means计算出的中心点与数据分布基本上是一致的,而且效果也还不错。

扩展内容
做完了实践,我们再来看一下K-means都有什么样的衍生方法。由于K-means 也是一种非常不错的方法,所以有很多人为了改正它存在的一些问题进行了相应的研究。
K-means++
第一种是K-means++,这种方法主要在初始选取中心点的时候进行了优化。原本第一轮是随机进行选取的,但是由于算法可能会陷入局部最优解,随机地选取可能引起结果的不稳定。K-means++则是从已有的数据中随机地进行多次选取K个中心点,每次都计算这一次选中的中心点的距离,然后取一组最大的作为初始化中心点。
mini batch K-means
第二种mini batch方法,主要是基于在数据量和数据维度都特别大的情况下,针对运算变得异常缓慢的问题进行的改进。我们前面提到,K-means的收敛速度相对较快,所以前面几步的变动比较大,到了后面的步骤其实只有非常小的变动。mini batch的方案就是在迭代时,不再使用所有的点,而是每个集合中选取一部分点进行计算,从而降低计算的复杂度。
- 总结
写到这里,本课时的主要内容已经告一段落。这节课我们进入了新的算法类型–聚类算法的学习。在开头我又简单介绍了一下什么是聚类算法,聚类与分类有什么样的区别,接着就讲到了本节课的主角–K-means算法,它是一种非常简洁的基于划分的聚类算法。与前面一样,在介绍完算法的思想之后我加入了一段代码来实现快速上手,并且加入了一个画图的方法来展示聚类的效果。
在看完了这一课时的内容之后,你是否能在自己的工作中使用K-means来解决问题了呢?下一课时,我们将介绍另外一种聚类算法“DBScan”,到时见。
DBScan 聚类算法
上一节课我讲解了K-means算法,那是一种基于划分的方法。今天我要介绍一种基于密度的聚类算法:DBSCAN(Density-Based Spatial Clustering of Applications with Noise),依旧先来看一个例子。
- 一个例子
想象有一个很大的广场,上面种了很多的鲜花和绿草。快要到国庆节了,园丁要把上面的鲜花和绿草打造成四个字:欢度国庆。于是园丁开始动手,用绿草作为背景去填补空白的区域,用红色的鲜花摆成文字的形状,鲜花和绿草之间都要留下至少一米的空隙,让文字看起来更加醒目。
国庆节过后,园丁让他的大侄子把这些花和草收起来运回仓库,可是大侄子是红绿色盲,不能通过颜色来判断,这些绿草和鲜花的面积又非常大,没有办法画出一个区域来告知大侄子。这可怎么办呢?
想来想去,园丁一拍脑袋跟大侄子说:“你就从一个位置开始收,只要跟它连着的距离在一米以内的,你就摞在一起;如果是一米以外的,你就再重新放一堆。”大侄子得令,开开心心地去收拾花盆了。最后呢,大侄子一共整理了三堆花盆:所有的绿草盆都摞在一起,“国”字用的红花摞在一起,“庆”字用的红花摞在了一起。这就是一个关于密度聚类的例子了。

算法原理
上面的例子看起来比较简单,但是在算法的处理上我们首先有个问题要处理,那就是如何去衡量密度。在DBSCAN中,衡量密度主要使用两个指标,即半径和最少样本量。
对于一个已知的点,以它为中心,以给定的半径画一个圆,落在这个圆内的就是与当前点比较紧密的点;而如果在这个圆内的点达到一定的数量,即达到最少样本量,就可以认为这个区域是比较稠密的。
在算法的开始,要给出半径和最少样本量,然后对所有的数据进行初始化,如果一个样本符合在它的半径区域内存在大于最少样本量的样本,那么这个样本就被标记为核心对象。
这里我画了一幅图,假设我们的最小样本量为6,那么这里面的A、B、C为三个核心对象。
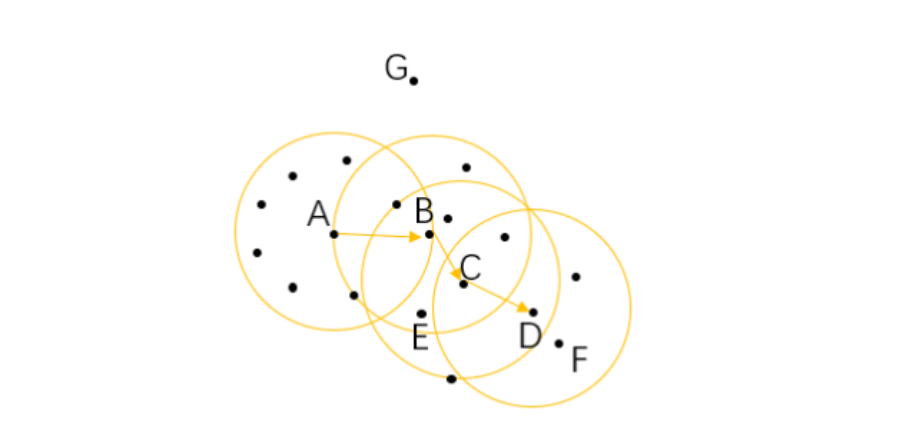
对于在整个样本空间中的样本,可以存在下面几种关系:
直接密度可达:如果一个点在核心对象的半径区域内,那么这个点和核心对象称为直接密度可达,比如上图中的A和B、B和C等。
密度可达:如果有一系列的点,都满足上一个点到这个点是密度直达,那么这个系列中不相邻的点就称为密度可达,比如A和D。
密度相连:如果通过一个核心对象出发,得到两个密度可达的点,那么这两个点称为密度相连,比如这里的E和F点就是密度相连。
一口气介绍了这么多概念,其实对照着图片都很好理解的,我们再来看DBSCAN接下来的处理步骤。
经过了初始化之后,再从整个样本集中去抽取样本点,如果这个样本点是核心对象,那么从这个点出发,找到所有密度可达的对象,构成一个簇。
如果这个样本点不是核心对象,那么再重新寻找下一个点。
不断地重复这个过程,直到所有的点都被处理过。
这个时候,我们的样本点就会连成一片,也就变成一个一个的连通区域,其中的每一个区域就是我们所获得的一个聚类结果。
当然,在结果中也有可能存在像G一样的点,游离于其他的簇,这样的点称为异常点。
DBSCAN的原理你只是看字面解释的话可能会有点迷惑,最好结合图片来进行理解,自己手动画一下图,来分析一下上面的几种概念,应该就比较容易理解了。接下来我们看看它都有哪些优缺点。
算法优缺点
优点
不需要划分个数。跟K-means比起来,DBSCAN不需要人为地制定划分的类别个数,而可以通过计算过程自动分出。
可以处理噪声点。经过DBSCAN的计算,那些距离较远的数据不会被记入到任何一个簇中,从而成为噪声点,这个特色也可以用来寻找异常点。
可以处理任意形状的空间聚类问题。从我们的例子就可以看出来,与K-means不同,DBSCAN 可以处理各种奇怪的形状,只要这些数据够稠密就可以了。
缺点
需要指定最小样本量和半径两个参数。这对于开发人员极其困难,要对数据非常了解并进行很好的数据分析。而且根据整个算法的过程可以看出,DBSCAN对这两个参数十分敏感,如果这两个参数设定得不准确,最终的效果也会受到很大的影响。
数据量大时开销也很大。在计算过程中,需要对每个簇的关系进行管理。所以当数据量大的话,内存的消耗也非常严重。
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差。
关于算法的优缺点就先介绍这么多,在使用的过程中十分要注意的就是最小样本量和半径这两个参数,最好预先对数据进行一些分析,来加强我们的判断。下面我们进入到动手环节,用代码来实现 DBSCAN 的使用。
尝试
今天我们使用的数据集不再是鸢尾花数据集,我们要使用datasets的另外一个生成数据的功能。
在下面的代码中可以看到,我调用了make_moons这个方法,在sklearn的官网上,我们可以看到关于这个方法的介绍:生成两个交错的半圆环,从下面的生成图像我们也能够看到,这里生成的数据结果,是两个绿色的半圆形。
此外,我们今天调用的聚类方法是sklearn.cluster中的dbscan。
1 | from sklearn import datasets |
使用上面的方法,会生成一份数据,我们最后还调用了plot方法把数据绘制出来,就是下图所显示的样子,就像两个弯弯的月亮互相缠绕在一起。

接下来,我们就开始使用dbscan算法来进行聚类运算。可以看到我为dbscan算法配置了初始的邻域半径和最少样本量。
1 | # eps为邻域半径,min_samples为最少样本量 |
最后,我们使用不同的颜色来标识聚类的结果,从图上可以看出有两个大类,也就是两个月亮的形状被聚类算法算了出来。
但是眼尖的同学可能看到,在月亮两头的区域有一些非常浅色的点,跟两个类别的颜色都不一样,这里就是最后产生的噪声点,根据我们设置的参数计算,这些点不属于任何一个类别。

- 总结
完成了动手环节,这节课的主要内容就介绍完了。这节课我们学习了聚类算法的第二个方法“DBSCAN”算法。它是基于密度的聚类方法,与前面讲的K-means不同的是,它可以很好地解决数据形状不规则的情况。
在算法原理环节,有几个概念需要你仔细去理解,只要明白了那几个概念,DBSCAN算法的核心也就可以掌握了。
总体来讲,DBSCAN是一个比较简单明了的算法,没有太多复杂的数学运算,但是在实践中要想用好DBSCAN 却不是十分容易,这主要是因为两个初始化参数比较难以设定,对于新手来说可能会有些困难,但是不要怕,你终会成长为一名有经验的数据挖掘工程师的。
实践 2:如何使用 word2vec 和 k-means 聚类寻找相似的城市
在第一个实践课(使用XGB实现酒店信息消歧)中其实没有涉及太多的代码,主要是以介绍思路为主。在这一课时中,我将提供一个较为完整的代码,带领你亲自实践一下。
理解业务
在旅行场景下,城市–我们通常称为目的地,是一个很重要的信息。根据用户对于目的地的偏好,我们既可以把目的地作为一个特征用于推荐系统中,也可以把目的地当作一个被推荐的信息直接推荐给用户。所以,我们有一个需求,就是把相似的目的地整理出来,然后可以通过这些相似目的地做相关推荐,或者是相关目的地的推荐。
理解数据
可以想到,这是一个比较典型的聚类问题,我们只要能够把相似的城市按照一定的相关性聚在一起,就可以完成我们的需求,当然具体的效果要根据结果不断地进行调整。
那我们就来看一下我们的数据。
思来想去我们只有很多目的地的名字,但这些目的地并没有什么统一标准的特征可以给我们做向量,那么该怎么去给这些目的地计算相关性呢?

这时不禁想到,我们有很多用户写过游记,这些游记里总会出现各种各样的目的地名字,对于相似的目的地,那用户所写的内容也会有一定的相似性,不管是地理位置接近,还是消费价位类似,或者是可以玩的内容存在一定的相似性。
总之,我们可以靠这些内容把这些城市的名字关联起来,而且不同于结构化的信息,游记是用户自己来写的内容,里面对于目的地的认知也是用户的认知,所以如果我们能够从中发现关联性,再应用到用户身上也是比较合理的。比如说“三亚”如果只是按客观属性来划分,那应该是“海边”,但是很多用户去三亚,除了看海本身,还有家庭出游等,这些是只能从用户的角度才会产生的认知。
这里,我们就要用到一个Word2Vec算法,它可以学习输入的文本,并输出一个词向量模型,经过Word2Vec算法处理之后,每一个词都会变成一个预设长度的数值向量。这个算法会在后面的章节进行更详细的讲解,这里我们大概知道它的功能就可以了。下面我们进入到具体代码实现的环节,看看如何训练一个这样的模型。
准备数据与模型训练
准备数据
我们获取所有需要用到的文本数据,在这里使用了全量的游记文本数据。我们首先要对数据进行清洗,去除掉异常的数据,比如内容过短、获取失败,或者是存在特殊字符、使用纯英文/泰语写的游记,等等。
完成了这个步骤之后我们要对文本内容进行分词,因为我期望Word2Vec最终构建的向量是词级别的。完成分词之后,我们把数据存储在文本文件中,其中每一行是一篇内容。
接下来就要训练我们的Word2Vec模型了。
训练 Word2Vec模型
这里我们使用了一个新的算法包:Gensim。不知道你是否还记得我在之前介绍过这个工具包,它主要用于从原始的非结构化文本信息中,通过无监督算法学习文本向量表达。这里面支持TF-IDF、LSA、LDA和Word2Vec等多种算法模型。来看一下代码。
1 | import gensim |
文本可以存储在多个文本文件中,存放在一个文件目录下,这里构建了一个迭代方法,循环读取目录下的所有文件。
我这里使用的文件目录为traindata,在traindata 下面有31个语料文件,其中每个有1G左右,如下图所示。
1 | def __iter__(self): |
在正常的情况下,我们会在model路径下看到几个文件。其中比较重要的两个,一个vocabulary是词典文件,记录了出现过的词汇以及词汇出现的次数;一个word2vec_gensim是生成的向量文件。
通过上面的方法,我们成功获取到了很多词汇的向量,这里我的词汇量大概有1000w左右。但是我们这次所需要的是寻找相似城市,所以对于那些非城市名字的词汇就没有什么价值了。
于是我们这里使用我们自己的城市词库与词汇表进行匹配,对于没有在词汇表中出现过的城市名称也没有办法计算,要把这部分剔除掉。不用担心,如果这么多的语料都没有出现过的城市也一定是没有人去过的城市。
训练 K-means 模型
下面我们就可以开始训练我们的K-means模型了。像我们前面用过的一样,K-means是在sklearn里面的一个模块。具体步骤如下所示。
1 | import gensim |
经过上面的步骤,我们就训练好了K-means模型,当然,经过反复尝试,最终确定的不是2000这个簇数量,而是使用了100个簇的结果。我们尝试了50、100、200、500、1000、2000等多个聚类的结果,经过我们最后的对比评估,100个簇的时候效果较好,于是我们最终选择了这个模型。
下图是我从结果中抽了一些簇的TOP结果生成的图片,可以看到聚类的效果还是很不错的。比如右下角那一簇基本都是日本关西的城市名字,左下角基本都是川藏线上的地点。

有了已经训练好的模型,我们就知道了这些相似城市的名称以及它们所属的簇。接下来我们要做的,就是把这些数据存储到数据库中,并在具体的业务中进行应用了。
当然,随着时间的推移,在积累了一段时间的数据之后,我们还要对模型进行重新迭代,以期望获得更好的结果。
- 总结
在这一节实践课程中,我着重介绍了整个模型训练环节的代码,其中主要写了两段代码,分别训练了Word2Vec模型和K-means模型。除了数据部分,这些代码几乎可以复制即运行。
到这一课时,关于聚类问题的内容就告一段落了,在数据缺少标注的时候,聚类算法是十分常用的,它可以帮助我们了解数据情况。当然,聚类方法也存在一些局限,还需要在日常的工作中多加练习,不断积累自己的经验。
线性回归与逻辑回归找到一个函数去拟合数据
经过了这么久的学习,我们终于结束了分类和聚类算法的相关内容,这一课时我将为你讲解关于回归算法的内容。
从标题可以看出来,我们这次课程会涉及线性回归和逻辑回归,这两个回归有什么样的含义呢?虽然都叫作回归,它们的处理方式有什么不同呢?带着这些问题,我们就开始本课时的学习吧。
- 一个例子
我们还是先从一个例子出发。想象你已经是一家公司的CEO,你的公司旗下有着优质的明星产品—种新型的保健品“星耀脑黄金”。为了让你的产品卖得更好,你要到处去投放广告,让大家都知道这个产品,激发大家购买的欲望。我们都知道投放广告是要花钱的,投放得越多,钱花得越多;知道的人越多,产品卖得越多。
根据历史累计的广告投放经费和销售额,我们可以画出一些点。

从这个图上可以看出,有些点位的收益相对较高,有些点位的收益相对较低,但是总体是一个正相关的关系。很自然地,你内心感觉需要画出一条线,就如下面图中的一样,来拟合投放广告经费和销售额的关系。
虽然它对于每一个单点来说都不是那么精确,但是它却十分简洁,有了这条线,你只需要设定一个广告费的数额,就一定可以算出一个销售额。这样当你在开股东大会的时候,就可以跟大家说:“我花这么多广告费是有价值的,只要我们的投放广告费达到多少多少亿,销售额也就能达到多少多少亿。”

经过了上面的步骤,我们其实就已经完成了线性回归的模型构建,即根据已有的数据去寻找一条直线,尽量接近这些数据,以用于对以后的数据进行预测,但是具体该怎么去找这条线呢?接下来我们看一下线性回归的原理。
线性回归的算法原理
首先我们要明确一下,什么是线性,什么是非线性。
线性:结果与特征之间是一次函数关系,比如表现在上面的例子中就是一条直线。
非线性:结果与特征之间不是一次函数关系,比如二次函数、三次函数,表现在图中是一条曲线,就是非线性的。
明白了这两个词,我们再来看回归模型是如何构建的。
比如在我们的例子中只有一个变量就是广告费,一个结果值是销售额。我们假设它们符合线性关系,那么我们先预设一个方程:
y=ax+b
所以我们只要根据数据求出a和b就完成了。
但是这里有一个困难,那就是我们的数据不是完全分布在这条线上的,那就需要一个方法来评估每次生成的线的效果,然后去进行相应的调整,以达到最好的效果。提到优化,这里又需要引入两个概念,让我慢慢介绍。
损失函数:不要被这个高大上的名称吓到,用一句话来解释,就是计算每一个样本点的结果值和当前的函数值的差值。当然具体到这里面,所使用的是残差平方和(Sum of Squares for Error),这是一种最常用的损失函数。如果你对具体的公式感兴趣,可以在网上查到它的具体信息。
最小二乘法:知道了损失函数,只要有一条线,我们就可以通过损失函数来计算假设结果为这条线的情况下,损失值的大小。而这里的最小二乘法就是要找到一组a、b的值,使得损失值达到最小。这里的二乘就是平方的意思。
到这里是不是对算法原理的理解就清晰很多了呢?那么我们再来看下它有哪些优缺点。
线性回归的优缺点
优点
运算速度快。由于算法很简单,而且符合非常简洁的数学原理,不管是建模速度,还是预测速度都是非常快的。
可解释性强。由于最终我们可以得到一个函数公式,根据计算出的公式系数就可以很明确地知道每个变量的影响大小。
对线性关系拟合效果好。当然,相比之下,如果数据是非线性关系,那么就不合适了。
缺点
预测的精确度较低。由于获得的模型只是要求最小的损失,而不是对数据良好的拟合,所以精确度略低。
不相关的特征会影响结果。对噪声数据也比较难处理,所以在数据处理阶段需要剔除不相关的特征以及噪声数据。
容易出现过拟合。尤其在数据量较少的情况下,可能出现这种问题。
逻辑回归(Logistic Regression)
到这里,你可能比较疑惑,为什么我标题里写的线性回归与逻辑回归,而上面一直在讲线性回归?别担心,我们马上就讲到逻辑回归的相关内容。
如果你已经了解了上面的线性回归,其实你就已经掌握了回归的方法,对于不同的回归算法,只不过是把对应的函数进行替换,把线性方程替换成非线性方程,或者其他各种各样的方程,以便更好地拟合数据。
而这里为什么要把逻辑回归拎出来呢?因为我们常说的回归算法是对比分类算法来说的,回归与分类有很多相似性,是有监督学习的两大分支。我们前面也介绍过,它们的区别是分类算法输出的是离散的分类结果,而回归算法输出的是连续数值结果,这两种结果可以通过一定的方法进行转换。
而逻辑回归就是这样一个典型的例子。它虽然叫作回归,但实际上却是用来解决分类问题,只不过在中间过程中,它使用的是回归的方法。
关于分类问题,假设一个二分类问题,只有一个变量x会引起结果标签的变化,那么把它俩表示在平面上就是下图这样的效果,前半部分的结果都是0,后半部分的结果都是1。

在逻辑回归算法中,使用了sigmoid函数来拟合数据。可以看出sigmoid 函数有点像是被掰弯的线性函数直线,这样函数的取值范围被限定在了0和1之间,很明显,使用这个函数去拟合上面的二分类结果要比线性直线好得多。

(图片来源于百度)
当然,选择sigmoid 曲线并不是偶然的,而是通过了精密的计算之后得出的方案。这里涉及了概率对数函数(Logit)的数学推导,这也是逻辑回归名字的来源。同时,在输出结果的时候,借助了极大似然估计的方法来对预测出的结果进行损失的估计。
当然,逻辑回归里所涉及的内容还有很多,其中使用了大量的数学推导,这里就不再做过多的介绍,如果你对推导过程感兴趣,可以进行更深入的学习。下面我们进入到动手环节,尝试在代码中使用线性回归来解决问题。
尝试
在代码环节,今天我们仍然尝试自己来生成数据。
首先,仍然是引入我们需要用到的包。
1 | import matplotlib.pyplot as plt |
然后,我们在这里生成数据。我假设了我们的数据偏移量为2.128,并且生成了100个点,作为我们的样本数据。
1 | def generateData(): |
生成完的数据可以在下面的图中看到。

在我们的主方法中,首先使用生成样本的方法生成了我们的数据,然后这次使用了sklearn中自带的数据切割方法对数据进行了切分,80%作为训练集、20%作为测试集。然后调用了线性回归算法,并使用预测方法对测试数据进行预测。
1 | if __name__ == '__main__': |
在最后,根据预测的结果绘制出了算法学习到的直线,如下图显示:

通过上面的代码,我们成功实现了使用线性回归算法来学习数据的规律,并拟合出一条直线。当新数据来了之后,直接把样本数据套入这个直线的方程中,就可以计算出结果。
- 总结
完成了动手环节,让我们再来回顾一下本课时的重点内容。在这节课中,我们介绍了回归方法,其中主要讲解了线性回归,同时简单介绍了逻辑回归。它俩虽然都有“回归”这个字眼,却存在着一些区别,当然,也有着一些相似。然后我们借助工具包实现了线性回归的代码调用,并绘制了相应的图像来展示回归的效果。
回归方法是非常常用的数据分析和数据挖掘方法,它的原理简单、运行快速,在很多数值型的预测需求中都发挥着巨大的价值。当然,除了这一小节中讲的线性回归和逻辑回归,还有很多不同的回归方程可以使用,以解决不同的问题。
实践 3:使用线性回归预测房价
这次的实践是针对我们的回归算法进行的练习。我们依然从数据获取、模型训练以及效果评估几个步骤来练习,看看如何使用线性回归来预测房价。
数据获取
与我们之前使用的鸢尾花数据集一样,波士顿房价数据集也是一个非常常用的公开数据集。你可以在下面的页面中下载数据。当然,该数据集也被纳入了sklearn中,你可以使用sklearn中的数据加载方法来获取该数据。
https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
从该页面,我们可以下载两个文件,其中housing.data是所有的数据、housing.names 记录了对数据的介绍。
从数据的介绍中我们可以知道,该数据集包含美国人口普查局收集的美国马萨诸塞州波士顿住房价格的有关信息,其中包含了506条数据,每条数据有14个属性。我们这次要做的就是把前面13个当作特征,最后一个房价中位数作为我们要预测的结果。下面的表格里,我列出了每个属性的名称和含义。
| 序号 | 属性名 | 属性含义 |
|---|---|---|
| 1 | CRIM | 人均犯罪率 |
| 2 | ZN | 超过25000平方英尺的规划住宅用地比例 |
| 3 | INDUS | 城镇非零售商业占地 |
| 4 | CHAS | 与查尔斯河之间的距离,在河边为1,不在河边为0 |
| 5 | NOX | 一氧化氮浓度 |
| 6 | RM | 每套住宅平均房间数目 |
| 7 | AGE | 1940年前简称用房的居住率 |
| 8 | DIS | 与波士顿五大商务中心的加权距离 |
| 9 | RAD | 上快速路的难易程度 |
| 10 | TAX | 每一万美元全额财产税的税率 |
| 11 | PTRATIO | 城镇小学教师比例 |
| 12 | B | 计算方法为1000(Bk-0.63)^2,其中Bk小时黑人所占人口比例 |
| 13 | LSTAT | 低收入人群比例 |
| 14 | MEDV | 居住房屋的房价中位数(单位:千美元) |
在代码中,我们首先还是引入我们需要用到的各种包。
1 | from sklearn.datasets import load_boston |
接下来我们看一下数据。这里由于使用sklearn可以直接加载数据,所以我就没有使用上面下载的数据。如果你想自己读取和处理数据,也可以直接从下载的文件进行加载。
使用上面的方法加载的数据集就会被存储在“boston”这个变量中,下面我们来看一下这是一个什么类型的数据。
输出结果如下,可以看到输出的类型是sklearn中的一个类型Bunch,经过查询我们可以知道Bunch 实际上是一种字典类型。
1 | <class 'sklearn.utils.Bunch'> |
那么接下来我们来查看一下该字典中的key值都有什么。
输出结果如下,我们可以看到字典的key值有5个,分别为数据、标签、特征名称、描述和文件名。其中的数据和标签就是两个数组了。
1 | dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename']) |
下面我们把特征名称输出出来看一下。
1 | print(boston.feature_names) |
从输出结果我们可以看到跟我最前面介绍的字段名称一样的结果,除了标签字段“MEDV”没有包含在这里面。
1 | ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' |
紧接着我们来看一下数据的规模,我们使用下面这个语句。
输出的结果如下,说明data字段有506行、13列,这也跟我们之前介绍的一样。
接下来我们要开始构建训练集和测试集了。先把数据和标签取出来,使用pandas的DataFrame 进行封装。
1 | X = boston.data |
查看描述功能输出的是对数据集中每个字段的一些统计结果,包括数量、最大最小值、均值、标准差等内容。根据描述方法的结果,可以对每个字段的数据分布有一个大致的了解。
1 | print(df.describe()) |
看完了具体的数据情况,使用我们前面已经使用过的分割数据集的方法,对数据进行切分,我这里设置的测试集比例为20%,我们总共有506条数据,那么就会有101条成为测试集,其余405条为训练集,代码如下:
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, |
模型训练
处理好数据集,接下来就可以进入到模型训练环节了。模型训练的语句很简单,而且训练的速度很快,因为我们的数据量很小。
1 | regressor = LinearRegression() |
我们知道,线性回归模型可以根据数据拟合出一条直线,使得损失值最小。既然有一条直线,那一定有截距和斜率,下面我们来看一下我们训练好的模型中,截距和斜率分别是多少。
1 | print(regressor.intercept_) |
斜率也就是我们的特征系数,所以每一个特征都会有一个系数。如果系数是正的,说明这个属性对房价提升有帮助;如果系数是负的,说明这个属性会导致房价下跌。
1 | Coefficient |
既然有了截距和斜率,下面我们就可以使用模型来对测试集进行预测了。为了便于了解预测的结果,我们把预测结果和实际的结果一起输出,对照看一下预测的效果。
1 | y_pred = regressor.predict(X_test) |
还可以使用下面的代码,用条形图的方式来展示对比,这里我们使用top25条数据生成条形图。
1 | test_df1 = test_df.head(25) |
生成的图像如下,其中蓝色的条纹是实际值,橘红色的条纹是预测值。整体看来,预测值与真实值的差距不大。

效果评估
模型训练好了,预测结果也已经产出了,接下来就进入效果评估阶段。
关于回归模型的效果评估有一些常用的指标,其实我们在前面的课程中也涉及了一点,这里我把几个公式也写在下面了,其实不是很难理解。
MAE (Mean Absolute Error)平均绝对误差。这个很简单,就是把预测值和实际值的差值计算出来然后求平均。

MSE(Mean Squared Error)叫作均方误差。这个应该很熟悉了,在介绍线性回归时,这个就是我们的损失函数。

RMSE(RootMean Squared Error)均方根误差。这个你可能觉得不就是在MSE上面开了个根号吗,有什么价值?对于数值来说其实没有太大的区别,但是开根号的作用是让解释性更强,因为MSE是平方后的结果。
就拿我们这一课时中预测的房价来说,单位是千美元,平方之后就不好解释了,再开根号就可以让计算单位回到和数据一致的状态。比如下面的结果中,我们就可以说误差是5.7千美元。

当然,在sklearn中也已经有了封装好的方法供我们调用,具体可以参见下面的代码。
1 | print('MeanAbsolute Error:', metrics.mean_absolute_error(y_test, y_pred)) |
- 总结
这节课中,我们使用了线性回归算法去实际处理了一个房价预测的问题,从数据的获取,数据的展示,再到模型训练和效果评估,算是一个比较完整的处理过程了。同时这节课里面也涉及了比较多的辅助代码,希望能够对你平时的工作或者学习有所帮助。
好了,这一节实践课就到此结束了,同时关于回归问题的讲解也告一段落。不知道你是否对这部分的内容有了一定的掌握。其实回归算法的理念很容易理解,只不过要找到适合你的数据的回归算法需要一些经验。
20 -Apriori 与 FP-Growth
这一课时,我们进入第四种数据挖掘算法–关联分析的学习。关联分析是一种无监督学习,它的目标就是从大数据中找出那些经常一起出现的东西,不管是商品还是其他什么item,然后靠这些结果总结出关联规则以用于后续的商业目的或者其他项目需求。
- 一个例子
不管你在哪一个数据挖掘课堂上,几乎都会听到这样一个“都市传说”:在一个大型超市中,数据分析人员整理了一整年的购物篮数据,来分析大家都买过什么样的东西。就在对购物篮的数据进行分析的时候,分析人员惊奇地发现,与“尿不湿”出现在一个购物小票上最频繁的商品竟然是啤酒。
这个结果背后的原因,是女人嘱托丈夫去超市给孩子买尿不湿,而丈夫通常会顺便买上一些自己喜欢的啤酒。超市发现了这个神奇的组合,于是毫不犹豫地把尿布和啤酒摆在了一起进行销售,以起到互相促进的作用。
关于这个故事是否真实发生过,我们保持怀疑的态度,但是这个故事确实反映了数据挖掘在商业运作中的价值。同时,购物篮分析也早已经是大型商超必备的技术手段。那么,如何发现这些潜在的价值,就用到了我们这一课时要讲的关联分析算法。
算法原理
要了解算法原理,首先我们需要对关联分析中的一些概念进行一下解释。
为了方便说明,我在这里编造了十条购物小票数据(如有雷同,纯属巧合),如下表所示。
表1购物小票数据
| 序号 | 购物小票 |
|---|---|
| 1 | 尿布,啤酒,奶粉,洋葱 |
| 2 | 尿布,啤酒,奶粉,洋葱 |
| 3 | 尿布,啤酒,苹果,洋葱 |
| 4 | 尿布,啤酒,苹果 |
| 5 | 尿布,啤酒,奶粉 |
| 6 | 尿布,啤酒,奶粉 |
| 7 | 尿布,啤酒,苹果 |
| 8 | 尿布,啤酒,苹果 |
| 9 | 尿布,奶粉,洋葱 |
| 10 | 奶粉,洋葱 |
项集(Item Set):第一个要介绍的概念叫项集,中文名称有点拗口,还是看英文比较容易理解。项集可以是单个的项,也可以是一系列项目的合集。在我们的例子中,项目就是啤酒、尿布等商品,一个小票上的内容就可以看作一个项集,通过关联分析得到的经常一起出现的啤酒和尿布可以称为一个“频繁项集”。
关联规则:根据频繁项集挖掘出的结果,例如{尿布}→{啤酒},规则的左侧称为先导,右侧称为后继。
支持度:支持度就是一个项集在数据中出现的比例。在我们的10条数据中,{尿布}出现了9次,那它的支持度就是0.9;{啤酒}出现了8次,啤酒的支持度就是0.8。{尿布,啤酒}的支持度是8/10=0.8,以此类推。支持度还可以用来判定一条规则是否还需要继续进行挖掘,如果支持度已经很低,再加入新的项肯定会更低,挖掘的意义不大。

置信度:置信度指的是在一条规则中,出现先导也出现后继的比例。我们可以用公式来看一下,置信度表示的是一条规则的可靠程度。

提升度:在置信度中,只考虑了规则中的先导与后继同时发生的情况,而对于后继单独发生的情况没有加以考虑。所以又有人提出了一个提升度,用来衡量先导和后继的独立性。比如在前面我们算出“尿布→啤酒”的置信度为0.89,这说明买了“尿布”的人里有89%会买“啤酒”,这看起来已经很高了。但是如果在没有买“尿布”的购物小票中,购买“啤酒”的概率仍然为0.89,那其实购买“尿布”和购买“啤酒”并没有什么关系。所以,提升度的计算公式如下:

如果提升度大于1,说明是有提升的。
确信度:最后一个指标是确信度,确信度指的是对于一条规则,不发生先导而发生后继的概率与这条规则错误的概率比值。公式如下:

上面的结果为1.82,这说明该条规则是真的概率比它只是偶然发生的概率高82%。
一口气看了这么多的概念和指标,下面终于进入我们的正题环节,看看在关联挖掘中的算法原理。
Apriori
关联挖掘的目标已经很明确了,而关联挖掘的步骤也就只有两个:第一步是找出频繁项集,第二步是从频繁项集中提取规则。Apriori算法的核心就是:如果某个项集是频繁项集,那么它的全部子集也都是频繁项集。
为了方便了解算法的效果,我预先画出了数据集中所有可能存在的项集关系,就如下图显示:

首先,需要设定一个最小支持度阈值,假设我们设定为0.5,那么高于0.5的就认为是频繁项集。然后,我们计算出所有单个商品的支持度,如下表所示:
表2一阶项集支持度
| 项集 | 支持度 |
|---|---|
| 尿布 | 0.9 |
| 啤酒 | 0.8 |
| 奶粉 | 0.6 |
| 洋葱 | 0.5 |
| 苹果 | 0.4 |
从这里可以看出,“苹果”的支持度达不到阈值,于是把它删掉。因此,所有跟“苹果”相关的父集也都是低频的,在后续的计算也不会涉及了,就是下图标绿色的这些。

接下来我们再计算二阶的项集支持度。
表3二阶项集支持度
| 项集 | 支持度 |
|---|---|
| 尿布,啤酒 | 0.8 |
| 尿布,奶粉 | 0.5 |
| 尿布,洋葱 | 0.4 |
| 啤酒,洋葱 | 0.3 |
| 啤酒,奶粉 | 0.4 |
| 洋葱,奶粉 | 0.4 |
到了这一步,后四个项集的支持度已经达不到我们的阈值0.5,于是也删掉。
接下来再计算三阶的项集支持度,这个时候发现已经没有可用的三阶项集了,所以算法计算结束。这时候我们得到了三组频繁项集{尿布,啤酒}、{尿布,洋葱}、{尿布,奶粉}。接下来从这三个频繁项集,我们可以得到三个关联关系:尿布→啤酒,尿布→洋葱,尿布→奶粉。根据前面的公式,分别计算这三个关系的置信度、提升度和确信度。
表4三个关联关系的置信度、提升度和确信度
| 关系 | 支持度 | 置信度 | 提升度 | 确信度 |
|---|---|---|---|---|
| 尿布 | 0.9 | 111 | ||
| 啤酒 | 0.8 | 111 | ||
| 洋葱 | 0.5 | I1I | ||
| 奶粉 | 0.6 | 111 | ||
| 尿布→啤酒 | 0.8 | 0.89 | 1.1 | 1.82 |
| 尿布→奶粉 | 0.5 | 0.55 | 0.926 | 0.89 |
到了这里,再根据我们的需求设定阈值来筛选最终需要留下来的规则。
FP-Growth (Frequent Pattern Growth)
根据上面的Apriori计算过程,我们可以知道Apriori计算的过程中,会使用排列组合的方式列举出所有可能的项集,每一次计算都需要重新读取整个数据集,从而计算本轮次的项集支持度。所以Apriori 会耗费大量的计算资源,这时候就有了一个更高效的算法–FP-Growth算法。
Apriori算法一开始需要对所有的规则进行枚举,然后再进行计算,而FP-Growth则是首先使用数据生成一棵FP-Growth树,然后再根据这棵树来生成频繁项集。下面我们来看一下如何构建FP树。
仍然使用上面编的购物小票数据,并对每一个小票里的项按统一的顺序进行排序,设置一个空集作为根节点。我们把第一条数据录入这个树中,每一个单项作为上一个节点的叶子节点,旁边的数据代表该路径访问的次数。下图就是我们录入第一条数据后的结果:

第二条数据与第一条一样,所以只有数字的变化,节点不会发生变化。
接着输入第三条数据。
输入完第二、三条数据之后的结果如下,其中由第一个洋葱和第二个洋葱直接画了一条虚线,标识它们是同一项。

接下来我们把所有的数据都插入到这棵树上。

这个时候我们得到的是完整的FP树,接下来我们要从这里面去寻找频繁项集。当然首先也要设定一个最小频度的阈值,然后从叶子节点开始,也就是最低频的节点。如果频度高于阈值那么就收录所有以该项结尾的项集,否则就向上继续检索。
至于后面的计算关联规则的方法跟上面就没有什么区别了,这里不再赘述。下面我们尝试使用代码来实现关联规则的发现。
尝试
在我们之前使用的sklearn算法工具包中没有apriori算法,所以这次我们需要先安装一个efficient-apriori算法包。而我们这次所使用的数据集,也就是我在上面提到的这个“啤酒尿布”数据。这个算法包使用起来也极其简单。
1 | '''记得安装包 |
通过上面的代码,我们就成功使用了apriori算法,对我们自己编造的数据集完成了关联关系挖掘,当在设置最小支持度为0.4的时候,我们找到了7条规则;而我们把最小支持度改为0.5以后,只剩下{啤酒}->{尿布}这一条规则了。你学会了吗?
- 总结
这节课里,我们介绍了两种关联关系挖掘的方法,其中Apriori使用了穷举的方式,而FP-Growth使用了树形结构来提高速度。关联关系挖掘通常使用的算法都非常简单,或者我们可以把关联关系挖掘转化成分类问题、聚类问题来解决都是可以的。
在这节课中,我们还介绍了关联关系的评估指标,不管是用什么算法来挖掘的关联关系,都可以使用这些指标来进行评估。
下一课时,我们会进入关联关系挖掘的实践课程,看看如何使用关联关系挖掘来解决业务中的问题。
实践4:用关联分析找到景点与玩法的关系
在前面的实践课程中,有的是注重对数据挖掘流程的讲解,有的是注重对算法实施的讲解。在这节课里,我们注重从实际的场景出发,使用数据挖掘流程来处理我们的景点与玩法的关系。接下来就让我们一起走进场景中,看看如何解决业务中的实际问题吧。
理解业务
在马蜂窝平台,有数以千万计的用户写下了他们旅行的感受,记录了他们旅行的瞬间;更有数以亿计的用户在浏览这些旅行相关的内容,以启发自己的旅行计划,制定可靠的旅行攻略。
但是在这些内容里,也存在着很多信息不准确、信息过时,或者有价值的信息过少等问题。用户想要从这些内容里找到自己所需要的信息,往往需要翻阅大量的内容,自己去判断哪些信息是准确的、有价值的,哪些信息是过时的、无意义的,这给有强烈的旅行需求的用户带来了一丝不便。
在旅行场景下,目的地和POI(Point of Information)是非常重要的特征。因为旅行是一定要依托于一个具体的地理位置,去到一座城、进入一家店、感受一片风光。而这些地理位置所具备的特征往往是不容易随着时间的变化而变化的,也不会因为某个人的特定感受而发生改变。
那么有没有一种可能,我们在浩如云海的数据中去挖掘那些景点的特色,并把这些信息沉淀下来,形成更加简洁和有价值的信息,以帮助用户提升效率呢?
这就是我们的业务需求,即如何用我们现有的数据去挖掘景点与玩法的关系,从而把景点与玩法关联起来。
理解数据
了解了我们的业务需求点,接下来就是要看我们都有一些什么样的数据。
POI 信息
首先最重要的当然是POI信息,一份标准的POI名称是一个良好的开始。围绕着POI名称,还有很多POI的其他信息,比如经纬度、POI的热度、POI所属目的地的上下级关系等,这些信息可以帮助我们对POI进行筛选。
如下图所示,目的地“丽江”下属又有很多的POI,比如丽江古城、束河古镇,这些都是已经结构化好的数据。

内容文本标签与POI
像之前提到的,在我们积累的数据中,最核心的是用户写的各种游记、攻略等文本信息。这些内容都是用户出行的真实体验,但正由于是个人的体验,所以即便是对于同一个景点,不同的人体验也会不同。
比如你在景点恰好碰到一个小偷,或者脾气暴躁的工作人员,那你肯定体验不好;又或者是你去沙漠恰好遇到了下雨,去森林恰好遇到了寒流/叶子全都落了等情况,每一个旅行的人都会有自己的感受。
但是,我们希望的是通过大量的数据进行分析,这样既可以获得大多数人的体验效果,又能够兼顾到小部分人的特殊感受,从用户的角度出发去评价一个景点,而不是一个景点本身的属性。
在内容方面,我们早前就已经建立了一套完整的标签体系,这套标签体系中包含了大大小小六百多个标签,并按照层级结构划分成三层,标签粒度从粗到细。
第一层标签诸如旅行景色、旅行时间、旅行玩法、美食等;第二层包含城市景观、人文景观、冰雪运动、户外运动等;第三层级包含滑雪、爬山、自驾等最具体的标签,这里面已经收纳了比较完善的玩法标签。
当用户上传了自己写的内容之后,我们的算法处理流程会使用自然语言处理算法和图像处理算法来分析每一篇内容,并为其标注标签。


在我们的用户所写内容中,通常有这样两种情况:
第一种,如上面这个用户写的,其中只涉及一个景点“绍兴鲁迅故里景区”,在我们的后台可以看到,通过我们的算法挖掘之后,这条内容已经关联上“新攻略、名人故居、人文景观、观光景点、9月”这样几个标签。其中的“名人故居、人文景观、观光景点”都属于玩法类标签。由于这条内容介绍的景点很集中,所以这条内容上的标签迁移到POI上面也相对较准确。

第二种情况,我们再来看一条数据。下图显示的这条内容讲解的是镇江一日游,其中涉及了很多的景点,还有出行路线等很多内容。

因此,在我们的后台可以看到,经过算法的挖掘之后,这条内容能够标注的标签也比较多:一日游、寺庙、日程、行程规划、观光景点、人文景观、公园、6月、春季、城市景观、博物馆等,都被标在了这条内容上面。
这里面的标签如果都跟金山寺做关联,那准确度肯定相对比较低,但是好在我们有众多的数据,可以进行交叉校验和筛选,最终那些出现较少的标签将会被筛掉。

了解了我们的业务和数据,我大致想到两个比较简单的构建景点与玩法关系的方案。
方案一:使用词向量模型构建词关系。
首先,不管是景点还是玩法,都是一个词汇,而这些词汇会经常出现在用户写的内容中,同时我们有大量的内容可供我们去构建预训练语言模型。
当然,现在网上有很多已经训练好的开源模型供大家使用,但是网上的预训练模型往往使用的是比较常见的新闻语料,对于我们这种垂直领域的内容适配效果不太好。
在模型的选取上,我们还是使用了前面课时所用到的Word2Vec词向量模型,而没有选取比如BERT,主要是受到机器条件的限制,如果要自行训练一个BERT模型,需要耗费大量的时间,而在效果上的差距不足以弥补时间上的损失。
关于Word2Vec的训练方式在实践2(如何使用word2vec和k-means 聚类寻找相似的城市)中已经讲解过,而这个算法我们也会在后面的课时里进行更详细的介绍。如果训练好了Word2Vec词向量模型,我们就可以使用在里面出现过的景点词汇与玩法词汇向量来计算关系的远近。
方案二:基于统计的关联关系挖掘。
除了上面的方案,第二个想到的方案就是根据我们算法,在每篇文章已经标注的玩法标签与景点信息中,计算景点与玩法共同出现的次数,然后通过关系挖掘中的支持度、置信度、提升度、确信度等指标进行筛选,以提升准确率。
当然,除了这两种方法,还有很多其他的方案,也可以把这种关联关系挖掘转换成分类任务等,这里暂且不涉及那些部分。
准备数据与模型训练
清楚了我们的业务需求和数据情况,并且已经有了一个大致的方案,那么接下来就是准备数据环节了。
首先我们需要准备好景点与玩法的词汇表,方便后面的筛选。玩法词相对比较简单,而景点词需要多费点心思,因为在景点POI中有很多重名的,或者别名,这需要在处理的时候特别注意。
针对方案一,我们需要准备的是所有分好词的内容,当然我们的分词系统需要加入景点与玩法词汇,以保证这些词可以优先被分出来。有了这些语料,就可以训练Word2Vec模型,然后根据景点POI和玩法词汇表,把Word2Vec中对应的词向量取出来,计算景点POI与每一个玩法词的距离,最终获得一个与POI词汇数一样的长度、与玩法词数一样维度的数据表,每一个维度存储POI与当前玩法词的向量距离。
这个方案的筛选,对于每一个POI,首先保留前30个距离最近的标签,然后依赖于人工观察,以确认我们所需要保留的最小距离,然后把小于我们所设定阈值的标签去掉。
针对方案二,由于所有POI和标签特征都已经做好结构化,我们只需要去遍历数据库中的所有数据,并把对应的POI和标签逐个进行加法运算,最终获得每个POI对应共同出现过的标签及其次数。
在筛选的过程中,我们会参考每个标签和POI出现的绝对次数,配合支持度、置信度等几个指标设定阈值,最终保留我们认为足够置信的结果。下图就是我们对“洪崖洞”这个POI统计后的结果。

评估与应用
说起来两个关联挖掘的方案都不算太难,不过结果却是非常有价值的。当然,只产出了上面的内容只能算是一个良好的开端,这些东西最终要落地应用,还需要经过很多步骤。
首先,我们与运营一起对两个方案进行了效果的评估,这个评估主要依赖于人工校验的方式,借助人工的先验知识,来抽样检查结果的准确性。其中,方案二所挖掘到的效果相对较好,所以我们把它的结果作为基准数据,同时把方案一的结果作为辅助校验与方案二的结果融合在一起。
完成了评估,我们也就可以用这些数据去做一些有意思的事情,比如使用这些数据构建一个知识图谱。既然是针对大量的景点POI与玩法挖掘的关联关系,一个景点可以与多个玩法发生关系,一个玩法也可以与多个景点发生关系,一个目的地下可以有多个景点,这就构成了一张庞大的网状结构。所以可以想到的就是把这些数据沉淀在图数据库中,去建设一个知识图谱,以方便我们进行查阅。
下面这张图展示的就是我们构建的目的地知识图谱的展示页面,当然知识图谱中还包括了大量的其他技术手段,本小节所用到的关联关系只是其中的很小一部分,或者算是初步的骨架,如果后面有机会我们再去深入讲解相关的课程。

当然,景点与玩法的关系应用不只是图谱这一种形式,我们通过挖掘的手段获取了大量景点的玩法信息,这些信息来自无数的作者贡献的内容。其中所蕴含的丰富知识是有限的运营人员所无法覆盖的,所以这在我们的景点POI榜单生产、内容生产供需分析,甚至是推荐搜索系统中,都在持续发挥着作用。
- 总结
这一小节讲到这里就告一段落了,这节课里面没有涉及任何代码,而是主要从整个业务流程上讲解了具体去做一个关联分析项目的过程。
我们从提出去寻找景点与玩法的业务需求开始,深入理解了我们的业务与数据情况,接下来是制定我们的方案并实施。关联分析的方案几乎是基于统计来进行计算,所用到的方法通常都非常简单,只要我们解决了工程性的问题就不会有太大的难度。但是它所蕴藏的价值是巨大的,在最后,我简单介绍了我们所获得的结果与应用,并展示了我们目前的知识图谱页面。
通过这一小节的学习,不知道你是否又获得了一些启发呢?在你的日常工作中,是否也存在着可以进行关联关系挖掘的场景呢?
TF-IDF:一种简单、古老,但有用的关键词提取技术
其实到上一节,数据挖掘的四种常见问题和算法,我们已经学习完了,从这一小节,我们进入到自然语言处理的相关学习。
我觉得自然语言处理是数据挖掘领域最有意思、最有深度的部分。与我们前面算法所处理的结构化数据不同,自然语言是由人们自由表达的内容,显然是一些非格式化的数据,并且存在着歧义、多义、无序等特点,所以要从这些语言文字中挖掘出有价值的信息也不是一件简单的事情。
但是算法就是如此美妙,能够完成这种看似不可能的任务,虽然目前的效果还不能说尽善尽美,不过随着技术的进步,我们也确实看到这些算法在不断地演化、进步,相信在不久的将来,一定能够达到足够优秀的水准。
自然语言处理的历史
一切技术的发展都是螺旋式上升的,自然语言处理技术也依循了这样一个路径。
早期阶段(1956年以前):自从提出了著名的“图灵测试”,人工智能的概念就逐渐进入了研究者的视野。人类的语言,作为人类及其特殊的智慧结晶,让机器理解人类语言当然也是人们迫不及待想要攻克的难题。香农曾提出过概率模型来描述语言,而乔姆斯基提出了基于规则的上下文无关文法。这一阶段还没有太明确的产出,只有一些简单的拼凑。
快速发展(1957-1970):随后自然语言处理进入了快速发展期,这个阶段两大派别分别从概率模型和规则模型分别进行了深入的研究。同时,一些非常有影响力的概念也在这个时期提了出来,比如神经网络方法和知识库方法(也就是现在知识图谱的原型)。在这个阶段,基于规则的方法占据了主要地位,使用规则构建机器翻译已经小有成效。但是,自然语言处理的难度仍然十分高,众多研究者的热情随着效果的持续不佳逐渐降低了下来。
瓶颈期(1971-1993):进入70年代以后,很多相关的研究都停滞了,不过仍然有小部分研究者在持续进行研究,这个阶段产出的隐马尔科夫模型(HMM)为后面的复苏奠定了基础。
再次爆发(1994年之后):到了90年代,自然语言处理上的两大困难得到了极大的突破,第一个是随着硬件的升级,运算和存储能力大大增强,原来对硬件设备要求很高的算法可以很快地运行了;第二个是随着互联网的兴起,获取语料变得十分简单,而且对这方面的需求也大大增加,所以自然语言处理再次进入研究的爆发期。尤其是最近几年,深度神经网络不断成熟,自然语言处理技术也随之飞速地发展,各种各样的自然语言处理任务的处理效果都有了很大的提升。
我们这一小节要介绍的TF-IDF算法就是自然语言处理早期的产物,而下一小节要介绍的Word2Vec算法则是当前最流行的预训练语言模型的前身。好了,接下来让我们进入正题,看一下TF-IDF是如何计算的。
算法原理
TF-IDF (Term frequency-inverse document frequency),中文翻译就是词频-逆文档频率,是一种用来计算关键词的传统方法。
在早期处理诸如新闻文本的时候,由于文本的长度一般都很长,要想从内容中获取有价值的信息就需要从中提取关键词,进而使用关键词来表示这篇内容的核心价值。同时,提取关键词也可以看作一种降维的方式,提取完关键词之后,使用关键词再进行文本分类等算法。
那么TF-IDF为什么能够较好地提取关键词呢?下面我们就来看一下。
考虑一下,我们是一家新闻机构,每天都有大量的新闻要发布,根据这些内容,我们来看一下如何计算TF-IDF。
TF (Term Frequency):TF的意思就是词频,是指某个词(Term)在一篇新闻中出现的次数。当然,新闻的长度各不相同,为了更加公平,我们可以对TF做一下标准化,用词频除以这篇新闻的总词数。
但是,单纯地使用词频来作为关键词的特征明显是不合理的,考虑一些非常常见的词,比如说“你的”“我的"“今天”这种词,可能在一篇新闻中会反复出现,但是这种词明显并不重要,于是有了IDF。
IDF (Inverse Document Frequency):IDF称为逆文档频率,这个词我们用公式来看一下可能更容易理解。
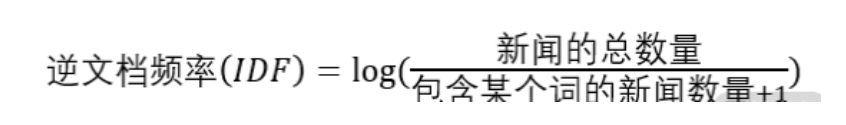
如果一个词越普通,那它越可能出现在所有的新闻中,那么分母就越大,IDF的值就越接近0。
当然,单纯地使用IDF作为关键词也不靠谱,如果你自己随便造了一个没人听过的词加在新闻中,比如说“墎碶”,那么上式的分母非常小,所得到的IDF值会非常大,但是这个词明显没有什么意义。
于是,TF-IDF就是结合了这两个结果,使用TFxIDF作为最终的结果,可以看到,TF-IDF与一个词在新闻中出现的次数成正比,与该词在整个语料上出现的次数成反比。
经过上面这两个值的计算,并把两个值乘起来,TF-IDF就计算结束了,是不是非常简单明了?接下来我们看一下TF-IDF的优缺点。
算法优缺点
非常明显,TF-IDF的优点就是算法简单,十分容易理解,而且运算速度非常快。
TF-IDF也有比较明显的缺点,比如在文本比较短的时候几乎无效,如果一篇内容中每个词都只出现了一次,那么用TF-IDF很难得到有效的关键词信息;另外TF-IDF无法应对一词多义的情况,尤其是博大精深的汉语,对于词的顺序特征也没办法表达。
当然,在传统的基于统计的自然语言处理时代,TF-IDF 仍然是一种十分强大有效的关键词提取方法。
了解了TF-IDF算法的基本原理,我们接下来就动动手,用代码来实现TF-IDF算法。这次我们使用的是Gensim算法工具包,这个工具包我们在前面也介绍过,其中包含了Word2Vec等自然语言处理常用的算法工具。同时,里面也内置了一些语料供我们测试使用。
尝试
这里我们使用text8数据包,是一个来自Wikipedia的语料,大小有30M多,总共1701条数据。第一次使用需要下载,可能要花费一点点时间。
1 | import gensim.downloader as api |
在输出的结果中,一条数据就是一篇内容的所有词的TF-IDF值,其中每一个单元有两个值,左边是这个词的ID,右边是这个词的TF-IDF值。细心的你可能会发现,我们输入的内容长度可能会与输出的结果长度不一致,这是因为Gensim中的TF-IDF算法会过滤停用词、去掉单个的字母等,所以最终结果会缺失一部分。当然,那些词我们认为也不会是关键词,所以在提取关键词的时候也不需要关心。
我们在例子中使用的是英文的语料,如果你想要处理中文,可以安装一个jieba分词工具,然后使用jieba分词工具把中文语料进行切分,之后的处理步骤就与前面的过程一样了。
1 | import jieba |
在提取关键词方面,单纯地使用TF-IDF的效果还不是特别好,可以在TF-IDF的基础上,叠加词性、词长度、词位置等特征信息以进行优化。除了TF-IDF,还有很多关键词提取的方法,如果你对这方面有兴趣,可以在网上进行更深入的查阅。
- 总结
这一小节,我们开始涉及了一点关于自然语言处理的知识。我在这一小节讲解了一个比较古老,但是很实用的关键词提取算法TF-IDF,它的原理十分简单、易于理解,通过TF-IDF的计算,保留了那些出现频率高的词汇,同时又能够打压那些比较普通的词汇,即便是现在,这个算法仍然有比较广泛的应用。
下一小节,我们将讲一下更加前沿的词嵌入技术“Word2Vec”算法。
word2vec:让文字可以进行逻辑运算
在上一节课,我们简单介绍了自然语言处理的发展历史,然后讲解了TF-IDF算法的计算过程,那是一个非常古老的关键词计算方法。今天,我们要学习自然语言处理的再次爆发期产生的一种新算法:词嵌入算法。
简单来说,词嵌入算法就是使用一个低维度的向量来表示一个词,并且距离相近的向量在实际的词含义上也是相近的,比如说“炸鸡”的向量与“啤酒”的向量距离就要比“炸鸡”的向量与“收音机”的向量要近。
不仅如此,词嵌入获得的向量还具备数学运算的关系,比如“女人”词向量+“王冠”词向量=“女王”词向量。这是不是很神奇?所以这个到底是怎么实现的呢?我们要先从词向量的表达说起。
独热编码
在计算机中的所有运算都是数学运算,怎么把我们的自然语言处理转换成一种数学形态,一直是一个困难的问题。文本的长度本身就不确定,而且文本中的词每次也都不一样,因此很难有非常有效的编码方式来表达文本。
不过有一种使用了很长时间的编码方式就是独热编码(One Hot),独热编码是一位有效编码,其中的每一位都用来存储一个状态。
现在来举个例子,假设我们的数据里只有“男”“女”两个字,那么我们的独热编码就像下面写的这样,一共有两位。
| 男 | 01 |
|---|---|
| 女 | 10 |
独热编码的好处就是能够让我们的离散的文本数据都变成定长的数据,方便各种算法的处理。但是它的缺点也很明显,那就是过于稀疏。假设我们的语料库是最近一年的新闻,那可能会有上千万的词,哪怕经过了各种过滤,仍然会有上百万的长度,每一个词的向量只有一位是1,其他几十万位都是0。
比如:
特朗普[1,0,0,0,0,0,....,,0,0,0]
拜登[0,1,0,0,0,0,....,0,0,0]
希拉里[0,0,1,0,0,0,.....,0,0,0]
克林顿[0,0,0,1,0,0......,0,0,0]
奥巴马[0,0,0,0,0,1......,0,0,0]
这样的维度对于我们的算法来说实在是一个大灾难,不管是存储还是运算的开销都非常大。同时,独热编码也没办法记录词与词之间的关系。
随着研究的深入,产生了一种分布式表示的方法来解决独热编码的问题。它的想法是通过对文本词的训练,把每个词都映射到一个比较短、但是稠密的向量上来。所有的词向量构成了向量空间,从而可以使用统计学方法来研究词之间的关系。具体要把词向量的维度设为多少,需要我们在训练的时候指定。
比如我们用几个维度来表示上面的几个人物名词:
| 特朗普 | 拜登 | 希拉里 | 克林顿 | 奥巴马 | |
|---|---|---|---|---|---|
| 性别 | 0.99 | 0.99 | 0.01 | 0.99 | 0.99 |
| 年龄 | 0.7 | 0.9 | 0.7 | 0.8 | 0.6 |
| 肤色 | 0.3 | 0.1 | 0.2 | 0.2 | 0.9 |
| 权力 | 0.8 | 0.3 | 0.4 | 0.9 | 0.8 |
| 财富 | 0.8 | 0.7 | 0.4 | 0.9 | 0.2 |
经过上面表达的转换,我们就已经把几个词向量由十分稀疏的独热编码转换成了一种稠密的向量。当然,在我们的模型中没有办法去解释每个维度都是什么意思,并且每一个向量只对应一个词,每个词的表达向量是不同的,映射之后的向量包含了原来的信息。
把原本的词向量映射到这个相对低维空间的过程就称为词嵌入(Word Embedding)。但是词嵌入之所以能够记录词与词之间的关系,主要是因为在训练的时候使用了上下文关系来进行学习。比如说,在我们的语料中经常出现“我的宠物猫是一只可爱的小动物”我的宠物狗是一只可爱的小动物”,那么“宠物猫”和“宠物狗”这两个词的词向量就会非常接近,这是因为它们的上下文都很类似。
说到这里,基本铺垫都已经介绍完了,你大概能够明白词嵌入和词向量的概念,那么接下来我们要进入正题,看看Word2Vec算法是如何计算出我们的词向量的。
算法原理
我们前面讲过人工神经网络,而Word2Vec最核心的其实就是采用了神经网络算法,当然它是浅层神经网络,只包含了一层隐藏层。它的网络结构如下图:

输入层是我们去掉了某些部分的语料编码,在这里也就是One Hot编码,输出层的维度与输入层一样,所需要预测输出的是在输入层被去掉的部分。
所以这里有两种方案,第一个是去掉某个词,输入层是这个词的上下文,这种方法叫作
CBOW(Continuous Bag Of Word),输出层也就是要去预测这个词;第二种方案是去掉上下文,用这个词作为输入层,这种方法叫作 Skip-Gram,输出层需要预测上下文。
对于这个网络中,从输入层到隐藏层是没有激活函数的,也就是一个线性关系。这里需要注意的是Word2Vec所获得的模型并不是我们这个网络的最终结果,而是在训练完成之后,把隐藏层的权重矩阵获取出来,即形成了我们的Word2Vec算法的结果。
通过这个方法,我们语料中的每一个词都获得了一个预设维度的向量,由于隐藏层的维度要比onehot 向量的维度小很多,这也起到了很好的降维作用。
讲到这里,关于Word2Vec最浅显的原理已经介绍完了,其余的部分就是关于神经网络的一些原理,我们已经在前面的课程介绍过。当然了,关于这个算法的细节部分这里也没有进行太多的讲解,这些内容你如果有兴趣可以通过相关的论文来进行学习。
算法优缺点
比起很多传统方法,Word2Vec考虑了一些上下文信息,以及词语的顺序信息,所以比起传统的基于词语统计的方法要准确很多。而且Word2Vec方法成功降低了向量维度,可以适配后续的各种自然语言处理任务,通用性很强。同时,这种预训练的思想为大家的下一步研究提供了良好的思路。
当然,Word2Vec产生的词向量是一对一的,所以一词多义的问题仍然没有办法解决。
尝试
对于Word2Vec的代码使用方法,我们前面其实已经介绍过了,在实践课2中我们使用了Word2Vec 为K-means聚类算法提供了聚类的向量材料。这里我把代码粘过来,再回顾一下使用的过程。
1 | import gensim #引入gensim |
文本可以存储在多个文本文件中,存放在一个文件目录下,这里构建了一个迭代方法,循环读取目录下的所有文件。
我这里使用的文件目录为traindata,在traindata 下面有31个语料文件,其中每个有1G左右。
1 | #构建一个迭代器 |
- 总结
看完了代码部分,这节课又将告一段落了。这是我们关于自然语言处理的第二节课程,当然这两节课程只是介绍了自然语言处理浩如烟海的知识中很小的一部分,但是我希望通过这两小节课程的学习,你能够对自然语言处理有一个初步的了解。
在这节课里面,我们介绍了Word2Vec算法,从原来的OneHot编码讲起,到Word2Vec的基本原理以及Word2Vec的两种工作模式。不过,这里所介绍的都是最浅显的部分,关于Word2Vec算法还有很多的细节我们没有涉及。当然了,在自然语言预训练模型方面,现在已经有了很多更加先进和优秀的算法,比如BERT、GPT等,如果你对这方面有兴趣,可以继续学习自然语言处理相关的课程。
下一课时,是我们最后一节实践课–使用fastText进行新闻文本分类。
实践 5:使用 fastText 进行新闻文本分类
你好,欢迎来到第24课时,这是我们的最后一节实践课,也是我们的数据挖掘思维与实战的最后一节正课。在这节课中,我将为你讲解数据挖掘在自然语言处理领域最典型的应用–文本分类,并带领你一步步解决文本分类的问题。话不多说,让我们开始课程吧。
fastText算法
这里我们先简单介绍一下fastText,因为我们在前面没有提到过这个算法,你可能有点疑惑这是个什么东西。fastText与我们上一课时介绍的Word2Vec的CBOW方法十分类似,可以说是在Word2Vec的基础上探索出来的。它的结构与Word2Vec非常类似,也是一个浅层神经网络模型,有一个输入层、一个隐藏层和一个输出层,其中输入的也是文本的向量。
当然了,它们也有很多区别。首先,fastText是一个分类算法,是有监督的,输出层输出的是一个分类标签。另外,在输入层,除了词本身的向量,还增加了n-gram方法来把词划分成若干个子词。比如说设置n-gram为2,“拉勾教育”可以分成“拉勾”“勾教”“教育”,这些子词的向量也加入输入向量中,这样对于低频词更友好一些,它们的字符级别n-gram可以与其他词共享信息量,并且在新的数据集上面,对于词库中没出现过的词,可以使用n-gram来为它们叠加向量。
除了这些,fastText的训练非常迅速,虽然是浅层神经网络,但是分类效果可以接近深度神经网络。使用BERT(流行的深度神经网络自然语言处理算法)要花几十个小时才能训练完的任务,使用fastText 可能只需要几分钟。
关于fastText的简单介绍就先说到这里,接下来我们进入数据挖掘的环节。
理解业务与理解数据
新闻会涉及方方面面的内容,是一种泛领域的内容信息。要给新闻分类,我们首先要有一套分类体系。我们期望能够构建一套完整的、可以覆盖所有新闻内容的分类体系。这个分类体系有着自上而下的结构,由粗粒度到细粒度一层一层逐渐展开。
就如下图展示的,我们需要构建一个有三个层级的分类体系。
一级分类粒度最粗,覆盖面也最广,每一个分类标签都囊括了一大波内容,几乎所有的内容都可以被分为其中的一个或多个类别。
二级分类标签相对较细,是在一级标签的基础上进行的扩充,比如说在体育下面又细分成足球、篮球、乒乓球、羽毛球等二级分类标签。二级标签开始,就可能存在覆盖不全面的问题,有些新闻可能无法找到合适的二级分类标签为其标注,所以我们在每一个组二级分类下面增设一个“其他”类别。
三级分类又在二级分类的基础上进行了扩充,粒度更加细致。相应的,三级分类也都增设“其他”类别。

很明显,我们的分类体系是多层级、多标签、多分类的,在具体的实现上,很难依靠单一的算法直接给出结果。当然,在动手去做之前我们还需要对数据有一些了解。
对于新闻,我们多多少少都有些了解。通常来说,一篇新闻都会有一个标题、一篇正文,还有发布时间和发布源。在正文中,可能会有一些配图,这些是新闻的基本内容。对于新闻最重要的正文部分,一般也都会有相对比较固定的写作格式,以及相对标准的新闻内容。比如事件的起因、经过、结果、重要人物、发生的时间、地点等要素。这些信息在新闻中占据了很重要的信息量,在做分类的时候,如果能够恰当地提取和使用这些信息,将会使你的准确率大大提升。
接下来我们就看一下,如何去构建一套完整的数据处理和模型预测体系。
准备数据与模型训练
要想使用fastText对新闻文本进行分类,我们需要对数据做一些预处理。让我们先来看一个简单版本的分类。
这是 fastText 的官方地址:https://github.com/facebookresearch/fastText
这里讲解了如何使用fastText的基本内容。需要注意的是,fastText需要用到C++lib的支持,如果你的电脑上没有安装C++lib库,可能会报错。
下面是官网介绍的安装方法:
1 | $ wget https://github.com/facebookresearch/fastText/archive/v0.9.2.zip |
完成了fastText的安装之后,可以直接使用命令来进行模型的训练。我们前面说了,fastText除了可以进行文本分类以外,还可以用来获取中间产物Word2Vec的词向量表。
如果要使用fastText 获得词向量,可以使用下面的语句,其中的data.txt是我们需要输入的训练语料。训练完成后会获得两个文件“model.bin”和“model.vec”。其中bin文件是用来存储模型参数以用来追加训练的,vec文件是词向量文件。
1 | $ ./fasttext skipgram -input data.txt -output model |
如果要追加训练,可以使用下面的语句,queries.txt是新的文本文件,其中可能包含了模型中不存在的单词。
1 | $ ./fasttext print-word-vectors model.bin < queries.txt |
对于文本分类,我们则需要使用下面的语句了,这里需要注意的是,train.txt文件是我们的训练语料,它需要被处理成固定的格式,其中每一行是一条训练数据,在每一行的开头加入数据的标签,并在标签上加入前缀“label”,多个标签之间使用空格隔开。比如说我们的新闻标签“科技”“娱乐”,就写成“label 科技label娱乐”。
1 | $ ./fasttext supervised -input train.txt -output model |
在训练完成后,我们仍然会得到与上面相同的文件,只不过这次bin文件可以用来对新数据进行预测了。除了直接使用语句来进行训练,我们当然也可以在Python 中使用 fastText算法包来进行模型的训练。
一个完整的大型分类模型迭代流程
当然了,在我们实际的生产环境中,问题往往没有这么简单,多级多标签多分类要想获得还不错的结果,需要对各个环节进行多种尝试和处理。在下面,我画了一张关于整个数据处理和模型训练的迭代流程图,基本上涵盖了我们整个算法模型的处理过程,让我们来看一下其中都有哪些步骤。

基础数据层
首先,在最左侧的是我们的基础数据,前面我提到过,新闻中有很多特征载有非常重要的信息,比如说人物、地点、时间等,这些都属于词库的范畴,如果我们有比较完善的词库,其实会节约很多时间并取得较好的效果。
其次是我们的标签库,这个不需要过多解释,这个库就是来维护我们需要进行学习和预测的标签。样本库对我们的样本进行管理,在这里就是存储了我们的新闻信息以及我们所需要用来训练的相关数据。
最后一个抓取则是一种手段,有些时候我们自己的数据可能存在着各种各样的问题,需要借助一些外部的数据来支持我们的工作,那么就可能会用到抓取的手段。
基础特征
完成了基础数据的构建,下一步就开始构建一些基础特征,这一环节还可能包括对数据的分析等。
在这个环节,我们也需要用到很多算法或者策略。比如说对于文本进行分析,提取其中的关键词、实体词,对图像信息进行识别;再比如识别其中的人物或者场景,识别图像的质量,等等。
在这一步,我们把很多原始的数据进行了算法加工,从中提炼出一些信息含量更高的特征信息,以方便下一步有针对性的特征选择与向量化。
特征选择与特征向量化
在特征选择与向量化环节,主要是针对后续可能会用到的模型来进行针对性的处理。比如说对于SVM 算法,那我们可能需要对关键词信息进行加工以适配SVM算法;而对于fastText算法,相对比较简单,可以只用分词后的结果,当然也可以在其中拼接上重要性更高的实体词等信息,来加强学习的效果。
在这一步,我们要针对后面即将实施的算法实验来针对性地选择特征,并把特征构建成算法可以接收的形式。
算法选型
紧接着,我们就进入了算法选型的步骤。对于多级分类,我们可以采用自顶向下的方法,先进行最高级的分类,确定一级分类,再去构建一个模型来处理二级分类,以此类推。
也可以采用自底向上的方法,先使用一个大分类器或者若干个二分类器,去预测所有的最底层分类,然后再向上总结。
当然,除了这两个方案,还有很多可以处理模型融合的方法。除此以外,对于有众多分类标签的分类器,我们也可以叠加一层规则系统,来对一些特殊的情况进行修正和处理。
在这一步,我们还需要对各种算法的效果进行对比,并确定我们到底要使用什么样的算法模型来解决其中的每一个问题。
模型评估与优化
与我们的算法选型十分紧密的下一个环节,就是整个评估和迭代环节。其实我们每一个算法模型,都会有相应的准确率、召回率等指标来评估模型的效果。同时,根据效果的反馈,我们来决策该如何融合各个模型,并有针对性地来进行模型迭代。
比如说,如果我们发现“娱乐”下面有一个三级分类为“动漫”,它的分类结果与“文化”下面的“漫画”很难进行区分,这时候就需要考虑是否要把这两个合成为一个标签,或者是否有什么特征可以区分这两个内容。
修饰处理
解决了上面的细节问题,我们就可以对模型的结果来进行一些最终的修饰处理了。一个大型的分类体系可能不是通过一次训练就能解决所有问题,但是不能因为部分问题还没有解决而无限期地进行迭代,我们的结果最终还是要落地到项目上,发挥实际的价值。
所以我们可能需要一个过滤和筛选,暂时屏蔽那些还没有解决的问题。这样当我们在后面的迭代工作中,只要解决了这个问题,再对这个修饰环节进行简单的调整,就可以重新上线了。
模型部署与结果保存
这样,我们的分类模型就可以进行部署应用,来实现算法的输出了。当然,在输出的过程中,我们还需要有一些机制来收集输出的结果以及badcase,我们把这些东西积累到基础数据中,在经过一段时间之后,就可以有更多的数据来支撑我们的模型迭代了。
- 总结
至此呢,我们最后一节实践课就讲完了。这一课时,我们以一个多层级的新闻文本分类为背景,先简单介绍了fastText模型;然后介绍了一种使用fastText来进行分类的简单案例;最后,我们引入了在实际的大型项目中,到底是如何进行多级分类的流程。
可以看到,在这个过程中,算法只是其中的一个环节,要想具体地解决业务中的实际问题,我们还需要做很多很多的工作。
那么我们的课程到这里也就结束了,非常感谢你能够坚持看完这门课程。在写作的过程中,由于各种各样的因素,内容难免存在一些错误和疏漏,如果你发现了问题,欢迎及时批评与指正。



