
Mysql学习

Mysql基础
1.MySQL概述
在这一章节,我们主要介绍两个部分,数据库相关概念及MysQL数据库的介绍、下载、安装、启动及连接。
1.1 数据库相关概念
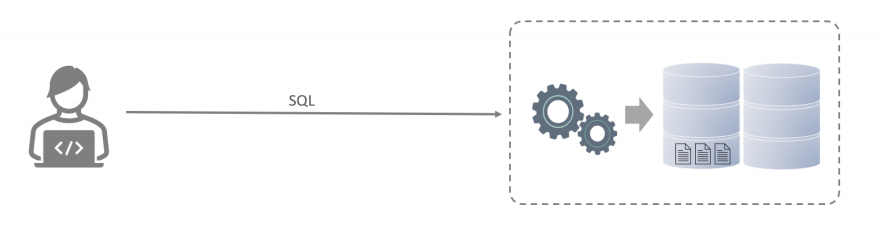
在这一部分,我们先来讲解三个概念:数据库、数据库管理系统、SQL。
| 名称 | 全称 | 简称 |
|---|---|---|
| 数据库 | 存储数据的仓库,数据是有组织的进行存储 | DataBase (DB) |
| 数据库管理系统 | 操纵和管理数据库的大型软件 | DataBase ManagementSystem (DBMS) |
| SQL | 操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准 | Structured QueryLanguage (SQL) |
而目前主流的关系型数据库管理系统的市场占有率排名如下:
- Oracle:大型的收费数据库,Oracle公司产品,价格昂贵。
- MySQL:开源免费的中小型数据库,后来Sun公司收购了MySQL,而Oracle又收购了sun公司。目前oracle推出了收费版本的MysQL,也提供了免费的社区版本。
- SQL Server:Microsoft 公司推出的收费的中型数据库,C#、.net等语言常用。
- PostgreSQL:开源免费的中小型数据库。
- DB2:IBM公司的大型收费数据库产品。
- SQLLite:嵌入式的微型数据库。Android内置的数据库采用的就是该数据库。
- MariaDB:开源免费的中小型数据库。是MySQL数据库的另外一个分支、另外一个衍生产品,与MySQL数据库有很好的兼容性。
而不论我们使用的是上面的哪一个关系型数据库,最终在操作时,都是使用SQL语言来进行统一操作,因为我们前面讲到SQL语言,是操作关系型数据库的统一标准。所以即使我们现在学习的是MySQL,假如我们以后到了公司,使用的是别的关系型数据库,如:Oracle、DB2、SQLServer,也完全不用担心,因为操作的方式都是一致的。
1.2 MySQL数据库
1.2.1 版本

MySQL官方提供了两种不同的版本:
- 社区版本(MySQL Community Server)免费, MySQL不提供任何技术支持
商业版本(MySQL Enterprise Edition)
收费,可以使用30天,官方提供技术支持
本课程采用的是MySQL最新的社区版-MySQL Community Server 8.0.26
1.2.2 下载
| MySQL Product Archives | ||
|---|---|---|
| 《MySQL Installer (Archived Versions)Product Version: 8.0.20 | ||
| Operating System:Mcrosoft Windows | ||
| Windews (xB6,32-bit), MSI Installercommuny-8.0.26.0 | 1ul6,2021 | 24M Dounlod742715afb35ad7 |
| imyoq-instalerwb-mWindows (x86,32-bit), MSI Installer | 16,2021 | MO5: eaddc383a83aa8hifh |
| Imysq-nstaler-communty-8.0.26.0.ms MO5:15b8eb39218817264 aais | SignanureWe sugpest that you use the MDS checksums and GnuPG signatures to verily the integrity of the packages you download | Imysq-nstaler-communty-8.0.26.0.ms MO5:15b8eb39218817264 aais |
| .MySQL open source software is provided under the GPL Lkcense. | .MySQL open source software is provided under the GPL Lkcense. |
也可以使用课程资料中提供的MySQL的安装包:

mysql-installer-community-8.0.26.0.msi Windows Installer程序包 461,472 KB
1.2.3 安装
要想使用MysQL,我们首先先得将MysQL安装好,我们可以根据下面的步骤,一步一步的完成MysQL的安装。
1).双击官方下来的安装包文件

mysql-installer-community-8.0.26.0.msi
2).根据安装提示进行安装
| MySQL Installer | - | |
|---|---|---|
| MySQL.InstallerAdding Community | Choosing a Setup TypePlease select the Setup Type that suits yo | ur use case. |
| Choosing a Setup TypeDownloadInstallationInstallation Complete | Developer DefaultInstalls all products needed forMySQL development purposes.Server onlyInstalls only the MySQL Serverproduct.Client onlyInstalls only the MySQL Clientproducts,without a server. | Setup Type DescriptionInstalls the MySQL Server and the toolsrequired for MySQL application development.This is useful if you intend to developapplications for an existing server.This Setup Type includes:MySQL ServerMySQL ShellThe new MySQL client application to manageMySQL Servers and InnoDB cluster instances. |
| FullInstalls all included MySQLproducts and features.CustomManually select the products thatshould be installed on thesystem. | *MySQL RouterHigh availability router daemon for InnoDBcluster setups to be installed on applicationNext> Canc |


安装MySQL的相关组件,这个过程可能需要耗时几分钟,耐心等待。



| MySQL In | staller - |
|---|---|
| MySQMySQL | L.Installer Type and NetworkingServer 8.0.26Server Configuration TypeChoose the correct server configuration type for this MySQL Server installation.This setting wildefine how much system resources are assigned to the MySQL Server instance. |
| Type and | Networking Config Type: Development Computer v |
| AuthenticAccounts Windows Apply Con | ation Method Connectivityand RolesUse the following controls to select how you would like to connect to this server.☑ TCP/IP Port: 3306 X Protocol Port: 33060Service☑Open Windows Firewall ports for network accessfiguration Named Pipe Pipe Name:MYSQL |
| Shared Memory Memory Name: MYSQLAdvanced ConfigurationSelect the check box below to get additional configuration pages where you can set advancedand logging options for this server instance.Show Advanced and Logging Options | |
| Net> Cancel |
输入MySQL中root用户的密码,一定记得记住该密码

| MySQL Installer | xWindows ServiceConfigure MySQL Server as a Windows ServiceWindows Service DetailsPlease specify a Windows Service name to be used for this My/SQL Server instance.A unique name is required for each instance.Windows Service Name: MySQL80Start the MySQL Server at System StartupRun Windows Service as…The MySQL Server needs to run under a given user account. Based on the securityrequirements of your system you nee to pick one of the options below.Standard System AccountRecommended for most scenarios.Custom UserAn existing user account can be selected for advanced scenarios. |
|---|---|
| MySQL.InstallerMySQL Server 8.0.26Type and NetworkingAuthentication MethodAccounts and RolesWindows ServiceApply Configuration | xWindows ServiceConfigure MySQL Server as a Windows ServiceWindows Service DetailsPlease specify a Windows Service name to be used for this My/SQL Server instance.A unique name is required for each instance.Windows Service Name: MySQL80Start the MySQL Server at System StartupRun Windows Service as…The MySQL Server needs to run under a given user account. Based on the securityrequirements of your system you nee to pick one of the options below.Standard System AccountRecommended for most scenarios.Custom UserAn existing user account can be selected for advanced scenarios. |
| MySQL.InstallerMySQL Server 8.0.26Type and NetworkingAuthentication MethodAccounts and RolesWindows ServiceApply Configuration | <Back Next> Cancel |

安装好MySQL之后,还需要配置环境变量,这样才可以在任何目录下连接MysQL。
A.在此电脑上,右键选择属性
| 打开(O) |
|---|
| 固定到“快速访问”管理(G)固定到“开始”屏幕(P) |
| 映射网络驱动器(N)… |
| 断开网络驱动器的连接(C)… |
| 创建快捷方式(S)删除(D |
| )重命名(M) |
| 属性(R) |
B.点击左侧的“高级系统设置”,选择环境变量
| 控制板系和安全\ x系纳属性 x | 控制板系和安全\ x系纳属性 x | 控制板系和安全\ x系纳属性 x | 控制板系和安全\ x系纳属性 x | 控制板系和安全\ x系纳属性 x | 控制板系和安全\ x系纳属性 x | 控制板系和安全\ x系纳属性 x | 控制板系和安全\ x系纳属性 x |
|---|---|---|---|---|---|---|---|
| 文件(F)编辑() | 控面板>系病和安全>系查看(V)工具(T) | 计机名 硬件 高级 系统保护 选程 | 计机名 硬件 高级 系统保护 选程 | 搜索控制板 | |||
| 控制铁页 查看有关计算机的基本信设备理息 Windoms 车远程设置 Windows 10 专业版系统保护 2018 Microsoft Corporati高级系统设置系统处理: 1已交装的 FRAM) 국系统类型: 64笔和控: 계计算机、城和作组设置计机名: M计机全名: M计机描述:工作明: WWindows 另清间 Windows 已 阅读 Micre安全维护 产品ID:00330-51889-12485 | 控制铁页 查看有关计算机的基本信设备理息 Windoms 车远程设置 Windows 10 专业版系统保护 2018 Microsoft Corporati高级系统设置系统处理: 1已交装的 FRAM) 국系统类型: 64笔和控: 계计算机、城和作组设置计机名: M计机全名: M计机描述:工作明: WWindows 另清间 Windows 已 阅读 Micre安全维护 产品ID:00330-51889-12485 | 进行大多数改,你必作为管员显录。性籍 | 进行大多数改,你必作为管员显录。性籍 | 进行大多数改,你必作为管员显录。性籍 | 进行大多数改,你必作为管员显录。性籍 | ||
| 控制铁页 查看有关计算机的基本信设备理息 Windoms 车远程设置 Windows 10 专业版系统保护 2018 Microsoft Corporati高级系统设置系统处理: 1已交装的 FRAM) 국系统类型: 64笔和控: 계计算机、城和作组设置计机名: M计机全名: M计机描述:工作明: WWindows 另清间 Windows 已 阅读 Micre安全维护 产品ID:00330-51889-12485 | 控制铁页 查看有关计算机的基本信设备理息 Windoms 车远程设置 Windows 10 专业版系统保护 2018 Microsoft Corporati高级系统设置系统处理: 1已交装的 FRAM) 국系统类型: 64笔和控: 계计算机、城和作组设置计机名: M计机全名: M计机描述:工作明: WWindows 另清间 Windows 已 阅读 Micre安全维护 产品ID:00330-51889-12485 | 规定效,处理计划,内存使用,以及虚拟存说置(S)- | 规定效,处理计划,内存使用,以及虚拟存说置(S)- | /indows 10 | |||
| 控制铁页 查看有关计算机的基本信设备理息 Windoms 车远程设置 Windows 10 专业版系统保护 2018 Microsoft Corporati高级系统设置系统处理: 1已交装的 FRAM) 국系统类型: 64笔和控: 계计算机、城和作组设置计机名: M计机全名: M计机描述:工作明: WWindows 另清间 Windows 已 阅读 Micre安全维护 产品ID:00330-51889-12485 | 控制铁页 查看有关计算机的基本信设备理息 Windoms 车远程设置 Windows 10 专业版系统保护 2018 Microsoft Corporati高级系统设置系统处理: 1已交装的 FRAM) 국系统类型: 64笔和控: 계计算机、城和作组设置计机名: M计机全名: M计机描述:工作明: WWindows 另清间 Windows 已 阅读 Micre安全维护 产品ID:00330-51889-12485 | 用户配置文件与登录户相关乘面设置设置(E)-动和助障复系统期:系统算和测试信息更改设置设置(T)环境交量(N)-确定 取消 应用(A) 更改品密明 | 用户配置文件与登录户相关乘面设置设置(E)-动和助障复系统期:系统算和测试信息更改设置设置(T)环境交量(N)-确定 取消 应用(A) 更改品密明 | 用户配置文件与登录户相关乘面设置设置(E)-动和助障复系统期:系统算和测试信息更改设置设置(T)环境交量(N)-确定 取消 应用(A) 更改品密明 | 用户配置文件与登录户相关乘面设置设置(E)-动和助障复系统期:系统算和测试信息更改设置设置(T)环境交量(N)-确定 取消 应用(A) 更改品密明 | 用户配置文件与登录户相关乘面设置设置(E)-动和助障复系统期:系统算和测试信息更改设置设置(T)环境交量(N)-确定 取消 应用(A) 更改品密明 | 用户配置文件与登录户相关乘面设置设置(E)-动和助障复系统期:系统算和测试信息更改设置设置(T)环境交量(N)-确定 取消 应用(A) 更改品密明 |
C.找到 Path 系统变量,点击“编辑”
| 环境变量My的用户变量(U) | 环境变量My的用户变量(U) | 环境变量My的用户变量(U) | 环境变量My的用户变量(U) | 环境变量My的用户变量(U) | 环境变量My的用户变量(U) | 环境变量My的用户变量(U) |
|---|---|---|---|---|---|---|
| 变量 值DataGrip D:\develop\DataGrip\bin;IntelliJ IDEA D:\develop\IntelliJ IDEA 2020.1.1\bin;OneDrive C:\Users\Administrator\OneDrivePath C:\Program Files\MySQL\MySQL Shell 8.0\bin\C:\Users\My\Ap…TEMP C:\Users\My\AppData\Local\TempTMP C:\Users\My\AppData\Local\Temp | 变量 值DataGrip D:\develop\DataGrip\bin;IntelliJ IDEA D:\develop\IntelliJ IDEA 2020.1.1\bin;OneDrive C:\Users\Administrator\OneDrivePath C:\Program Files\MySQL\MySQL Shell 8.0\bin\C:\Users\My\Ap…TEMP C:\Users\My\AppData\Local\TempTMP C:\Users\My\AppData\Local\Temp | 变量 值DataGrip D:\develop\DataGrip\bin;IntelliJ IDEA D:\develop\IntelliJ IDEA 2020.1.1\bin;OneDrive C:\Users\Administrator\OneDrivePath C:\Program Files\MySQL\MySQL Shell 8.0\bin\C:\Users\My\Ap…TEMP C:\Users\My\AppData\Local\TempTMP C:\Users\My\AppData\Local\Temp | 变量 值DataGrip D:\develop\DataGrip\bin;IntelliJ IDEA D:\develop\IntelliJ IDEA 2020.1.1\bin;OneDrive C:\Users\Administrator\OneDrivePath C:\Program Files\MySQL\MySQL Shell 8.0\bin\C:\Users\My\Ap…TEMP C:\Users\My\AppData\Local\TempTMP C:\Users\My\AppData\Local\Temp | 变量 值DataGrip D:\develop\DataGrip\bin;IntelliJ IDEA D:\develop\IntelliJ IDEA 2020.1.1\bin;OneDrive C:\Users\Administrator\OneDrivePath C:\Program Files\MySQL\MySQL Shell 8.0\bin\C:\Users\My\Ap…TEMP C:\Users\My\AppData\Local\TempTMP C:\Users\My\AppData\Local\Temp | ||
| 新建(N)… 编辑(E)… 删除(D) | 新建(N)… 编辑(E)… 删除(D) | 新建(N)… 编辑(E)… 删除(D) | 新建(N)… 编辑(E)… 删除(D) | 新建(N)… 编辑(E)… 删除(D) | 新建(N)… 编辑(E)… 删除(D) | 新建(N)… 编辑(E)… 删除(D) |
| 系统变量(S) | 系统变量(S) | 系统变量(S) | 系统变量(S) | 系统变量(S) | 系统变量(S) | 系统变量(S) |
| 变量NUMBER_OF_PROCESSORSOS | 值8Windows_NT | 值8Windows_NT | 值8Windows_NT | |||
| Path | C:\Windows\system32;C:\Windows;C:Windows\System32\Wbe… | C:\Windows\system32;C:\Windows;C:Windows\System32\Wbe… | C:\Windows\system32;C:\Windows;C:Windows\System32\Wbe… | |||
| PATHEXT .COM;.EXE;.BAT;.CMD;:VBS;VBE;JS;JSE.WSF;.WSH;.MSCPROCESSOR_ARCHITECTURE AMD64PROCESSOR_IDENTIFIER Intel64 Family 6 Model 142 Stepping 10, CenuinelntelPROCESSOR_LEVEL 6erccon | PATHEXT .COM;.EXE;.BAT;.CMD;:VBS;VBE;JS;JSE.WSF;.WSH;.MSCPROCESSOR_ARCHITECTURE AMD64PROCESSOR_IDENTIFIER Intel64 Family 6 Model 142 Stepping 10, CenuinelntelPROCESSOR_LEVEL 6erccon | PATHEXT .COM;.EXE;.BAT;.CMD;:VBS;VBE;JS;JSE.WSF;.WSH;.MSCPROCESSOR_ARCHITECTURE AMD64PROCESSOR_IDENTIFIER Intel64 Family 6 Model 142 Stepping 10, CenuinelntelPROCESSOR_LEVEL 6erccon | PATHEXT .COM;.EXE;.BAT;.CMD;:VBS;VBE;JS;JSE.WSF;.WSH;.MSCPROCESSOR_ARCHITECTURE AMD64PROCESSOR_IDENTIFIER Intel64 Family 6 Model 142 Stepping 10, CenuinelntelPROCESSOR_LEVEL 6erccon | PATHEXT .COM;.EXE;.BAT;.CMD;:VBS;VBE;JS;JSE.WSF;.WSH;.MSCPROCESSOR_ARCHITECTURE AMD64PROCESSOR_IDENTIFIER Intel64 Family 6 Model 142 Stepping 10, CenuinelntelPROCESSOR_LEVEL 6erccon | ||
| 新建(W)… 编辑(1)... 删除(L) | 新建(W)… 编辑(1)... 删除(L) | 新建(W)… 编辑(1)... 删除(L) | 新建(W)… 编辑(1)... 删除(L) | 新建(W)… 编辑(1)... 删除(L) | 新建(W)… 编辑(1)... 删除(L) | |
| 确定 | 取消 | 取消 |
D.选择“新建”,将MySQL Server的安装目录下的bin目录添加到环境变量
| 编辑环境变量 | 编辑环境变量 | 编辑环境变量 | 编辑环境变量 | 编辑环境变量 |
|---|---|---|---|---|
| %SystemRoot%\system32 | %SystemRoot%\system32 | 新建(N) | ||
| %SystemRoot% | %SystemRoot% | 新建(N) | ||
| %SystemRoot% | %SystemRoot% | |||
| %SystemRoot%\System32\Wbem | %SystemRoot%\System32\Wbem | 编辑(E) | ||
| %SYSTEMROOT%\System32\WindowsPowerShell\v1.0\ | %SYSTEMROOT%\System32\WindowsPowerShell\v1.0\ | |||
| %SYSTEMROOT%\System32\OpenSSH\ | %SYSTEMROOT%\System32\OpenSSH\ | 浏览(B)… | ||
| %JAVA_HOME%\bin | %JAVA_HOME%\bin | |||
| %MAVEN_HOME%\bin | %MAVEN_HOME%\bin | 删除(D) | ||
| C:\Program Files (x86)\MySQL\MySQL Server 5.5\bin | C:\Program Files (x86)\MySQL\MySQL Server 5.5\bin | 删除(D) | ||
| D:\develop\Git\cmd | D:\develop\Git\cmd | 上移(U) | 上移(U) | |
| D:\develop\TortoiseGit\bin | D:\develop\TortoiseGit\bin | 上移(U) | 上移(U) | |
| %ERLANG_HOME%\bin | %ERLANG_HOME%\bin | 上移(U) | 上移(U) | |
| %RABBITMQ_HOME%\bin | %RABBITMQ_HOME%\bin | 下移(O) | ||
| D:\develop\OpenSSL-Win64\bin | D:\develop\OpenSSL-Win64\bin | 下移(O) | ||
| %MONGO_HOME%\bin | %MONGO_HOME%\bin | |||
| C:\Program Files\nodejs\ | C:\Program Files\nodejs\ | |||
| C:\Program Files\MySQL\MySQL Server 8.0\bin | 编辑文本(T)… | |||
| 确定 取消 | 确定 取消 | 确定 取消 | 确定 取消 | 确定 取消 |
1.2.4启动停止
MySQL安装完成之后,在系统启动时,会自动启动MySQL服务,我们无需手动启动了。
当然,也可以手动的通过指令启动停止,以管理员身份运行cmd,进入命令行执行如下指令:
1 net start mysq180
2 net stop mysq180

注意 : 上述的 mysql80 是我们在安装MySQL时,默认指定的mysql的系统服务名,不是固定的,如果未改动,默认就是mysql80。

1.2.5 客户端连接
1). 方式一:使用MySQL提供的客户端命令行工具

2).方式二:使用系统自带的命令行工具执行指令
| 1 | mysq | 1 [-h 127.0.0.1] [-P 3306] -u root -p |
|---|---|---|
| 2 | ||
| 3 | 参数: | |
| 4 | -h:MySQL服务所在的主机IP | |
| 5 | -P:MySQL服务端口号,默认3306 | |
| 6 | -u:MySQL数据库用户名 | |
| 7 | -p:MysQL数据库用户名对应的密码 |
[]内为可选参数,如果需要连接远程的MysQL,需要加上这两个参数来指定远程主机IP、端口,如果连接本地的MySQL,则无需指定这两个参数。
| C:\Windows\system32\cmd.exe-mysq | l-u root-p |
|---|---|
| Microsoft Windows [版本 10.0.177(c) 2018 Microsoft Corporation。 | 63.1217]保留所有权利。 |
| C:\Users\My>mysql -u root -pEnter password:******Welcome to the MySQL monitor. CYour MySQL connection id is 9 | ommands end with : or \g. |
| Server version: 8.0.26 MySQL Com | munity Server-GPL |
| Copyright (c) 2000, 2021, OracleOracle is a registered trademarkaffiliates. Other names may be towners.Type’help:’ or”\h’ for help. T | and/or its affiliates. of Oracle Corporation and/or itsrademarks of their respectiveype’\c’ to clear the current input statement. |
| mysq1> |
注意:使用这种方式进行连接时,需要安装完毕后配置PATH环境变量。
1.2.6 数据模型
1).关系型数据库(RDBMS)
概念:建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
而所谓二维表,指的是由行和列组成的表,如下图(就类似于Exce1表格数据,有表头、有列、有行,还可以通过一列关联另外一个表格中的某一列数据)。我们之前提到的MySQL、Oracle、DB2、
SQLServer这些都是属于关系型数据库,里面都是基于二维表存储数据的。简单说,基于二维表存储数据的数据库就成为关系型数据库,不是基于二维表存储数据的数据库,就是非关系型数据库。

特点:
A. 使用表存储数据,格式统一,便于维护。
B. 使用SQL语言操作,标准统一,使用方便。
2). 数据模型
MySQL是关系型数据库,是基于二维表进行数据存储的,具体的结构图下:

我们可以通过MySQL客户端连接数据库管理系统DBMS,然后通过DBMS操作数据库
可以使用SQL语句,通过数据库管理系统操作数据库,以及操作数据库中的表结构及数据。
一个数据库服务器中可以创建多个数据库,一个数据库中也可以包含多张表,而一张表中又可以包含多行记录。
2. SQL
全称 Structured Query Language,结构化查询语言。操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准 。
2.1 SQL通用语法
在学习具体的SQL语句之前,先来了解一下SQL语言的同于语法。
1). SQL语句可以单行或多行书写,以分号结尾。
2). SQL语句可以使用空格/缩进来增强语句的可读性。
3). MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
4). 注释:
单行注释:– 注释内容 或 # 注释内容
多行注释:/* 注释内容 */
2.2 SQL分类
SQL语句,根据其功能,主要分为四类:DDL、DML、DQL、DCL。
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data DefinitionLanguage | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data ManipulationLanguage | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
2.3 DDL
Data Definition Language,数据定义语言,用来定义数据库对象(数据库,表,字段) 。
2.3.1 数据库操作
1). 查询所有数据库


2). 查询当前数据库
| 1select database() |
|---|
3). 创建数据库
1create database [ if not exists ] 数据库名 [ default charset 字符集 ] [ collate 排序规则 ] ;
案例:
A. 创建一个itcast数据库, 使用数据库默认的字符集。

在同一个数据库服务器中,不能创建两个名称相同的数据库,否则将会报错。
可以通过if not exists 参数来解决这个问题,数据库不存在, 则创建该数据库,如果存在,则不创建。

| Database |
|---|
B.创建一个itheima数据库,并且指定字符集

4).删除数据库
1 drop database [if exists] 数据库名;
如果删除一个不存在的数据库,将会报错。此时,可以加上参数 if exists,如果数据库存在,再执行删除,否则不执行删除。
mysql>
mysql> drop database test:
ERROR 1008 (HY000): Can’t drop database ‘test’; database doesn’t exist mysql>
aysq1>
mysql> drop database if exists test:
Query OK,O rows affected, 1 warning (0.00 sec)
5).切换数据库

我们要操作某一个数据库下的表时,就需要通过该指令,切换到对应的数据库下,否则是不能操作的。比如,切换到itcast数据,执行如下sQL:
2.3.2 表操作
2.3.2.1 表操作-查询创建
1).查询当前数据库所有表

| 1 show tables; |
|---|
比如,我们可以切换到sys这个系统数据库,并查看系统数据库中的所有表结构。
1 use sys;

| Tables_in_sys |
|---|
| host_summary |
| host_summary_by_file_io |
| host_summary_by_file_io_type |
| host_summary_by_stagck |
| host_sunmary_by_statement_latency |
| host_summary_by_statement_type |
| innodb_buffer_stats_by_schema |
| innodb_buffer_stats_by_table |
| innodb_lock_waits |
| io_by_thread_by_latency |
| io_global_by_file_by_bytes |
| io_global_by_file_by_latency |
| io_global_by_wait_by_bytes |
| io_global_by_wait_by_latency |
| latest_file_io |
| memory_by_host_by_current_bytesy_by_thread_by_current_b |
| memorytesmemory_by_user_by_current_bytes |
| memory_global_by_current_bytes |
| memory_global_total |
| metrics |
| processlist |
| ps_check_lost_instrumentation |
2).查看指定表结构
| 1 desc表名: |
|---|
通过这条指令,我们可以查看到指定表的字段,字段的类型、是否可以为NULL,是否存在默认值等信息。
mysql> desc tb_user;
| Field | Type | Nul1 | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int | YES | NULL | ||
| name | varchar(50) | YES | NULL | ||
| age | int | YES | NULL | ||
| gender | varchar(1) | YES | NULL |
4 rows in set (0.01 sec)
3).查询指定表的建表语句
通过这条指令,主要是用来查看建表语句的,而有部分参数我们在创建表的时候,并未指定也会查询到,因为这部分是数据库的默认值,如:存储引擎、字符集等。
| mysql> show create table tb_user; |
|---|
| Table |
row in set (0.00 sec)
4).创建表结构
| 1 CREATE TABLE 表名( | 1 CREATE TABLE 表名( |
|---|---|
| 2 | 字段1 字段1类型[COMMENT 字段1注释], |
| 3 | 字段2 字段2类型[COMMENT 字段2注释1, |
| 4 | 字段3 字段3类型[COMMENT 字段3注释], |
| 5 | * .* * .. |
| 6 | 字段n 字段n类型[COMMENT字段n注释] |
| 7 | )[COMMENT 表注释]: |
| 注意: $[ \cdots ]$内为可选参数,最后一个字段后面没有逗号 | 注意: $[ \cdots ]$内为可选参数,最后一个字段后面没有逗号 |
比如,我们创建一张表tb_user,对应的结构如下,那么建表语句为:
| id | name | age | gender |
|---|---|---|---|
| 1 | 令狐冲 | 28 | 男 |
| 2 | 风清扬 | 68 | 男 |
| 3 | 东方不败 | 32 | 男 |
| 1 | create table tb_user( |
|---|---|
| 2 | id int comment ‘编号’, |
| 3 | name varchar(50) comment ‘姓名’, |
| 4 | age int comment ‘年龄’, |
| 5 | gender varchar(1) comment ‘性别’ |
| 6 | ) comment ‘用户表’; |
2.3.2.2 表操作-数据类型
在上述的建表语句中,我们在指定字段的数据类型时,用到了int ,varchar,那么在MySQL中除了以上的数据类型,还有哪些常见的数据类型呢? 接下来,我们就来详细介绍一下MySQL的数据类型。MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
1). 数值类型
| 类型 | 大小 | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
| TINYINT | 1byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT/INTEGER | 4bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8bytes | (-2^63,2^63-1) | (0,2^64-1) | 极大整数值 |
| FLOAT | 4bytes | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 |
| DOUBLE | 8bytes | (-1.7976931348623157E+308,1.7976931348623157E+308) | 0 和(2.2250738585072014E-308,1.7976931348623157E+308) | 双精度浮点数值 |
| DECIMAL | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确定点数) |
| 1如: | 1如: |
|---|---|
| 2 | 1). 年龄字段 – 不会出现负数, 而且人的年龄不会太大 |
| 3 | age tinyint unsigned |
| 4 | |
| 5 | 2). 分数 – 总分100分, 最多出现一位小数 |
| 6 | score double(4,1) |
| 类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串(需要指定长度) |
| VARCHAR | 0-65535 bytes | 变长字符串(需要指定长度) |
| TINYBLOB | 0-255 bytes | 不超过255个字符的二进制数据 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
char 与 varchar 都可以描述字符串,char是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。而varchar是变长字符串,指定的长度为最大占用长度 。相对来说,char的性能会更高些。
| 1 | 如: |
|---|---|
| 2 | 1). 用户名 username ——> 长度不定, 最长不会超过50 username varchar(50) |
| 3 | 1). 用户名 username ——> 长度不定, 最长不会超过50 username varchar(50) |
| 4 | |
| 5 | 2). 性别 gender ———> 存储值, 不是男,就是女 |
| 6 | gender char(1) |
| 7 | |
| 8 | 3). 手机号 phone ——–> 固定长度为11 |
| 9 | phone char(11) |
3). 日期时间类型
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至9999-12-31 23:59:59 | YYYY-MM-DDHH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至2038-01-19 03:14:07 | YYYY-MM-DDHH:MM:SS | 混合日期和时间值,时间戳 |
| 1如: | 1如: |
|---|---|
| 2 | 1). 生日字段 birthday |
| 3 | birthday date |
| 4 | |
| 5 | 2). 创建时间 createtime |
| 6 | createtime datetime |
2.3.2.3 表操作-案例
设计一张员工信息表,要求如下:
编号(纯数字)
员工工号 (字符串类型,长度不超过10位)
员工姓名(字符串类型,长度不超过10位)
性别(男/女,存储一个汉字)
年龄(正常人年龄,不可能存储负数)
身份证号(二代身份证号均为18位,身份证中有X这样的字符)
入职时间(取值年月日即可)
对应的建表语句如下:
| 1 | create table emp( |
|---|---|
| 2 | id int comment ‘编号’, |
| 3 | workno varchar(10) comment ‘工号’, |
| 4 | name varchar(10) comment ‘姓名’, |
| 5 | gender char(1) comment ‘性别’, |
| 6 | age tinyint unsigned comment ‘年龄’, |
| 7 | idcard char(18) comment ‘身份证号’, |
| 8 | entrydate date comment ‘入职时间’ |
| 9 | ) comment ‘员工表’; |
SQL语句编写完毕之后,就可以在MySQL的命令行中执行SQL,然后也可以通过 desc 指令查询表结构信息:

表结构创建好了,里面的name字段是varchar类型,最大长度为10,也就意味着如果超过10将会报错,如果我们想修改这个字段的类型 或 修改字段的长度该如何操作呢?接下来再来讲解DDL语句中,如何操作表字段。
2.3.2.4 表操作-修改
1). 添加字段
1ALTER TABLE 表名 ADD 字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
案例:
为emp表增加一个新的字段”昵称”为nickname,类型为varchar(20)
1ALTER TABLE emp ADD nickname varchar(20) COMMENT ‘昵称’;
2). 修改数据类型
3). 修改字段名和字段类型
1ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
案例:
将emp表的nickname字段修改为username,类型为varchar(30)
1ALTER TABLE emp CHANGE nickname username varchar(30) COMMENT ‘昵称’;
4). 删除字段
| 1 | ALTER | TABLE | 表名 | DROP | 字段名; |
|---|
案例:
将emp表的字段username删除
| 1 | ALTER | TABLE | emp DR | OP us | ername; |
|---|
5). 修改表名
1ALTER TABLE 表名 RENAME TO 新表名;
案例:
将emp表的表名修改为 employee
1ALTER TABLE emp RENAME TO employee;
2.3.2.5 表操作-删除
1). 删除表
1DROP TABLE [ IF EXISTS ] 表名;
可选项 IF EXISTS 代表,只有表名存在时才会删除该表,表名不存在,则不执行删除操作(如果不加该参数项,删除一张不存在的表,执行将会报错)。
案例:
如果$: t b _ u s e r$表存在,则删除$t b _ { - } u s e _ { 1 }$r表
2). 删除指定表, 并重新创建表
| 1 | TRUNCATE | TABLE 表名 |
|---|
注意: 在删除表的时候,表中的全部数据也都会被删除。
2.4 图形化界面工具
上述,我们已经讲解了通过DDL语句,如何操作数据库、操作表、操作表中的字段,而通过DDL语句执行在命令进行操作,主要存在以下两点问题:
1).会影响开发效率 ;
2). 使用起来,并不直观,并不方便 ;
所以呢,我们在日常的开发中,会借助于MySQL的图形化界面,来简化开发,提高开发效率。而目前mysql主流的图形化界面工具,有以下几种:



而本次课程中,选择最后一种DataGrip,这种图形化界面工具,功能更加强大,界面提示更加友好,是我们使用MySQL的不二之选。接下来,我们来介绍一下DataGrip该如何安装、使用。
2.4.1 安装
1). 找到资料中准备好的安装包,双击开始安装

| DG | Welcome to DataGrip SetupSetup will guide you through the installation of DataGrip.It is recommended that you close all other applicationsbefore starting Setup. This will make it possible to updaterelevant system files without having to reboot yourcomputer.Click Next to continue. |
|---|---|
| Next> Cancel |
选择DataGrip的安装目录,然后选择下一步

| DG Choose Install LocationChoose the folder in which to install DataGrip.Setup will install DataGrip in the following folder.To install in a different folder, |
|---|
| Browse and select another folder.Click Next to continue. |
| Destination FolderC:\Program FilesUetBrains\DataGrip 2021.2.2 Brow |
| Space required: 987.2 MBSpace available:14.6 GBBack Next> |
| DataGrip SetupInstallation OptioDGConfigure your DataG | nsrip installation |
|---|---|
| Create sktop Shortcut UpdDataGripUpdate Context MenuAdd “Open Folder as Project”Create Associations | ate PATH Variable(restart needed)Add “bin” folder to the PATH |
| .sqlBack Next> Cancel | .sqlBack Next> Cancel |
下一步,执行安装
| DataGrip Setup -DG InstallingPlease wait while DataGrip is being installed.Extract: 3rd-party.jar…70%Show details |
|---|
| <Back Next> |

2.4.2 使用
1). 添加数据源
参考图示, 一步步操作即可


配置以及驱动jar包下载完毕之后,就可以点击 “Test Connection” 就可以测试,是否可以连接MySQL,如果出现 “Successed”,就表名连接成功了 。
| Data Sources and Drivers | Data Sources and Drivers |
|---|---|
| Data Sources Drivers | Name: @localhostComment:General Options SSH/SSL Schemas Advanced |
| 区Project Data Sources | Name: @localhostComment:General Options SSH/SSL Schemas Advanced |
| @localhost | |
| Problems | Connection type:default Driver: MySQLHost: localhost Port: |
| Problems | Authentication: User & PasswordUser: root |
| Problems | Password: hidden Save: |
| Problems | Database:URL: jdbc:mysql://localhost:3306Overrides settings above |
| SucceededDBMS:MyS (ver.8.0.2Case sensitivity plain=low | 6)er,delimited=lower |
| Driver:MySQL Connector08be9e9b4cba6aa115f9bPing:63 msSSL:yes | /J (ver.mysql-connector-java-8.0.25(Revision:27b215887af40b159e0),JDBC4.2) |
| ? | Test Conne VMySQL 8.0.26OK C |
2).展示所有数据库
连接上了MysQL服务之后,并未展示出所有的数据库,此时,我们需要设置,展示所有的数据库,具体操作如下:

3).创建数据库


注意:
以下两种方式都可以创建数据库:
A. create database db01;
B. create schema db01;
4).创建表
在指定的数据库上面右键,选择new –> Table
| Database)MySQL-@localhost test | Database)MySQL-@localhost test | Database)MySQL-@localhost test | Database)MySQL-@localhost test | Database)MySQL-@localhost test | Database)MySQL-@localhost test |
|---|---|---|---|---|---|
| GDatabaseSedeeOMySQL- | console | console | console | console | |
| GDatabaseSedeeOMySQL- | Txe Auto | ||||
| GDatabaseSedeeOMySQL- | @localhost 7 | 1 | 1 | ||
| inform | ation_schema | ||||
| > itcast | |||||
| > itheim> mysql | a | ||||
| > perfor | mance_schema | ||||
| New | |||||
| + | New | Query Co | nsole | Ctrl+Shift+ | Q |
| > | Rename… | Shift+F6 | |||
| Modify Object…Copy Ref | Ctrl+F6 ViewCtrl+Alt+Shift+C S | Ctrl+F6 ViewCtrl+Alt+Shift+C S | |||
| erenceGo to DDLRelated Symbol… | chemaCtrl+B User | ||||
| erenceGo to DDLRelated Symbol… | Ctrl+Alt+B role | Ctrl+Alt+B role | |||
| Quick Documentation | Ctrl+Q Data Sour | ce | > | ||
| Find Usages | Alt+F7 DDL Data | Source | |||
| Add to Favorites | > :Data Sou | rce from UR | L | ||
| SQL ScriptsDatabase Tools | > =Data Sou> Driver an | rcefrom Pad Data Sour | thce | ||
| Diagnostics | > Driver |

5).修改表结构
在需要修改的表上,右键选择"Modify Table…"
| Database》MySQL-@localhost7information_schema> itcast> itheima> mysql> performance_schema> systesttables | Database》MySQL-@localhost7information_schema> itcast> itheima> mysql> performance_schema> systesttables | consoleTx A1 |
|---|---|---|
| userServer Obj | + NewRename… | >$S h i f t + F 6$ |
| userServer Obj | Modify Table.. | $C t r \vert + F 6$ |
| userServer Obj | Copy Reference Ctrl+Alt+Shift+CEdit Data F4Go to DDL Ctrl+BRelated Symbol… $C t r \vert + A l t + B$ | Copy Reference Ctrl+Alt+Shift+CEdit Data F4Go to DDL Ctrl+BRelated Symbol… $C t r \vert + A l t + B$ |

如果想增加字段,直接点击+号,录入字段信息,然后点击Execute即可。
如果想删除字段,直接点击-号,就可以删除字段,然后点击Execute即可。
如果想修改字段,双击对应的字段,修改字段信息,然后点击Execute即可。
如果要修改表名,或表的注释,直接在输入框修改,然后点击Execute即可。
6).在DataGrip中执行sQL语句
在指定的数据库上,右键,选择New –> Query Console

| New | Query Console Ctrl+Shift+Q | Query Console Ctrl+Shift+Q | |
|---|---|---|---|
| Modily Object.. | Shift-F6I TableCtrl+F6View | age Data | Sources Ctrl+Alt+Shift+S |
| Copy Refere CtrGo to DOL | l+Alt+Shift+C SchemaCul+BUner | View Alt | +2 |
| Belated Symbol.. | Ctrl+At+B 二role | t Files Ct | rl+E |
| Quick DocumsntationFind UhagesAdd to Favorites | Ctrl+Q Data SourceAlt+F7 DDL Duta Sour | ce gation Bar | Alt+Home |
| Quick DocumsntationFind UhagesAdd to Favorites | > Data Source fr | om URL Table or | Routine Ctrl+N |
| SQL SeriptsDatabate Toolsi | Data Source frDriver and Dat | omPatha SourceFile Ctrl | +Shift+N |
然后就可以在打开的Query Console控制台,并在控制台中编写sQL,执行sQL。

2.5 DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
添加数据(INSERT)
修改数据(UPDATE)
删除数据(DELETE)
2.5.1 添加数据
1).给指定字段添加数据
1 INSERT INTO 表名(字段名1,字段名2,...) VALUES (值1,值2,...);
案例:给emp1oyee表所有的字段添加数据;
1 insert into employee (id,workno,name,gender, age,idcard,entrydate)values (1, '1', 'Itcast','男',10,'123456789012345678*,12000-01-011);
插入数据完成之后,我们有两种方式,查询数据库的数据:
A.方式一
在左侧的表名上双击,就可以查看这张表的数据。
| te ⑳표 | |
|---|---|
| / | |
| MySQL-@localhostinformation_schema | |
| itcast 1id: H workno | |
| tables 1 Itcastemployee | 男 |
| itheim | |
| amysql | |
| performance_schema> ss | |
| testServer Objects | testServer Objects |
B.方式二
可以直接一条查询数据的sQL语句,语句如下:
| 1 | select *from employee; |
|---|

案例:给emp1oyee表所有的字段添加数据
执行如下sQL,添加的年龄字段值为-1。
| values (1, '1', 'Itcast', '男',-1,'123456789012345678,12000-01-011); |
|---|
执行上述的sQL语句时,报错了,具体的错误信息如下:
[22001][1264]Data truncation:Out of range value for column ‘age’ at row 1
因为 employee 表的aq字段类型为 tinyint,而且还是无符号的 unsigned,所以取值只能在0-255之间。
| employee |
|---|
| columns 7 |
| id int |
| workno varchar |
| name varchar(1ender char(1) |
| gage tinyint unsig |
| idcard char(18) |
| entrydate date |
2).给全部字段添加数据
1 INSERT INTO 表名 VALUES (值1,值2,⋯);
案例:插入数据到employee表,具体的sQL如下:
1 insert into employee values(2,'2",'张无忌",'男',18,"123456789012345670','2005-01-011);
3).批量添加数据
1 INSERT INTO 表名(字段名1,字段名2,...) VALUES (值1,值2,⋯),(值1,值2,⋯⋅1,(值1,值2,...);
1 INSERT INTO 表名 VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...);
案例:批量插入数据到employee表,具体的sQL如下:
1insert into employee values(3,'3','韦一笑','男',38,'123456789012345670','2005-01-011),(4,14,'赵敏','女',18,'123456789012345670','2005-01-01');
注意事项:
- 插入数据时,指定的字段顺序需要与值的顺序是–对应的。
• 字符串和日期型数据应该包含在引号中。
• 插入的数据大小,应该在字段的规定范围内。
2.5.2 修改数据
修改数据的具体语法为:
1 UPDATE 表名 SET 字段名B1=值1 , 字段名2=值2,⋯[ WHERE 条件 ] ;
案例:
A. 修改id为1的数据,将name修改为itheima
1update employee set name = ‘itheima’ where 1d=1;
B. 修改id为1的数据, 将name修改为小昭, gender修改为 女
1update employee set name = ‘小昭’ , gender = ‘女’ where id=1:
C. 将所有的员工入职日期修改为 2008-01-01
1update employee set entrydate = ‘2008-01-01’;
注意事项:
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
2.5.3 删除数据
删除数据的具体语法为:
1DELETE FROM 表名 [ WHERE 条件 ] ;
案例:
A. 删除gender为女的员工
1delete from employee where gender = ‘女’;
B. 删除所有员工

注意事项:
• DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
• DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。
• 当进行删除全部数据操作时,datagrip会提示我们,询问是否确认删除,我们直接点击Execute即可。
2.6 DQL
DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录。
查询关键字: SELECT
在一个正常的业务系统中,查询操作的频次是要远高于增删改的,当我们去访问企业官网、电商网站,在这些网站中我们所看到的数据,实际都是需要从数据库中查询并展示的。而且在查询的过程中,可能还会涉及到条件、排序、分页等操作。

那么,本小节我们主要学习的就是如何进行数据的查询操作。 我们先来完成如下数据准备工作:
| 1 | drop table if exists employee; | |
|---|---|---|
| 2 | ||
| 3 | create table emp( | |
| 4 | id int comment ‘编号’, | |
| 5 | workno varchar(10) comment ‘工号 | ‘, |
| 6 | name varchar(10) comment ‘姓名’, | |
| 7 | gender char(1) comment ‘性别’, | |
| 8 | age tinyint unsigned comment ‘年 | 龄’, |
| 9 | idcard char(18) comment ‘身份证号 | ‘, |
| 10 | workaddress varchar(50) comment | ‘工作地址’, |
| 11 | entrydate date comment ‘入职时间’ | |
| 12 | )comment ‘员工表’; | |
| 13 | ||
| 14 | INSERT INTO emp (id, workno, name, gVALUES (1, ‘00001’, ‘柳岩666’, ‘女’, | ender, age, idcard, workaddress, entrydate20, ‘123456789012345678’, ‘北京’, ‘2000-01- |
| 15 | 01’);INSERT INTO emp (id, workno, name, gVALUES (2, ‘00002’, ‘张无忌’, ‘男’, 1 | ender, age, idcard, workaddress, entrydate8, ‘123456789012345670’, ‘北京’, ‘2005-09- |
| 01’); |
16INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (3, ‘00003’, ‘韦一笑’, ‘男’, 38, ‘123456789712345670’, ‘上海’, ‘2005-08-01’);
17INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate) VALUES (4, ‘00004’, ‘赵敏’, ‘女’, 18, ‘123456757123845670’, ‘北京’, ‘2009-12-01’);
18INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate) VALUES (5, ‘00005’, ‘小昭’, ‘女’, 16, ‘123456769012345678’, ‘上海’, ‘2007-07-01’);
19INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate) VALUES (6, ‘00006’, ‘杨逍’, ‘男’, 28, ‘12345678931234567X’, ‘北京’, ‘2006-01-01’);
20INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate) VALUES (7, ‘00007’, ‘范瑶’, ‘男’, 40, ‘123456789212345670’, ‘北京’, ‘2005-05-01’);
21INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (8, ‘00008’, ‘黛绮丝’, ‘女’, 38, ‘123456157123645670’, ‘天津’, ‘2015-05-01’);
22INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (9, ‘00009’, ‘范凉凉’, ‘女’, 45, ‘123156789012345678’, ‘北京’, ‘2010-04-01’);
23INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (10, ‘00010’, ‘陈友谅’, ‘男’, 53, ‘123456789012345670’, ‘上海’, ‘2011-01-01’);
24INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (11, ‘00011’, ‘张士诚’, ‘男’, 55, ‘123567897123465670’, ‘江苏’, ‘2015-05-01’);
25INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (12, ‘00012’, ‘常遇春’, ‘男’, 32, ‘123446757152345670’, ‘北京’, ‘2004-02-01’);
26INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (13, ‘00013’, ‘张三丰’, ‘男’, 88, ‘123656789012345678’, ‘江苏’, ‘2020-11-01’);
27INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (14, ‘00014’, ‘灭绝’, ‘女’, 65, ‘123456719012345670’, ‘西安’, ‘2019-05-01’);
28INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (15, ‘00015’, ‘胡青牛’, ‘男’, 70, ‘12345674971234567X’, ‘西安’, ‘2018-04-01’);
29INSERT INTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES (16, ‘00016’, ‘周芷若’, ‘女’, 18, null, ‘北京’, ‘2012-06-01’);
准备完毕后,我们就可以看到emp表中准备的16条数据。接下来,我们再来完成DQL语法的学习。
2.6.1 基本语法
DQL 查询语句,语法结构如下:
| 1 | SELECT |
|---|---|
| 2 | 字段列表 |
| 3 | FROM |
| 4 | 表名列表 |
| 5 | WHERE |
| 6 | 条件列表 |
| 7 | GROUP BY |
| 8 | 分组字段列表 |
| 9 | HAVING |
| 10 | 分组后条件列表 |
| 11 | ORDER BY |
| 12 | 排序字段列表 |
| 13 | LIMIT |
| 14 | 分页参数 |
我们在讲解这部分内容的时候,会将上面的完整语法进行拆分,分为以下几个部分:
基本查询(不带任何条件)
条件查询(WHERE)
聚合函数(count、max、min、avg、sum)
分组查询(group by)
排序查询(order by)
分页查询(limit)
2.6.2 基础查询
在基本查询的DQL语句中,不带任何的查询条件,查询的语法如下:
1). 查询多个字段
1SELECT 字段1, 字段2, 字段3 … FROM 表名 ;
1 SELECT FROM 表名 ;
注意 : * 号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)。
2). 字段设置别名
| 1 | SELECT | 字段1 | [ AS 别 | 名1 ] , 字 | 段2 [ AS | 别名2 ] | … FR | OM 表名; |
|---|---|---|---|---|---|---|---|---|
| 1 | SELECT | 字段1 | [ 别名1 | ] , 字段2 | [ 别名2 ] | … F | ROM 表名 | ; |
3). 去除重复记录
1SELECT DISTINCT 字段列表 FROM 表名;
案例:
A. 查询指定字段 name, workno, age并返回
| 1 | select name,workno,age from emp; |
|---|
B. 查询返回所有字段
| 1 | select id ,workno,name,gender,age,idcard,workaddress,entrydate from emp; |
|---|---|
| 1select * from emp; | 1select * from emp; |
C. 查询所有员工的工作地址,起别名
1select workaddress as ‘工作地址’ from emp;
| 1– as可以省略 | 1– as可以省略 |
|---|---|
| 2select workaddress ‘工作地址’ from emp; |
D. 查询公司员工的上班地址有哪些(不要重复)
1select distinct workaddress ‘工作地址’ from emp;
2.6.3 条件查询
1). 语法
2). 条件
常用的比较运算符如下:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN … AND … | 在某个范围之内(含最小、最大值) |
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| IS NULL | 是NULL |
常用的逻辑运算符如下:
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且 (多个条件同时成立) |
| OR 或 | |
| NOT 或 ! | 非 , 不是 |
案例:
A. 查询年龄等于 88 的员工
| 1 | select * from emp where |
|---|
B. 查询年龄小于 20 的员工信息
1select * from emp whereaqe<20;
C. 查询年龄小于等于 20 的员工信息
| 1 | select * | from emp | where a | ge <= 20 |
|---|
D. 查询没有身份证号的员工信息
| 1 | select * from emp where idcard is null; |
|---|
E. 查询有身份证号的员工信息
| 1 | select * from emp whe | re idcard is not null; |
|---|
F. 查询年龄不等于 88 的员工信息
1select * from emp where age!=88;
2select * from emp whereaqe↔8B;
G. 查询年龄在15岁(包含) 到 20岁(包含)之间的员工信息
1select * from emp where age>=1566a9e<=20;
2select * from emp where aqe>=15andaqe<=20;
3select * from emp where age between 15 and 20;
H. 查询性别为 女 且年龄小于 25岁的员工信息
1select * from emp where gender = ‘女’ and aqe<25;
I. 查询年龄等于18 或 20 或 40 的员工信息
1select * from emp where age=18orage=20oxage=40;
2select * from emp where age in(18,20,40);
J. 查询姓名为两个字的员工信息 _ %
1select * from emp where name like ‘__’;
K. 查询身份证号最后一位是X的员工信息
1select * from emp where idcard like ‘%X’;
2select * from emp where idcard like ‘_________________X’;
2.6.4 聚合函数
1). 介绍
将一列数据作为一个整体,进行纵向计算 。
2). 常见的聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
3). 语法
| 1 | SELECT | 聚合函数(字段列表) | FROM | 表名 ; |
|---|
注意 : NULL值是不参与所有聚合函数运算的。
案例:
A. 统计该企业员工数量
1select count(*) from emp; – 统计的是总记录数
2select count(idcard) from emp; – 统计的是idcard字段不为null的记录数
对于count聚合函数,统计符合条件的总记录数,还可以通过 count(数字/字符串)的形式进行统计查询,比如:
1select count(1) from emp;
对于count(*) 、count(字段)、 count(1) 的具体原理,我们在进阶篇中SQL优化部分会详细讲解,此处大家只需要知道如何使用即可。
B. 统计该企业员工的平均年龄
C. 统计该企业员工的最大年龄
| 1 | select max(age) from emp; |
|---|
D. 统计该企业员工的最小年龄
| 1select min(age) from emp |
|---|

E. 统计西安地区员工的年龄之和
1select sum(age) from emp where workaddress = ‘西安’;
2.6.5 分组查询
1). 语法
| 1 | SELECT | 字段列表 | FROM | 表名 | [ WHERE | 条件 ] | GROUP | BY | 分组字段名 | [ HAVING | 分组 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 后过滤条件 ]; | 后过滤条件 ]; | 后过滤条件 ]; | 后过滤条件 ]; | 后过滤条件 ]; | 后过滤条件 ]; |
2). where与having区别
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
注意事项:
• 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
• 执行顺序: where>聚合函数 > having
• 支持多字段分组, 具体语法为 : group by columnA,columnB
案例:
A. 根据性别分组 , 统计男性员工 和 女性员工的数量
1select gender, count(*) from emp group by gender ;
B. 根据性别分组 , 统计男性员工 和 女性员工的平均年龄
1select gender, avg(age) from emp group by gender ;
C. 查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
1select workaddress, count(*) address_count from emp where age < 45 group by workaddress having address_count >= 3;
D. 统计各个工作地址上班的男性及女性员工的数量
| select workaddress, gender, count(*) ‘数量’ from emp group by gender , workaddress; |
|---|
2.6.6 排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
 |
|||||
|---|---|---|---|---|---|
1). 语法
1SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;
2). 排序方式
ASC : 升序(默认值)
DESC: 降序
注意事项:
• 如果是升序, 可以不指定排序方式ASC ;
• 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序 ;
案例:
A. 根据年龄对公司的员工进行升序排序
| 1 | select * from emp order by age asc; |
|---|---|
| 2 | select * from emp order by age; |
B. 根据入职时间, 对员工进行降序排序
1select * from emp order by entrydate desc;
C. 根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序
1select * from emp order by age asc , entrydate desc;
2.6.7 分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,我们在网站中看到的各种各样的分页条,后台都需要借助于数据库的分页操作。
1). 语法
1SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数 ;
注意事项:
• 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
• 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
• 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
案例:
A. 查询第1页员工数据, 每页展示10条记录
1select * from emp limit 0,10;
2select * from emp limit 10;
B. 查询第2页员工数据, 每页展示10条记录 ——–> (页码-1)*页展示记录数
1select * from emp limit 10,10;
2.6.8 案例
1). 查询年龄为20,21,22,23岁的员工信息。
1select * from emp where gender = ‘女’ and age in(20,21,22,23);
2).查询性别为男,并且年龄在20-40岁(含)以内的姓名为三个字的员工。
1 select *from emp where gender - '男'and ( age between 20 and 40 ) and name like 1-1
3).统计员工表中,年龄小于60岁的,男性员工和女性员工的人数。
1 select gender, count(*) from emp whereaqe<60group by gender;
4).查询所有年龄小于等于35岁员工的姓名和年龄,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序。
1 select name, age from emp where age <= 35 order by age asc, entrydate desc;
5).查询性别为男,且年龄在20-40岁(含)以内的前5个员工信息,对查询的结果按年龄升序排序,年龄相同按入职时间升序排序。
1 select * from emp where gender - '男' and age between 20 and 40 order by age asc,entrydate asc limit 5;
2.6.9 执行顺序
在讲解DQL语句的具体语法之前,我们已经讲解了DQL语句的完整语法,及编写顺序,接下来,我们要来说明的是DQL语句在执行时的执行顺序,也就是先执行那一部分,后执行那一部分。

| FROM |
|---|
| 表名列表 |
| WHERE |
| 条件列表 |
| GROUP BY |
| 分组字段列表 |
| HAVING |
| 分组后条件列表 |
| SELECT |
| 字段列表 |
| ORDER BY |
| 排序字段列表 |
| LIMIT |
| 分页参数 |

编写顺序 执行顺序
验证:
查询年龄大于15的员工姓名、年龄,并根据年龄进行升序排序。
1select name , age from emp where age > 15 order by age asc;
在查询时,我们给emp表起一个别名 e,然后在select 及 where中使用该别名。
1select e.name , e.age from emp e where e.age > 15 order by age asc;
执行上述SQL语句后,我们看到依然可以正常的查询到结果,此时就说明: from 先执行, 然后where 和 select 执行。那 where 和 select 到底哪个先执行呢?
此时,此时我们可以给select后面的字段起别名,然后在 where 中使用这个别名,然后看看是否可以执行成功。
1select e.name ename , e.age eage from emp e where eage > 15 order by age asc;
执行上述SQL报错了:

由此我们可以得出结论: from 先执行,然后执行 where , 再执行select 。
接下来,我们再执行如下SQL语句,查看执行效果:
1select e.name ename , e.age eage from emp e where e.age > 15 order by eage asc;
结果执行成功。 那么也就验证了: order by 是在select 语句之后执行的。
综上所述,我们可以看到DQL语句的执行顺序为: from … where … group by …having … select … orderby⋯limit …
2.7 DCL
DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。

2.7.1 管理用户
1).查询用户
| 1 | select * from mysql.user; |
|---|
查询的结果如下:
| I Host : | J7 User | Select_priv | 7 Insert_priv | 27 Update_priv | Delete_priv : | Jll Create_priv | J7 Drop_priv |
|---|---|---|---|---|---|---|---|
| Localhost | mysql.infoschena | Y | N | N | N | N | N |
| Localhost | mysql.session | N | N | N | N | ||
| localhost | mysql,sys | N | N | N | N | N | |
| Localhost | root | Y | Y | Y | Y | Y |
其中 Host代表当前用户访问的主机,如果为1ocalhost,仅代表只能够在当前本机访问,是不可以远程访问的。 User代表的是访问该数据库的用户名。在MySQL中需要通过Host和User来唯一标识一个用户。
2).创建用户
| 1 | CREATE | USER | '用户名*@'主机名' |
|---|
3).修改用户密码
1 ALTER USER'用户名'@'主机名'IDENTIFIED WITH mysql_native_password BY'新密码;
4).删除用户
| 1 | DROP USE | R'用户名" | @*主机名”; |
|---|
注意事项:
- 在MySQL中需要通过用户名@主机名的方式,来唯一标识一个用户。
• 主机名可以使用 % 通配。
• 这类SQL开发人员操作的比较少,主要是DBA( Database Administrator 数据库管理员)使用。
案例:
A. 创建用户itcast, 只能够在当前主机localhost访问, 密码123456;
1create user ‘itcast‘@’localhost’ identified by ‘123456’;
B. 创建用户heima, 可以在任意主机访问该数据库, 密码123456;
1create user ‘heima‘@’%’ identified by ‘123456’;
C. 修改用户heima的访问密码为1234;
1alter user ‘heima‘@’%’ identified with mysql_native_password by ‘1234’;
D. 删除 itcast@localhost 用户
1drop user ‘itcast‘@’localhost’;
2.7.2 权限控制
MySQL中定义了很多种权限,但是常用的就以下几种:
| 权限 | 说明 |
|---|---|
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
上述只是简单罗列了常见的几种权限描述,其他权限描述及含义,可以直接参考官方文档。
1).查询权限
| 1 |
|---|
2).授予权限
1 GRANT 权限列表ON 数据库名,表名TO'用户名'@'主机名;
3).撤销权限
1 REVOKE 权限列表 ON 数据库名.表名 FROM'用户名"@'主机名';
注意事项:
多个权限之间,使用逗号分隔
授权时,数据库名和表名可以使用*进行通配,代表所有。
案例:
A.查询'heima'@'%'用户的权限
1 show grants for ‘heima‘@’%’;
B.授予'heima'@"%'用户itcast数据库所有表的所有操作权限
1 grant all on itcast.* to ‘heima‘@’%’;
C.撤销'heima'@%”用户的itcast数据库的所有权限
1 revoke all on itcast.* from ‘heima‘@’%
3.函数
函数 是指一段可以直接被另一段程序调用的程序或代码。 也就意味着,这一段程序或代码在MySQL中已经给我们提供了,我们要做的就是在合适的业务场景调用对应的函数完成对应的业务需求即可。 那么,函数到底在哪儿使用呢?
我们先来看两个场景:


1). 在企业的OA或其他的人力系统中,经常会提供的有这样一个功能,每一个员工登录上来之后都能够看到当前员工入职的天数。 而在数据库中,存储的都是入职日期,如 2000-11-12,那如果快速计算出天数呢?
2). 在做报表这类的业务需求中,我们要展示出学员的分数等级分布。而在数据库中,存储的是学生的分数值,如98/75,如何快速判定分数的等级呢?
其实,上述的这一类的需求呢,我们通过MySQL中的函数都可以很方便的实现 。
MySQL中的函数主要分为以下四类: 字符串函数、数值函数、日期函数、流程函数。
3.1 字符串函数
MySQL中内置了很多字符串函数,常用的几个如下:
| 函数 | 功能 |
|---|---|
| CONCAT(S1,S2,…Sn) | 字符串拼接,将S1,S2,… Sn拼接成一个字符串 |
| LOWER(str) | 将字符串str全部转为小写 |
| UPPER(str) | 将字符串str全部转为大写 |
| LPAD(str,n,pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| RPAD(str,n,pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str,start,len) | 返回从字符串str从start位置起的len个长度的字符串 |
演示如下:
A. concat : 字符串拼接
| 1 |
|---|
B. lower : 全部转小写
| 1select lower(‘Hello’); |
|---|
C. upper : 全部转大写
| 1select upper(‘Hello’); |
|---|
D. lpad : 左填充
| 1select lpad(‘01’, 5, ‘-‘); |
|---|
E. rpad : 右填充
| 1select rpad(‘01’, 5, ‘-‘); |
|---|
F. trim : 去除空格
G. substring : 截取子字符串
案例:
| 11d:Iworkno | :IT name | :IT gender | ITl age : | IT 1dcard | :I workaddress | :entrydate | : |
|---|---|---|---|---|---|---|---|
| 11 | 柳岩 | 女 | 20 | 123456789012345678 | 北京 | 2000-01-01 | |
| 22 | 张无品 | 男 | 18 | 123456789012345670 | 北京 | 2005-09-01 | |
| 33 | 韦一笑 | 男 | 38 | 123456789712345670 | 上海 | 2005-08-01 | |
| 44 | 赵敏 | 女 | 18 | 123456757123845670 | 北京 | 2009-12-01 | |
| 55 | 小 | 女 | 16 | 123456769012345678 | 上海 | 2007-07-01 | |
| 66 | 杨通 | 男 | 28 | 12345678931234567X | 北京 | 2006-01-01 | |
| 77 | 范瑶 | 男 | 40 | 123456789212345670 | 北京 | 2005-05-01 | |
| 88 | 绮丝 | 女 | 38 | 123456157123645670 | 天津 | 2015-05-01 | |
| 99 | 范凉凉 | 女 | 45 | 123156789012345678 | 北京 | 2010-04-01 | |
| 10 10 | 陈友谅 | 男 | 53 | 123456789012345670 | 上海 | 2011-01-01 | |
| 11 11 | 张士诚 | 男 | 55 | 123567897123465678 | 江苏 | 2015-05-01 | |
| 12 12 | 常遇春 | 男 | 32 | 123446757152345670 | 北京 | 2004-02-01 | |
| 13 13 | 张三丰 | 男 | 88 | 123656789012345678 | 江苏 | 2020-11-01 | |
| 14 14 | 灭绝 | 女 | 65 | 123456719012345670 | 西安 | 2019-05-01 | |
| 15 15 | 胡青牛 | 男 | 70 | 12345674971234567X | 西安 | 2018-04-01 | |
| 16 16 | 周芷若 | 女 | 18 | <null> | 北京 | 2012-06-01 |
由于业务需求变更,企业员工的工号,统一为5位数,目前不足5位数的全部在前面补0。比如:1号员工的工号应该为00001。
1 update emp set workno = 1pad(workno, 5,’0’);
处理完毕后,具体的数据为:
| 1d: | <workno | IT name | : gender | I age: | I 1dcard | :Iworkaddress | : ITl entrydate | : |
|---|---|---|---|---|---|---|---|---|
| 1 | 00001 | 柳岩 | 女 | 20 | 123456789012345678 | 北京 | 2000-01-01 | |
| 2 | 00002 | 张无忌 | 男 | 18 | 123456789012345670 | 北京 | 2005-09-01 | |
| 3 | 00003 | 韦一笑 | 男 | 38 | 123456789712345670 | 上海 | 2005-08-01 | |
| 4 | 00004 | 赵敏 | 女 | 18 | 123456757123845670 | 北京 | 2009-12-01 | |
| 5 | 00005 | 小绍 | 女 | 16 | 123456769012345678 | 上海 | 2007-07-01 | |
| 6 | 00006 | 杨通 | 男 | 28 | 12345678931234567X | 北京 | 2006-01-01 | |
| 7 | 00007 | 范瑶 | 男 | 40 | 123456789212345670 | 北京 | 2005-05-01 | |
| 8 | 00008 | 能绮丝 | 女 | 38 | 123456157123645670 | 天津 | 2015-05-01 | |
| 9 | 00009 | 范凉凉 | 女 | 45 | 123156789012345678 | 北京 | 2010-04-01 | |
| 10 | 00010 | 陈友谅 | 男 | 53 | 123456789012345670 | 上海 | 2011-01-01 | |
| 11 | 00011 | 张士诚 | 男 | 55 | 123567897123465670 | 江苏 | 2015-05-01 | |
| 12 | 00012 | 常遇春 | 男 | 32 | 123446757152345670 | 北京 | 2004-02-01 | |
| 13 | 00013 | 张三丰 | 男 | 88 | 123656789012345678 | 江苏 | 2020-11-01 | |
| 14 | 00014 | 灭绝 | 女 | 65 | 123456719012345670 | 西安 | 2019-05-01 | |
| 15 | 00015 | 胡青牛 | 男 | 70 | 12345674971234567X | 西安 | 2018-04-01 | |
| 16 | 00016 | 周芷若 | 女 | 18 | <null> | 北京 | 2012-06-01 |
3.2 数值函数
常见的数值函数如下:
| 函数 | 功能 |
|---|---|
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x,y) | 返回x/y的模 |
| RAND() | 返回0~1内的随机数 |
| ROUND(x,y) | 求参数x的四舍五入的值,保留y位小数 |
演示如下:
A. ceil:向上取整
| 1select ceil(1.1); |
|---|
B. floor:向下取整
| 1select floor(1.9); |
|---|
| C. mod:取模 |
| 1select mod(7,4); |
C. mod:取模
| 1select mod(7,4); |
|---|
D. rand:获取随机数
| 1select rand(); |
|---|
E. round:四舍五入
| 1select round(2.344,2); |
|---|

案例:
通过数据库的函数,生成一个六位数的随机验证码。
思路: 获取随机数可以通过rand()函数,但是获取出来的随机数是在0-1之间的,所以可以在其基础上乘以1000000,然后舍弃小数部分,如果长度不足6位,补0
1select lpad(round(rand()*1000000 , 0), 6, ‘0’);
3.3 日期函数
常见的日期函数如下:
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| YEAR(date) | 获取指定date的年份 |
| MONTH(date) | 获取指定date的月份 |
| DAY(date) | 获取指定date的日期 |
| DATE_ADD(date, INTERVAL exprtype) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATEDIFF(date1,date2) | 返回起始时间date1 和 结束时间date2之间的天数 |
演示如下:
A. curdate:当前日期
| 1select curdate(); |
|---|
B. curtime:当前时间
| 1select curtime(); |
|---|
C. now:当前日期和时间
| 1select now(); |
|---|
D. YEAR , MONTH , DAY:当前年、月、日
1select YEAR(now());
2select MONTH(now());
3select DAY(now());
E. $d a t e \underline { a d d }$:增加指定的时间间隔
1select date_add(now(), INTERVAL 70 YEAR );
F. datediff:获取两个日期相差的天数
1select datediff(‘2021-10-01’, ‘2021-12-01’);
案例:
查询所有员工的入职天数,并根据入职天数倒序排序。
思路: 入职天数,就是通过当前日期 - 入职日期,所以需要使用datediff函数来完成。
1select name, datediff(curdate(), entrydate) as ‘entrydays’ from emp order by entrydays desc;
3.4 流程函数
流程函数也是很常用的一类函数,可以在SQL语句中实现条件筛选,从而提高语句的效率。
| 函数 | 功能 |
|---|---|
| IF(value , t , f) | 如果value为true,则返回t,否则返回f |
| IFNULL(value1 , value2) | 如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN [ val1 ] THEN [res1] …ELSE [ default ] END | 如果val1为true,返回res1,… 否则返回default默认值 |
| CASE [ expr ] WHEN [ val1 ] THEN[res1] … ELSE [ default ] END | 如果expr的值等于val1,返回res1,… 否则返回default默认值 |
演示如下:
A. if
1select if(false, ‘Ok’, ‘Error’);
| 1 | select ifnull(‘Ok’,’Default’); |
|---|---|
| 2 | |
| 3 | select ifnull(‘’,’Default’); |
| 4 | |
| 5 | select ifnull(null,’Default’); |
C. case when then else end
需求: 查询emp表的员工姓名和工作地址 (北京/上海 —-> 一线城市 , 其他 —-> 二线城市)
| 1select | 1select |
|---|---|
| 2 | name, |
| 3 | ( case workaddress when ‘北京’ then ‘一线城市’ when ‘上海’ then ‘一线城市’ els’二线城市’ end ) as ‘工作地址’ |
| 4 | from emp; |
案例:
| 1 | create table score( |
|---|---|
| 2 | id int comment ‘ID’, |
| 3 | name varchar(20) comment ‘姓名’, |
| 4 | math int comment ‘数学’, |
| 5 | english int comment ‘英语’, |
| 6 | chinese int comment ‘语文’ |
| 7 | ) comment ‘学员成绩表’; |
| 8 | insert into score(id, name, math, english, chinese) VALUES (1, ‘Tom’, 67, 88, 95 ), (2, ‘Rose’ , 23, 66, 90),(3, ‘Jack’, 56, 98, 76); |
具体的SQL语句如下:
| 1 | select |
|---|---|
| 2 | id, |
| 3 | name, |
| 4 | (case when math 85 then ‘优秀’ when math then ‘及格’ else ‘不及格’ end |
| 5 | ‘数学’, (case when english then ‘优秀’ when english then ‘及格’ else ‘不及格end ) ‘英语’, |
| 6 | (case when chinese then ‘优秀’ when chinese then ‘及格’ else ‘不及格 |
| 7 | end ) ‘语文’from score; |
MySQL的常见函数我们学习完了,那接下来,我们就来分析一下,在前面讲到的两个函数的案例场景,思考一下需要用到什么样的函数来实现?
1). 数据库中,存储的是入职日期,如 2000-01-01,如何快速计算出入职天数呢?答案: datediff
2). 数据库中,存储的是学生的分数值,如98、75,如何快速判定分数的等级呢?
答案: case … when …
4. 约束
4.1 概述
概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中数据的正确、有效性和完整性。
分类:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARYKEY |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束(8.0.16版本之后) | 保证字段值满足某一个条件 | CHECK |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | FOREIGNKEY |
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
4.2 约束演示
上面我们介绍了数据库中常见的约束,以及约束涉及到的关键字,那这些约束我们到底如何在创建表、修改表的时候来指定呢,接下来我们就通过一个案例,来演示一下。
案例需求: 根据需求,完成表结构的创建。需求如下:
| 字段名 | 字段含义 | 字段类型 | 约束条件 | 约束关键字 |
|---|---|---|---|---|
| id | ID唯一标识 | int | 主键,并且自动增长 | PRIMARY KEY,AUTO_INCREMENT |
| name | 姓名 | varchar(10) | 不为空,并且唯一 | NOT NULL , UNIQUE |
| age | 年龄 | int | 大于0,并且小于等于120 | CHECK |
| status | 状态 | char(1) | 如果没有指定该值,默认为1 | DEFAULT |
| gender | 性别 | char(1) | 无 |
对应的建表语句为:
| 1 | CREATE TABLE tb_user( |
|---|---|
| 2 | id int AUTO_INCREMENT PRIMARY KEY COMMENT ‘ID唯一标识 |
| 3 | name varchar(10) NOT NULL UNIQUE COMMENT ‘姓名’ , |
| 4 | age int check && COMMENT ‘年龄’ |
| 5 | status char(1) default ‘1’ COMMENT ‘状态’, |
| 6 | gender char(1) COMMENT ‘性别’ |
| 7 | ); |
在为字段添加约束时,我们只需要在字段之后加上约束的关键字即可,需要关注其语法。我们执行上面的SQL把表结构创建完成,然后接下来,就可以通过一组数据进行测试,从而验证一下,约束是否可以生效。
| 1 | insert into tb_user(name,age,status,gender) values ( | ‘Tom1’,19, ‘男’), |
|---|---|---|
| (‘Tom2’,25,’0’,’男’); | ||
| 2 | insert into tb_user(name,age,status,gender) values ( | ‘Tom3’,19, ‘男’); |
| 3 | ||
| 4 | insert into tb_user(name,age,status,gender) values ( | null,19, 男’); |
| 5 | insert into tb_user(name,age,status,gender) values ( | ‘Tom3’,19, ‘男’); |
| 6 | ||
| 7 | insert into tb_user(name,age,status,gender) values ( | ‘Tom4’,80, ‘男’); |
| 8 | insert into tb_user(name,age,status,gender) values ( | ‘Tom5’,-1,’1’,’男’); |
| 9 | insert into tb_user(name,age,status,gender) values ( | ‘Tom5’,121,’1’,’男’) |
| 10 | ||
| 11 | insert into tb_user(name,age,gender) values (‘Tom5’, | 120,’男’); |
上面,我们是通过编写SQL语句的形式来完成约束的指定,那加入我们是通过图形化界面来创建表结构时,又该如何来指定约束呢? 只需要在创建表的时候,根据我们的需要选择对应的约束即可。

4.3 外键约束
4.3.1 介绍
外键:用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性。
我们来看一个例子:

| 1id | J name | I age | Ill job | II salary | I entrydate | IT managerid | dept_id |
|---|---|---|---|---|---|---|---|
| 1 | 金庸 | 66 | 总裁 | 20000 | 2000-01-01 | <null> | 5 |
| 2 | 张无忌 | 20 | 项目经理 | 12500 | 2005-12-05 | 1 | 1 |
| 3 | 杨道 | 33 | 开发 | 8400 | 2000-11-03 | 2 | 1 |
| 4 | 韦一笑 | 48 | 开发 | 11000 | 2002-02-05 | 2 | 1 |
| 5 | 常遇春 | 43 | 开发 | 10500 | 2004-09-07 | 3 | 1 |
| 员工表emp(子表) | 员工表emp(子表) | 员工表emp(子表) | 员工表emp(子表) | 员工表emp(子表) | 员工表emp(子表) | 员工表emp(子表) | 员工表emp(子表) |
部门表dept(父表)
左侧的emp表是员工表,里面存储员工的基本信息,包含员工的ID、姓名、年龄、职位、薪资、入职日期、上级主管ID、部门ID,在员工的信息中存储的是部门的ID dept_id,而这个部门的ID是关联的部门表dept的主键id,那emp表的dept_id就是外键,关联的是另一张表的主键。
注意:目前上述两张表,只是在逻辑上存在这样一层关系;在数据库层面,并未建立外键关联,所以是无法保证数据的一致性和完整性的。
没有数据库外键关联的情况下,能够保证一致性和完整性呢,我们来测试一下。
1create table dept(
| 2 id int auto_increment comment ‘ID’ primary key, | |
|---|---|
| 3 name varchar(50) not null comment ‘部门名称’ | |
| 4)comment ‘部门表’; | |
| 5INSERT INTO dept (id, name) VALUES (1, ‘研发部’), (2, ‘市场部’),(3, ‘财务部’), (4销售部总经办 | |
| ‘’), (5, ‘’);6 | |
| 7create table emp( | |
| 8 id int auto_increment comment ‘ID’ primary key, | |
| 9 name varchar(50) not null comment ‘姓名’, | |
| 10 age int comment ‘年龄’, | |
| 11 job varchar(20) comment ‘职位’, | |
| 12 salary int comment ‘薪资’, | |
| 13 entrydate date comment ‘入职时间’, | |
| 14 managerid int comment ‘直属领导ID’, | |
| 15 dept_id int comment ‘部门ID’ | |
| 16)comment ‘员工表’; | |
| 17 | |
| 18INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) | |
| VALUES | |
| 19 (1, ‘金庸’, 66, ‘总裁’,20000, ‘2000-01-01’, null,5),(2, ‘张无忌’, 20,’项目经理’,12500, ‘2005-12-05’, 1,1),20 (3, ‘杨逍’, 33, ‘开发’, 8400, 2,1), ‘韦一笑’, 48, ‘开 | |
| 发’,11000, ‘2002-02-05’, 2,1),21 (5, ‘常遇春’, 43, ‘开发’,10500, ‘2004-09-07’, ‘小昭’, 19, ‘序员鼓励师’,6600, ‘2004-10-12’, 2,1); |
接下来,我们可以做一个测试,删除id为1的部门信息。
emp员工表 dept 部门表
| 11d:J name | : |
|---|---|
| 2 市场 | |
| 3 财务 | |
| 4 销售 | |
| 5 总经办 |
| :I name | : I age : | I7 job : | Inl salary : | Ill entrydate | I managerid: | IT dept_1d: |
|---|---|---|---|---|---|---|
| 1 金 | 66 | 总裁 | 20000 | 2000-01-01 | cnull> | |
| 2 张无忌 | 20 | 项目经理 | 12500 | 2005-12-05 | 1 | |
| 3 杨通 | 33 | 开发 | 8480 | 2000-11-03 | ||
| 4 韦笑 | 48 | 开发 | 11000 | 2002-02-05 | 1 | |
| 5 常遇春 | 43 | 开发 | 10500 | 2004-09-07 | 1 | |
| 0小明 | 19 | 程序员鼓师 | 6000 | 2004-10-12 | 1 |
结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。而要想解决这个问题就得通过数据库的外键约束。
4.3.2 语法
1).添加外键
| 2 字段名 | 数据类型, | 数据类型, | 数据类型, | 数据类型, | |
|---|---|---|---|---|---|
| 3 -.. | 主表(主表列名) | ||||
| 4 [CONST | RAINT] [外键 | 名称] FOREIGN | KEY(外键字段名) | REFERENCES | 主表(主表列名) |
| 5 ); | 主表(主表列名) | ||||
| 1 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREREFERENCES 主表(主表列名): | 1 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREREFERENCES 主表(主表列名): | 1 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREREFERENCES 主表(主表列名): | 1 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREREFERENCES 主表(主表列名): | IGN KEY(外键 | 字段名) |
案例:
为emp表的dept_id字段添加外键约束,关联dept表的主键id。
1 alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
| id: | name : | 日age. | < job : | II salary: | II entrydate : | I managerid: | dept_id: |
|---|---|---|---|---|---|---|---|
| 1 | 金 | 66 | 总裁 | 20000 | 2000-01-01 | <null> | 5 |
| 2 | 张无忌 | 20 | 项目经理 | 12500 | 2005-12-05 | 1 | 1 |
| 3 | 杨逍 | 33 | 开发 | 8400 | 2000-11-03 | 2 | 1 |
| 4 | 韦一笑 | 48 | 开发 | 11000 | 2002-02-05 | 2 | 1 |
| 5 | 常遇春 | 43 | 开发 | 10500 | 2004-09-07 | 3 | 1 |
| 6 | 小昭 | 19 | 程序员鼓励师 | 6600 | 2004-10-12 | 2 | 1 |
添加了外键约束之后,我们再到dept表(父表)删除id为1的记录,然后看一下会发生什么现象。此时将会报错,不能删除或更新父表记录,因为存在外键约束。
[23000|[(1451] Cannot delete or update a parent rowr a foreign key constraint fais(hcast.emp’,CONSTRAINT”R_emp,dept id” FOREIGN KEY (dept,id) REFERENCES dept’ (id))
2). 删除外键
1 ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
案例:
删除emp表的外键$f k \underline e m p \underline { d e p t } \underline { i d _ { 0 } }$
1alter table emp drop foreign key$E K _ { - } e m p _ { - } d e p t _ { - } i d ;$
4.3.3 删除/更新行为
添加了外键之后,再删除父表数据时产生的约束行为,我们就称为删除/更新行为。具体的删除/更新行为有以下几种:
| 行为 | 说明 |
|---|---|
| NOACTION | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。 (与 RESTRICT 一致) 默认行为 |
| RESTRICT | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。 (与 NO ACTION 一致) 默认行为 |
| CASCADE | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则也删除/更新外键在子表中的记录。 |
| SET NULL | 当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(这就要求该外键允许取null)。 |
| SETDEFAULT | 父表有变更时,子表将外键列设置成一个默认的值 (Innodb不支持) |
具体语法为:
| 1 | ALTER | TABLE | 表名 | ADD | CONSTRAINT | 外键名称 | FOREIGN KEY | (外键字段) | REFERENCES |
|---|---|---|---|---|---|---|---|---|---|
| 主表名 | (主表字 | 段名) | ON | UPDATE CASCADE ON DELETE CASCADE; | UPDATE CASCADE ON DELETE CASCADE; | UPDATE CASCADE ON DELETE CASCADE; |
演示如下:
由于NO ACTION 是默认行为,我们前面语法演示的时候,已经测试过了,就不再演示了,这里我们再演示其他的两种行为:CASCADE、SET NULL。
1). CASCADE
1 alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
A.修改父表id为1的记录,将id修改为6
| 2 市场部3 财务部4 销售5 总经办6研发部 |
|---|
| 1d:J name | IE age:I job | IE age:I job | I salary: | I entrydate | I managerid: | i dept_1d: | i dept_1d: |
|---|---|---|---|---|---|---|---|
| 1金庸 | 60 总裁 | 60 总裁 | 20008 | 2000-81-81 | <mull> | ||
| 2 张无 | 20 | 项目经理 | 12500 | 2005-12-05 | |||
| 3 杨通 | 33 | 开发 | 8400 | 2000-11-03 | 2 | ||
| 4韦笑 | 48 | 开发 | 11000 | 2002-02-05 | 2 | ||
| 5 常遇查 | 43开发 | 43开发 | 10500 | 2004-09-07 | 3 | ||
| 6小昭 | 19 程序员鼓励师 | 19 程序员鼓励师 | 6600 | 2004-10-12 | 2 |
我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果。
在一般的业务系统中,不会修改一张表的主键值。
B.删除父表id为6的记录
| 21:J name 1 | I age: | 1 job | I satary : | IT entrydate | I managerid: | dept_id: |
|---|---|---|---|---|---|---|
| 1金 | 66 总 | 66 总 | 20000 | 2000-01-01 | <nuLl> | 5 |
| 271d:J1 name |
|---|
| 2 市场 |
| 3 财务 |
| 4 销售部 |
| 5 总经办 |
我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
2). SET NULL
在进行测试之前,我们先需要删除上面建立的外键$E K _ e m p _ { - } d e p t _ { - } d .$。然后再通过数据脚本,将emp、dept表的数据恢复了。
1 alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null;
接下来,我们删除id为1的数据,看看会发生什么样的现象。
| id | name |
|---|---|
| 2 | 市场部 |
| 3 | 财务部 |
| V | 销售部 |
| 5 | 总经办 |

| id | name : |
|---|---|
| 1 | 研发部 |
| 2 | 市场部 |
| 3 | 财务部 |
| 4 | 销售部 |
| 5 | 总经办 |
我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp 的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了。
| id: name : | age: | job : | salary: | entrydate : | managerid: | dept_id: |
|---|---|---|---|---|---|---|
| 1金庸 | 66 | 总裁 | 20000 | 2000-01-01 | <null> | 5 |
| 2 张无忌 | 20 | 项目经理 | 12500 | 2005-12-05 | 1 | <null> |
| 3杨逍 | 33 | 开发 | 8400 | 2000-11-03 | 2 | <null> |
| 4韦一笑 | 48 | 开发 | 11000 | 2002-02-05 | 2 | <null> |
| 5 常遇春 | 43 | 开发 | 10500 | 2004-09-07 | 3 | <null> |
| 6小昭 | 19 | 程序员鼓励师 | 6600 | 2004-10-12 | 2 | <nuLl> |
这就是SET NULL这种删除/更新行为的效果。
5.多表查询
我们之前在讲解sQL语句的时候,讲解了DQL语句,也就是数据查询语句,但是之前讲解的查询都是单表查询,而本章节我们要学习的则是多表查询操作,主要从以下几个方面进行讲解。
5.1 多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
一对多(多对一)
多对多
一对一
5.1.1 一对多
案例:部门与员工的关系
关系:一个部门对应多个员工,一个员工对应一个部门
实现:在多的一方建立外键,指向一的一方的主键
员工表(emp)N 1 部门表(dept)
| id | name | age | dept_id | id | name |
|---|---|---|---|---|---|
| 1 | 张无忌 | 20 | 1 | 1 | 研发部 |
| 2 | 杨逍 | 33 | 1 | 2 | 市场部 |
| 3 | 赵敏 | 18 | 2 | 2 | 市场部 |
| 3 | 赵敏 | 18 | 2 | 3 | 财务部 |
| 4 | 常遇春 | 43 | 2 | 4 | 销售部 |
5.1.2 多对多
案例:学生 与 课程的关系
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
| id | istudentid | courseid |
|---|---|---|
| 1 | 1 | |
| 2 | 1 | 2 |
| 3 | 1 | 3 |
| 2 | 1 | |
| 5 | 2 | 4 |

| Jid | IT name | I7 no |
|---|---|---|
| 1 | 黛绮丝 | 2000100101 |
| 2 | 谢逊 | 2000100102 |
| 3 | 殷天正 | 2000100103 |
| 4 | 韦一笑 | 2000100104 |
| id | IT name |
|---|---|
| 1 | Java |
| 2 | PHP |
| 3 | MySQL |
| 4 | Hadoop |
学生课程关系表(student_course)
学生表(student)N
对应的sQL脚本:
| 1 | create table student( |
|---|---|
| 2 | id int auto increment primary key comment '主键ID', |
| 3 | name varchar(10) comment '姓名”, |
| 4 | no varchar(10) comment '学号” |
| 5 | )comment '学生表”; |
| 6 | insert into student values (nu1l,'黛绮丝",'2000100101'),(nu11,'谢逊”,'20001001021),(nu11,'殷天正','2000100103'),(nu11,'韦一笑','20001001041 |
| 7 | ); |
| 8 | |
| 9 | create table course( |
| 10 | id int auto increment primary key comment '主键ID', |
| 11 | name varchar(10)comment'课程名称” |
| 12 | )comment'课程表”; |
| 13 | insert into course values (null, ‘Java’), (null, ‘PHP’), (null,’MySQL’),(null,’Hadoop’); |
| 14 | |
| 15 | |
| 16 | create table student_course( |
| 17 | id int auto_increment comment ‘主键’ primary key, |
| 18 | studentid int not null comment ‘学生ID’, |
| 19 | courseid int not null comment ‘课程ID’, |
| 20 | constraint fk_courseid foreign key (courseid) references course (id), |
| 21 | constraint fk_studentid foreign key (studentid) references student (id) |
| 22 | )comment ‘学生课程中间表’; |
| 23 | |
| 24 | insert into student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2),(null,2,3),(null,3,4); |
5.1.3 一对一
案例: 用户 与 用户详情的关系
关系: 一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
对应的SQL脚本:
| 1 | create table |
|---|---|
| 2 | id int auto_increment primary key comment ‘主键ID’, |
| 3 | name varchar(10) comment ‘姓名’, |
| 4 | age int comment ‘年龄’, |
| 5 | gender char(1) comment ‘1: 男 , 2: 女’, |
| 6 | phone char(11) comment ‘手机号’ |
| 7 | ) comment ‘用户基本信息表’; |
| 8 | |
| 9 | create table tb_user_edu( |
| 10 | id int auto_increment primary key comment ‘主键ID’, |
| 11 | degree varchar(20) comment ‘学历’, |
| 12 | major varchar(50) comment ‘专业’, |
| 13 | primaryschool varchar(50) comment ‘小学’, |
| 14 | middleschool varchar(50) comment ‘中学’, |
| 15 | university varchar(50) comment ‘大学’, |
| 16 | userid int unique comment ‘用户ID’, |
| 17 | constraint fk_userid foreign key (userid) references tb_user(id) |
| 18 | ) comment ‘用户教育信息表’; |
| 19 | |
| 20 | |
| 21 | insert into tb_user(id, name, age, gender, phone) values |
| 22 | (null,’黄渤’,45,’1’,’18800001111’), |
| 23 | (null,’冰冰’,35,’2’,’18800002222’), |
| 24 | (null,’码云’,55,’1’,’18800008888’), |
| 25 | (null,’李彦宏’,50,’1’,’18800009999’); |
| 26 | |
| 27 | insert into degree, major, primaryschool, middleschool,university, userid) values |
| 28 | (null,’本科’,’舞蹈’,’静安区第一小学’,’静安区第一中学’,’北京舞蹈学院’,1), |
| 29 | (null,’硕士’,’表演’,’朝阳区第一小学’,’朝阳区第一中学’,’北京电影学院’,2), |
| 30 | (null,’本科’,’英语’,’杭州市第一小学’,’杭州市第一中学’,’杭州师范大学’,3), |
| 31 | (null,’本科’,’应用数学’,’阳泉第一小学’,’阳泉区第一中学’,’清华大学’,4); |
5.2 多表查询概述
5.2.1 数据准备
1). 删除之前 emp, dept表的测试数据
2). 执行如下脚本,创建emp表与dept表并插入测试数据
| 1 | – 创建dept表,并插入数据 |
|---|---|
| 2 | create table dept( |
| 3 | id int auto_increment comment ‘ID’ primary key, |
| 4 | name varchar(50) not null comment ‘部门名称’ |
| 5 | )comment ‘部门表’; |
| 6 | INSERT INTO dept (id, name) VALUES (1, ‘研发部’), (2, ‘市场部’),(3, ‘财务部’), (4, |
| 7 | ‘销售部’), (5, ‘总经办’), (6, ‘人事部’); |
| 8 | – 创建emp表,并插入数据 |
| 9 | create table emp( |
| 10 | id int auto_increment comment ‘ID’ primary key, |
| 11 | name varchar(50) not null comment ‘姓名’, age int comment ‘年龄’, |
| 12 | name varchar(50) not null comment ‘姓名’, age int comment ‘年龄’, |
| 13 | job varchar(20) comment ‘职位’, |
| 14 | salary int comment ‘薪资’, |
| 15 | entrydate date comment ‘入职时间’, |
| 16 | managerid int comment ‘直属领导ID’, |
| 17 | dept_id int comment ‘部门ID’ |
| 18 | )comment ‘员工表’; |
| 19 | – 添加外键 |
| 20 | alter table emp add constraint fk_emp_dept_id foreign key (dept_id) referencesdept(id); |
| 21 | |
| 22 | INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES |
| 23 | (1, ‘金庸’, 66, ‘总裁’,20000, ‘2000-01-01’, null,5), |
| 24 | (2, ‘张无忌’, 20, ‘项目经理’,12500, ‘2005-12-05’, 1,1), |
| 25 | (3, ‘杨逍’, 33, ‘开发’, 8400,’2000-11-03’, 2,1), |
| 26 | (4, ‘韦一笑’, 48, ‘开发’,11000, ‘2002-02-05’, 2,1), |
| 27 | (5, ‘常遇春’, 43, ‘开发’,10500, ‘2004-09-07’, 3,1), |
| 28 | (6, ‘小昭’, 19, ‘程序员鼓励师’,6600, , |
| 29 | (7, ‘灭绝’, 60, ‘财务总监’,8500, ‘2002-09-12’, 1,3), |
| 30 | (8, ‘周芷若’, 19, ‘会计’,48000, ‘ , |
| 31 | (9, ‘丁敏君’, 23, ‘出纳’,5250, ‘2009-05-13’, 7,3), |
| 32 | (10, ‘赵敏’, 20, ‘市场部总监’,12500, ‘2004-10-12’, 1,2), |
| 33 | (11, ‘鹿杖客’, 56, ‘职员’,3750, ‘2006-10-03’, 10,2), |
| 34 | (12, ‘鹤笔翁’, 19, ‘职员’,3750, ‘ 10,2), |
| 35 | (13, ‘方东白’, 19, ‘职员’,5500, ‘2009-02-12’, 10,2), |
| 36 | (14, ‘张三丰’, 88, ‘销售总监’,14000, ‘2004-10-12’, 1,4), |
| 37 | (15, ‘俞莲舟’, 38, ‘销售’,4600, ‘2004-10-12’, 14,4), |
| 38 | (16, ‘宋远桥’, 40, ‘销售’,4600, ‘2004-10-12’, 14,4), |
| 39 | (17, ‘陈友谅’, 42, null,2000, ‘2011-10-12’, 1,null); |
dept表共6条记录,emp表共17条记录。
5.2.2 概述
多表查询就是指从多张表中查询数据。
原来查询单表数据,执行的sQL形式为:select *from emp;
那么我们要执行多表查询,就只需要使用逗号分隔多张表即可,如: select * from emp,dept ;具体的执行结果如下:
| I enp.1d: | 1 enp.nane | 17age: | 17 J00 월 | Inl salaryIT entrydate | Il managerid | I dept_id: | Il dept.Id: IT dep | t.nane |
|---|---|---|---|---|---|---|---|---|
| 1 | 金 | 66 | 总款 | 20000 2000-01-01 | ctt> | 5 | 6人事 | |
| 1 | 金 | 06 | 星林 | 20000 2000-01-01 | LL> | 5 | 5 差经办 | |
| 1 | 金 | 66 | 总款 | 20000 2000-01-01 | coll> | 5 | 4 销售 | |
| 1 | 金额 | 66 | 总然 | 29998 2900-01-01 | <nuLL> | 5 | 3 财部 | |
| 1 | 金牌 | 66 | 总款 | 20000 2000-01-01 | cll> | 5 | 2 市部 | |
| 1 | 金 | 00 | 星核 | 200002000-01-01 | nLL | 5 | 1 胡部 | |
| 2 | 张无息 | 20 | 目经理 | 12500 2005-12-05 | 1 | 1 | 6人事 | |
| 2 | 张无品 | 20 | 项经理 | 12508 2905-12-05 | 1 | 1 | 5 总办 | |
| 2 | 张无息 | 20 | 目经理 | 12500 2005-12-05 | 1 | 4 销售 | ||
| 2 | 张无品 | 20 | 项经理 | 12500 2005-12-05 | 1 | 1 | 3 财部 | |
| 2 | 张无息 | 20 | 目经理 | 12500 2005-12-05 | 1 | 1 | 2 市场部 | |
| 2 | 张无品 | 20 | 项目理 | 12500 2005-12-05 | 1 | 3 | 1 胡部 | |
| 3 | 杨 | 33 | 开发 | 8400 2000-11-03 | 2 | 1 | 6人事 | |
| 3 | 杨 | 33 | 开发 | 8400 2000-11-03 | 2 | 1 | 5 总办 |
此时,我们看到查询结果中包含了大量的结果集,总共102条记录,而这其实就是员工表emp所有的记录(17)与部门表dept所有记录(6)的所有组合情况,这种现象称之为笛卡尔积。接下来,就来简单介绍下笛卡尔积。
笛卡尔积:笛卡尔乘积是指在数学中,两个集合A集合 和 B集合的所有组合情况。



而在多表查询中,我们是需要消除无效的笛卡尔积的,只保留两张表关联部分的数据。




| I mmp.1d:1l emp.name | Ml age: | ET job | Ill satary: | I entrydate | Il managerid: | I dept_id: | dept.id:Edept.name |
|---|---|---|---|---|---|---|---|
| 1 金额 | 60 | 兰 | 20000 | 2000-01-01 | <tL> | 5 | 人事 |
| 1 金 | 66 | 总 | 20000 | 2000-01-01 | coll> | 5 | 5 经办 |
| 1 金额 | 66 | 总 | 20000 | 2000-01-81 | <uLL> | 4 销部 | |
| 1 金 | 66 | 总 | 20000 | 2000-01-01 | cll | 5 | 3 财部 |
| 1 金额 | 00 | 兰 | 20000 | 2000-01-01 | GLL) | 5 | 2 市部 |
| 1 金 | 66 | 总 | 20000 | 2000-01-01 | cll> | 5 | 1研部 |
| 2 张无品 | 20 | 项经理 | 12500 | 2005-12-05 | 人事 | ||
| 2 张无息 | 20 | 项目经理 | 12500 | 200512-05 | 1 | 5 总经办 | |
| 2 张无品 | 20 | 项目经理 | 12500 | 2005-12-05 | 1 | 4 销部 | |
| 2 张无思 | 20 | 项目经理 | 12500 | 2005-12-05 | 1 | 3 财务 | |
| 2 张无品 | 20 | 项经理 | 12500 | 2005-12-05 | 1 | 2 市场 | |
| 2 张无息 | 20 | 项目经理 | 12500 | 2005-12-05 | 1 | 研发 | |
| 3 杨当 | 33 | 开发 | 8400 | 2000-11-03 | 2 | 1 | 人事 |
| 3 杨态 | 33 | 开发 | 8400 | 2000-11-03 | 1 | 5 总经办 |
在sQL语句中,如何来去除无效的笛卡尔积呢?我们可以给多表查询加上连接查询的条件即可。
select * from emp , dept where emp.dept_id= dept.id;
| <1rmm>기G= | <1rmm>기G= | <1rmm>기G= | <1rmm>기G= | ||
|---|---|---|---|---|---|
| IT emp.1d-1 17 emp.name | Il age : I Job | Inl salary : IIl entrydate | I nanagerid: | Idept_1d: | I dept.1d: E dept.name |
| 1 金 | 66 总裁 | 20000 2000-81-81 | <null> | 5 总经办 | |
| 2 张无息 | 20 项目经理 | 12500 2005-12-05 | 1 研发部 | ||
| 3 杨通 | 33 开发 | 8400 2000-11-83 | 1 研发部 | ||
| 4韦笑 | 48 开发 | 11000 2002-02-05 | 1 研发部 | ||
| 5 常遇春 | 43 开发 | 10500 2004-09-87 | 1. 研发部 | ||
| 6小 | 19 程序鼓助师 | 6600 2004-18-12 | 1 | 1 研发部 | |
| 7灭他 | 60 财务总监 | 8500 2002-09-12 | 3 财务部 | ||
| a 用正若 | 19 计 | 48008 2006-86-82 | 7 | 3 财务部 | |
| 9丁君 | 23 出纳 | 5250 2009-05-13 | 3 财务部 | ||
| 10 赵 | 20 市部总监 | 12500 2004-10-12 | 2 市场部 | ||
| 11 鹿容 | 56 职员 | 3750 2006-10-03 | 10 | 2 市场部 | |
| 12 鹤笔 | 19 职员 | 3750 2007-05-09 | 10 | 2 市场部 | |
| 13 东 | 19 职员 | 5500 2009-82-12 | 18 | 2 | 2 市场部 |
| 14 张三丰 | 88 售总 | 14000 2004-10-12 | 4 销售部 | ||
| 15 余舟 | 38 销售 | 4000 2004-10-12 | 14 | 4 | 4 销售部 |
| 16 宋桥 | 40 销售 | 4000 2004-18-12 | 14 | 4 | 4 销售部 |
而由于id为17的员工,没有dept_id字段值,所以在多表查询时,根据连接查询的条件并没有查询到。
5.2.3分类
* 连接查询
。内连接:相当于查询A、B交集部分数据
。外连接:
。左外连接:查询左表所有数据,以及两张表交集部分数据
。右外连接:查询右表所有数据,以及两张表交集部分数据
。自连接:当前表与自身的连接查询,自连接必须使用表别名
* 子查询

5.3 内连接

据。(也就是绿色部分的数据)
内连接的语法分为两种:隐式内连接、显式内连接。先来学习一下具体的语法结构。
1). 隐式内连接
1 SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 … ;
2). 显式内连接
1SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 … ;
案例:
A. 查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)
表结构: emp , dept
连接条件: emp.dept$_ { - } i d = d e p t . i d$
| 1 | select emp.name , dept.name from emp , dept where emp.dept ; |
|---|---|
| 2 | |
| 3 | – 为每一张表起别名,简化SQL编写 |
| 4 | select e.name,d.name from emp e , dept d where e.dept_id = d.id; |
B. 查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现) — INNER JOIN …ON …
表结构: emp , dept
连接条件:$e m p \cdot d e p t _ { - } d = d e p t . i d$
| 1 | select e.name, d.name from emp e inner join dept d |
|---|---|
| 2 | |
| 3 | – 为每一张表起别名,简化SQL编写 |
| 4 | select e.name, d.name from emp e join dept d on e.dept_id = d.id; |
| 表的别名: ①. tablea as 别名1 , tableb as 别名2 ; ②. tablea 别名1 , tableb 别名2 ; |
|---|
| 注意事项: |
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
5.4 外连接

外连接分为两种,分别是:左外连接 和 右外连接。具体的语法结构为:
1). 左外连接
1SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 … ;
左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
2). 右外连接
1SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 … ;
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
案例:
A. 查询emp表的所有数据, 和对应的部门信息
由于需求中提到,要查询emp的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
表结构: emp, dept
连接条件:emp⋅deptid=dept.id
1select e.*, d.name from emp e left outer join dept d on e.dept_id = d.id;
2
3select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
B. 查询dept表的所有数据, 和对应的员工信息(右外连接)
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
表结构: emp, dept
连接条件:$e m p \cdot d e p t _ { - } d = d e p t . i d$
| 1selec | t d., e. | from emp | e right o | uter join |
|---|---|---|---|---|
| 2 | ||||
| 3selec | t d., e. | from dept | d left o | uter join |
注意事项:
左外连接和右外连接是可以相互替换的,只需要调整在连接查询时SQL中,表结构的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
5.5 自连接
5.5.1 自连接查询
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。我们先来学习一下自连接的查询语法:
1 SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 … ;
而对于自连接查询,可以是内连接查询,也可以是外连接查询。
案例:
A. 查询员工 及其 所属领导的名字
表结构: emp
1select a.name , b.name from emp a , emp b where a.managerid = b.id;
B. 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来 表结构: emp a , emp b
1 select a.name '员工',b.name '领导'from emp a left join emp b on a.managerid-b.id;
注意事项:
在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底是哪一张表的字段。
5.5.2 联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
| 1 | SELECT | 字段列表 | FROM | 表A … |
|---|---|---|---|---|
| 2 | UNION | [ ALL] | ||
| 3 | SELECT | 字段列表 | FROM | 表B …./ |
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union a11 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
案例:
A.将薪资低于5000的员工,和年龄大于50岁的员工全部查询出来.
当前对于这个需求,我们可以直接使用多条件查询,使用逻辑运算符or 连接即可。那这里呢,我们也可以通过union/union a11来联合查询.
1 select *from emp where salary < 5000
2 union all
3 select * from emp where age > 50;
| id: | JI name : | age: | job | salary: | entrydate | managerid: | dept_id: |
|---|---|---|---|---|---|---|---|
| 11 鹿杖客 | 11 鹿杖客 | 56 | 职员 | 3750 | 2006-10-03 | 10 | 2 |
| 12 鹤笔翁 | 12 鹤笔翁 | 19 | 职员 | 3750 | 2007-05-09 | 10 | 2 |
| 15 | 俞莲舟 | 38 | 销售 | 4600 | 2004-10-12 | 14 | 4 |
| 16 | 宋远桥 | 40 | 销售 | 4600 | 2004-10-12 | 14 | 4 |
| 17 | 陈友谅 | 42 | <null> | 2000 | 2011-10-12 | 1 | <null> |
| 1 | 金庸 | 66 | 总裁 | 20000 | 2000-01-01 | <null> | 5 |
| 7 | 灭绝 | 68 | 财务总监 | 8500 | 2002-09-12 | 1 | 3 |
| 11 | 鹿杖客 | 56 | 职员 | 3750 | 2006-10-03 | 10 | 2 |
| 14 | 张三丰 | 88 | 销售总监 | 14000 | 2004-10-12 | 1 | 4 |
1 select * from emp where salary < 5000
2 union
3 select * from emp where age > 50;
| id: | name : | age: | job : | salary: | entrydate | IT managerid: | dept_id: |
|---|---|---|---|---|---|---|---|
| 11 | 鹿杖客 | 56 | 职员 | 3750 | 2006-10-03 | 10 | 2 |
| 12 | 鹤笔翁 | 19 | 职员 | 3750 | 2007-05-09 | 10 | 2 |
| 15 | 俞莲舟 | 38 | 销售 | 4600 | 2004-10-12 | 14 | 4 |
| 16 | 宋远桥 | 40 | 销售 | 4600 | 2004-10-12 | 14 | 4 |
| 17 | 陈友谅 | 42 | <null> | 2000 | 2011-10-12 | 1 | <null> |
| 1 | 金 | 66 | 总裁 | 20000 | 2000-01-01 | cnull> | 5 |
| 7 | 灭绝 | 60 | 财务总监 | 8500 | 2002-09-12 | 1 | 3 |
| 14 | 张三丰 | 88 | 销售总监 | 14000 | 2004-10-12 | 1 | 4 |
union 联合查询,会对查询出来的结果进行去重处理。
注意:
如果多条查询语句查询出来的结果,字段数量不一致,在进行union/union a11联合查询时,将会报错。如:


5.6 子查询
5.6.1 概述
1).概念
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
1 SELECT* FROM t1 WHERE column1= (SELECT column1 FROM t2);
子查询外部的语句可以是INSERT / UPDATE / DELETE /SELECT 的任何一个。
2).分类
根据子查询结果不同,分为:
A. 标量子查询(子查询结果为单个值)
B. 列子查询(子查询结果为一列)
C. 行子查询(子查询结果为一行)
D. 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
A. WHERE之后
B. FROM之后
C. SELECT之后
5.6.2 标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符:=⋄>>=<<=
案例:
A. 查询 “销售部” 的所有员工信息
完成这个需求时,我们可以将需求分解为两步:
①. 查询 “销售部” 部门ID
| 1 | select id | from dept | where name | = ‘销售部’; |
|---|
②. 根据 “销售部” 部门ID, 查询员工信息
1select * from emp where $\det _ { - - } i d = ( s e l e c t$id from dept where name = ‘销售部’);
B. 查询在 “方东白” 入职之后的员工信息
完成这个需求时,我们可以将需求分解为两步:
①. 查询 方东白 的入职日期
1select entrydate from emp where name = ‘方东白’;
②. 查询指定入职日期之后入职的员工信息
1select * from emp where entrydate > (select entrydate from emp where name = ‘方东白’);
5.6.3 列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
案例:
A. 查询 “销售部” 和 “市场部” 的所有员工信息
分解为以下两步:
①. 查询 “销售部” 和 “市场部” 的部门ID
1select id from dept where name = ‘销售部’ or name = ‘市场部’;
②. 根据部门ID, 查询员工信息
1select * from emp where dept_id in (select id from dept where name = ‘销售部’ or name=’市场部’);
分解为以下两步:
①. 查询所有 财务部 人员工资
1select id from dept where name = ‘财务部’;
2
3select salary from emp where det1d=(sec1ectid from dept where name = ‘财务部’);
②. 比 财务部 所有人工资都高的员工信息
1select * from emp where8a1axy>a11 ( select salary from emp where dept_id = (select id from dept where name = ‘财务部’) );
C. 查询比研发部其中任意一人工资高的员工信息
分解为以下两步:
①. 查询研发部所有人工资
1select salary from emp where dept_id = (select id from dept where name = ‘研发部’);
②. 比研发部其中任意一人工资高的员工信息
1select * from emp where sa1axy>any( select salary from emp where dept_id = (select id from dept where name = ‘研发部’) );
5.6.4 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
A. 查询与 “张无忌” 的薪资及直属领导相同的员工信息 ;
这个需求同样可以拆解为两步进行:
①. 查询 “张无忌” 的薪资及直属领导
1select salary, managerid from emp where name = ‘张无忌’;
②. 查询与 “张无忌” 的薪资及直属领导相同的员工信息 ;
1select * from emp where (salary,managerid) = (select salary, managerid from emp where name = ‘张无忌’);
5.6.5 表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
案例:
A. 查询与 “鹿杖客” , “宋远桥” 的职位和薪资相同的员工信息分解为两步执行:
①. 查询 “鹿杖客” , “宋远桥” 的职位和薪资
1select job, salary from emp where name = ‘鹿杖客’Orname=’宋远桥’;
②. 查询与 “鹿杖客” , “宋远桥” 的职位和薪资相同的员工信息
1select * from emp where (job,salary) in ( select job, salary from emp where name =’鹿杖客’ or name = ‘宋远桥’ );
B. 查询入职日期是 “2006-01-01” 之后的员工信息 , 及其部门信息分解为两步执行:
①. 入职日期是 “2006-01-01” 之后的员工信息
1select * from emp where entrydate > ‘2006-01-01’;
②. 查询这部分员工, 对应的部门信息;
1select e., d. from (select * from emp where entrydate > ‘2006-01-01’) e left join dept d on e.dept_id = d.id ;
5.7 多表查询案例
数据环境准备:
| 1 | create table salgrade( | create table salgrade( | |
|---|---|---|---|
| 2 | grade int, | grade int, | |
| 3 | losal int, | losal int, | |
| 4 | hisal int | hisal int | |
| 5 | ) comment ‘薪资等级表’; | ) comment ‘薪资等级表’; | |
| 6 | |||
| 7 | insert int | o salgrade values | (1,0,3000); |
| 8 | insert int | o salgrade values | (2,3001,5000); |
| 9 | insert int | o salgrade values | (3,5001,8000); |
| 10 | insert int | o salgrade values | (4,8001,10000); |
| 11 | insert int | o salgrade values | (5,10001,15000); |
| 12 | insert int | o salgrade values | (6,15001,20000); |
| 13 | insert int | o salgrade values | (7,20001,25000); |
| 14 | insert int | o salgrade values | (8,25001,30000); |
在这个案例中,我们主要运用上面所讲解的多表查询的语法,完成以下的12个需求即可,而这里主要涉及到的表就三张:emp员工表、dept部门表、sa1grade薪资等级表 。
1). 查询员工的姓名、年龄、职位、部门信息 (隐式内连接)
表: emp , dept
连接条件:$e m p \cdot d e p t _ { - } d = d e p t . i d$
1select e.name , e.age , e.job , d.name from emp e , dept d where e.dept$_ { - } i d = d . i d ;$
2). 查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接)
表: emp, dept
连接条件: emp.detpt⊥d=detpt.id
1select e.name , e.age , e.job , d.name from emp e inner join dept d on e.dept_id =d.id wheree.aqe<30;
3). 查询拥有员工的部门ID、部门名称
表: emp,dept
连接条件: emp.$\det _ { - } d = \det .$⋅id
1select distinct d.id , d.name from emp e , dept d where e.dept_id = d.id;
4). 查询所有年龄大于40岁的员工, 及其归属的部门名称; 如果员工没有分配部门, 也需要展示出来(外连接)
表: emp , dept
连接条件: emp$. d e p t _ { - } i d = \det p t . i d$
1select e.*, d.name from emp e left join dept d on$e . d e p t _ { - } d = d .$.1dwhere e.age >40 ;
5). 查询所有员工的工资等级
表: emp , salgrade
连接条件 : emp.salary>=salgrade.losal and emp.salary <=salgrade.hisal
| 1 | – 方式一 |
|---|---|
| 2 | select e.* , s.grade , s.losal, s.hisal from emp e , salgrade s where e.salary >=s.losal and e.salary |
| 3 | – 方式二 |
| 4 | select e.* , s.grade , s.losal, s.hisal from emp e , salgrade s where e.salary between s.losal and s.hisal; |
6). 查询 “研发部” 所有员工的信息及 工资等级
表: emp , salgrade , dept
连接条件 : emp.salary between salgrade.losal and salgrade.hisal ,
emp.$\det _ { - } d = \det . i d$
查询条件 : dept.name=’研发部’
7). 查询 “研发部” 员工的平均工资
表: emp⋅dept
连接条件 : $e m p \cdot d e p t _ { - } d = d e p t . i d$
1select avg(e.salary) from emp e, dept d where e.dept_id = d.id and d.nam=研发部’;
8). 查询工资比 “灭绝” 高的员工信息。
①. 查询 “灭绝” 的薪资
1select salary from emp where name = ‘灭绝’;
②. 查询比她工资高的员工数据
1 select * from emp where salary > ( select salary from emp where name = ‘灭绝’ );
9). 查询比平均薪资高的员工信息
①. 查询员工的平均薪资
| 1 | select avg(salary) from emp; |
|---|
②. 查询比平均薪资高的员工信息
1select * from emp where salary > ( select avg(salary) from emp );
10). 查询低于本部门平均工资的员工信息
①. 查询指定部门平均薪资
1select avg(e1.salary) from emp e1 where e1.dept_id = 1;
2select avg(e1.salary) from emp e1 where e1.dept_id = 2;
②. 查询低于本部门平均工资的员工信息
1select * from emp e2 where e2.salary < ( select avg(e1.salary) from emp e1 where e1.dept1d=e2.dept⊥d);
11). 查询所有的部门信息, 并统计部门的员工人数
1select d.id, d.name , ( select count(*) from emp e where e.dept_id = d.id ) ‘人数’from dept d;
12). 查询所有学生的选课情况, 展示出学生名称, 学号, 课程名称
表: student , course , student_course
连接条件: student.id = student_course.studentid , course.id =
student_course.courseid
1select s.name , s.no , c.name from student s , student_course sc , course c where s.id = sc.studentid and8C.COurseid=c.5d ;
备注: 以上需求的实现方式可能会很多, SQL写法也有很多,只要能满足我们的需求,查询出符合条件的记录即可。
6. 事务
6.1 事务简介
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
就比如: 张三给李四转账1000块钱,张三银行账户的钱减少1000,而李四银行账户的钱要增加1000。 这一组操作就必须在一个事务的范围内,要么都成功,要么都失败。

正常情况: 转账这个操作, 需要分为以下这么三步来完成 , 三步完成之后, 张三减少1000, 而李四增加1000, 转账成功 :
查询张三账户余额
张三账户余额-1000
| id | name : | money |
|---|---|---|
| 1 | 张三 | 1000 |
| 2 | 李四 | 3000 |
李四账户余额+1000
异常情况:转账这个操作,也是分为以下这么三步来完成,在执行第三步是报错了,这样就导致张三减少1000块钱,而李四的金额没变,这样就造成了数据的不一致,就出现问题了。

| !id: | name | money |
|---|---|---|
| 1 | 张三 | 1000 |
| 2 | 李四 | 2000 |
为了解决上述的问题,就需要通过数据的事务来完成,我们只需要在业务逻辑执行之前开启事务,执行完毕后提交事务。如果执行过程中报错,则回滚事务,把数据恢复到事务开始之前的状态。

注意:默认MySQL的事务是自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐式的提交事务。
6.2 事务操作
数据准备:
| 1 | drop table if exists account; |
|---|---|
| 2 | |
| 3 | create table account( |
| 4 | id int primary key AUTO_INCREMENT comment ‘ID’, |
| 5 | name varchar(10) comment ‘姓名’, |
| 6 | money double(10,2) comment ‘余额’ |
| 7 | ) comment ‘账户表’; |
| 8 | |
| 9 | insert into account(name, money) VALUES (‘张三’,2000), (‘李四’,2000); |
6.2.1 未控制事务
1). 测试正常情况
| 1 | – 1. 查询张三余额 |
|---|---|
| 2 | select * from account where ‘张三’; |
| 3 | – 2. 张三的余额减少1000 |
| 4 | update account set where ‘张三’; |
| 5 | – 3. 李四的余额增加1000 |
| 6 | update account set where ‘李四’; |
测试完毕之后检查数据的状态, 可以看到数据操作前后是一致的。
2). 测试异常情况
| 1 | – 1. 查询张三余额 |
|---|---|
| 2 | select * from account where name ‘张三’; |
| 3 | – 2. 张三的余额减少1000 |
| 4 | update account set where ‘张三’; |
| 5 | 出错了…. |
| 6 | – 3. 李四的余额增加1000 |
| 7 | update account set where ‘李四’; |
我们把数据都恢复到2000, 然后再次一次性执行上述的SQL语句(出错了…. 这句话不符合SQL语法,执行就会报错),检查最终的数据情况, 发现数据在操作前后不一致了。
6.2.2 控制事务一
1). 查看/设置事务提交方式
| 1 | SELECT | @@autocommit ; |
|---|---|---|
| 2 | SET | @@autocommit = 0 ; |
2). 提交事务

| 1COMMIT; |
|---|
3). 回滚事务

注意:上述的这种方式,我们是修改了事务的自动提交行为, 把默认的自动提交修改为了手动提交, 此时我们执行的DML语句都不会提交, 需要手动的执行commit进行提交。
6.2.3 控制事务二
1). 开启事务
| 1 | START | TRANSACTION | 或 BEGIN ; |
|---|
2). 提交事务
| 1COMMIT; |
|---|
3). 回滚事务

转账案例:
| 1 | – 开启事务 |
|---|---|
| 2 | start transaction |
| 3 | |
| 4 | – 1. 查询张三余额 |
| 5 | select * from account where name = ‘张三’; |
| 6 | |
| 7 | – 2. 张三的余额减少1000 |
| 8 | update account set where ‘张三’; |
| 9 | |
| 10 | – 3. 李四的余额增加1000 |
| 11 | update account set where ‘李四’; |
| 12 | |
| 13 | – 如果正常执行完毕, 则提交事务 |
| 14 | commit; |
| 15 | – 如果执行过程中报错, 则回滚事务 |
| 16 | – rollback; |
6.3 事务四大特性
原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
上述就是事务的四大特性,简称ACID。

6.4 并发事务问题
1). 赃读:一个事务读到另外一个事务还没有提交的数据。

比如B读取到了A未提交的数据。
2). 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。

事务A两次读取同一条记录,但是读取到的数据却是不一样的。
3). 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了 “幻影”。

6.5 事务隔离级别
为了解决并发事务所引发的问题,在数据库中引入了事务隔离级别。主要有以下几种:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read(默认) | × | × | √ |
| Serializable | × | × | × |
1). 查看事务隔离级别
| 1 | SELECT @@TRANSACTION_ISOLATION; |
|---|
2). 设置事务隔离级别
| 1 | SET | [ SESSION | | GLOBAL ] | TRANSACTION ISOLATION | LEVEL | { READ UNCOMMITTED |
| – | – | – | – | – | – | – |
| | READ | COMMITTED | | REPEATABLE | READ | SERIALIZABLE } | | |
Mysql进阶
1. 存储引擎
1.1 MySQL体系结构

1). 连接层
最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于客户端/服务端工具实现的类似于TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
2). 服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
3). 引擎层
存储引擎层, 存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。数据库中的索引是在存储引擎层实现的。
4). 存储层
数据存储层, 主要是将数据(如: redolog、undolog、数据、索引、二进制日志、错误日志、查询日志、慢查询日志等)存储在文件系统之上,并完成与存储引擎的交互。
和其他数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎上,插件式的存储引擎架构,将查询处理和其他的系统任务以及数据的存储提取分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
1.2 存储引擎介绍



大家可能没有听说过存储引擎,但是一定听过引擎这个词,引擎就是发动机,是一个机器的核心组件。比如,对于舰载机、直升机、火箭来说,他们都有各自的引擎,是他们最为核心的组件。而我们在选择引擎的时候,需要在合适的场景,选择合适的存储引擎,就像在直升机上,我们不能选择舰载机的引擎一样。
而对于存储引擎,也是一样,他是mysql数据库的核心,我们也需要在合适的场景选择合适的存储引擎。接下来就来介绍一下存储引擎。
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。我们可以在创建表的时候,来指定选择的存储引擎,如果没有指定将自动选择默认的存储引擎。
1). 建表时指定存储引擎
| 1 | CREATE TABLE 表名( | CREATE TABLE 表名( | CREATE TABLE 表名( | CREATE TABLE 表名( |
|---|---|---|---|---|
| 2 | 字段1 | 字段1类型 | [ COMMENT | 字段1注释 |
| 3 | …… | |||
| 4 | 字段n | 字段n类型 | [COMMENT | 字段n注释 ] |
| 5 | ) ENGINE = | INNODB | [ COMMENT | 表注释 ] ; |
2). 查询当前数据库支持的存储引擎
示例演示:
A.查询建表语句 —默认存储引擎:InnoDB
| 1 | show create table account; |
|---|
CREATE TABLE “account’(
‘1d’ int NOT NLL AUTO_INCREMENT COMMENT ‘ID’,
'name" varchar(10)DEFAULT NULL CONMENT “姓名”,
'money' double(10,2)DEFAULT NULL COMMENT '余额”,
PRIMARY KEY (1d)
)ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_a1_c1 COMMENT='账户表”
我们可以看到,创建表时,即使我们没有指定存储疫情,数据库也会自动选择默认的存储引擎。
B.查询当前数据库支持的存储引擎
| 1 show engines; |
|---|
| NEHORY | YES | Hash based,stored In menory,useful for tenporary tables | NO | NO | NO |
|---|---|---|---|---|---|
| PRS_MYISAM | YES | cottection of identicat nyISAN tabtes | NO | NO | |
| CSV | YES | CSV storage engine | NO | NO | |
| FEDERATED | NO | Federated lySQL storage engine | 4uL> | emuLL> | mULL |
| PERFORMANCE_SCHENA | YES | Perfornance Schena | NO | NO | |
| PyTSAN | YES | MyISAN starage engine | NO | ND | NO |
| Inna08 | DEFAULT | Supports transactions,rom-tevel Locking,and foreign keys | YES | YES | YES |
| ELACKHOLE | YES | /dew/null storage engine Canythang you write to it disappears) | NO | ND | NO |
| ARCHIVE | YES | Archdve storage engine | N0 | N0 | NO |
c.创建表my_myisam,并指定MyISAM存储引擎
| 1 | create table$m y m y i s a m ($ |
|---|---|
| 2 | id int, |
| 3 | name varchar(10) |
| 4 | ) $e n g \in e = M y T S A M$% |
D.创建表my_memory,指定Memory存储引擎
| 1 | create tablemy_memory( |
|---|---|
| 2 | id int, |
| 3 | name varchar(10) |
| 7 | $e n g \in e = M e m o x y$% |
1.3存储引擎特点
上面我们介绍了什么是存储引擎,以及如何在建表时如何指定存储引擎,接下来我们就来介绍下来上面重点提到的三种存储引擎 InnoDB、MyISAM、Memory的特点。
1.3.1 InnoDB
1). 介绍
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL 5.5 之后,InnoDB是默认的MySQL 存储引擎。
2). 特点
DML操作遵循ACID模型,支持事务;
行级锁,提高并发访问性能;
支持外键FOREIGN KEY约束,保证数据的完整性和正确性;
3). 文件
xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm-早期的 、sdi-新版的)、数据和索引。
参数:innodb_file_per_table
1show variables like ‘innodb_file_per_table’;
如果该参数开启,代表对于InnoDB引擎的表,每一张表都对应一个ibd文件。 我们直接打开MySQL的数据存放目录: C:\ProgramData\MySQL\MySQL Server 8.0\Data , 这个目录下有很多文件夹,不同的文件夹代表不同的数据库,我们直接打开itcast文件夹。
可以看到里面有很多的ibd文件,每一个ibd文件就对应一张表,比如:我们有一张表 account,就有这样的一个account.ibd文件,而在这个ibd文件中不仅存放表结构、数据,还会存放该表对应的索引信息。 而该文件是基于二进制存储的,不能直接基于记事本打开,我们可以使用mysql提供的一个指令 ibd2sdi ,通过该指令就可以从ibd文件中提取sdi信息,而sdi数据字典信息中就包含该表
的表结构。

4). 逻辑存储结构

表空间 : InnoDB存储引擎逻辑结构的最高层,ibd文件其实就是表空间文件,在表空间中可以包含多个Segment段。
段 : 表空间是由各个段组成的, 常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。
区 : 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
页 : 页是组成区的最小单元,页也是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
行 : InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的,在每一行中除了定义表时所指定的字段以外,还包含两个隐藏字段(后面会详细介绍)。
1.3.2 MyISAM
1). 介绍
MyISAM是MySQL早期的默认存储引擎。
2). 特点
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
3). 文件
xxx.sdi:存储表结构信息
xxx.MYD: 存储数据
xxx.MYI: 存储索引
1.3.3 Memory
1). 介绍
Memory引擎的表数据时存储在内存中的,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
2). 特点
内存存放
hash索引(默认)
3).文件
xxx.sdi:存储表结构信息
1.3.4 区别及特点
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
| 题: InnoDB引擎与MyISAM引擎的区别 ?①. InnoDB引擎, 支持事务, 而MyISAM不支持。 |
|---|
| ②. InnoDB引擎, 支持行锁和表锁, 而MyISAM仅支持表锁, 不支持行锁。③. InnoDB引擎, 支持外键, 而MyISAM是不支持的。 |
| 主要是上述三点区别,当然也可以从索引结构、存储限制等方面,更加深入的回答,具体参下官方文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-introduction.htmlhttps://dev.mysql.com/doc/refman/8.0/en/myisam-storage-engine.html |
1.4 存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
InnoDB: 是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
MyISAM : 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
2. 索引
2.1 索引概述
2.1.1 介绍
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。

一提到数据结构,大家都会有所担心,担心自己不能理解,跟不上节奏。不过在这里大家完全不用担心,我们后面在讲解时,会详细介绍。
2.2 演示
表结构及其数据如下:
| id | name | age |
|---|---|---|
| 1 | 金庸 | 36 |
| 2 | 张无忌 | 22 |
| 3 | 杨逍 | 33 |
| 4 | 韦一笑 | 48 |
| 5 | 常遇春 | 53 |
| 6 | 小昭 | 19 |
| 7 | 灭绝 | 45 |
| 8 | 周芷若 | 17 |
| 9 | 丁敏君 | 23 |
| 10 | 赵敏 | 20 |
假如我们要执行的sQL语句为: select * from user whereaqe=45
1).无索引情况

| 0x07 | qid | name | age |
|---|---|---|---|
| 0x07 | 1 | 金庸 | 36 |
| 0x56 | 2 | 张无忌 | 22 |
| 0x6A | 3 | 杨逍 | 33 |
| 0xF3 | 丰全表 | 48 | |
| 0x90 | 常遇春 | 53 | |
| 0x77 | 扫描 | 19 | |
| 0xD1 | 7 | 灭绝 | 45 |
| 0x32 | 8 | 周艺若 | 17 |
| 0xE5 | 9 | 丁敏君 | 23 |
| 0xF2 | 10 | 赵敏 | 20 |
| 无索引 | 无索引 | 无索引 | 无索引 |

在无索引情况下,就需要从第一行开始扫描,一直扫描到最后一行,我们称之为 全表扫描,性能很低。
2).有索引情况
如果我们针对于这张表建立了索引,假设索引结构就是二叉树,那么也就意味着,会对aage这个字段建立一个二叉树的索引结构。
| id | name | age | ||
|---|---|---|---|---|
| 0x07 | 1 | 金庸 | 36 | 36 |
| 0x56 | 2 | 张无忌 | 22 | |
| 0x6A | 3 | 杨逍 | 33 | 22 48 |
| 0xF3 | 4 | 韦一笑 | 48 | |
| 0x90 | 5 | 常遇春 | 53 19 |
33 $4 5$ 53 |
| 0x77 | 6 | 小昭 | 19 | |
| 0xD1 | 7 | 灭绝 | 45 | |
| 0x32 | 8 | 周芷若 | 17 2017 | 23 |
| 0xE5 | 9 | 丁敏君 | 23 | |
| 0xF2 | 10 | 赵敏 | 20 | |
| 有索引 | 有索引 | 有索引 | 有索引 | 有索引 |
此时我们在进行查询时,只需要扫描三次就可以找到数据了,极大的提高的查询的效率。
备注:这里我们只是假设索引的结构是二叉树,介绍一下索引的大概原理,只是一个示意图,并不是索引的真实结构,索引的真实结构,后面会详细介绍。
2.3 特点
| 优势 | 劣势 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列也是要占用空间的。 |
| 通过索引列对数据进行排序,降低数据排序的成本,降低cPU的消耗。 | 索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、DELETE时,效率降低。 |
2.2 索引结构
2.2.1 概述
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持 B+ 树索引 |
| Hash索引 | 底层数据结构是用哈希表实现的, 只有精确匹配索引列的查询才有效, 不支持范围查询 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES |
上述是MySQL中所支持的所有的索引结构,接下来,我们再来看看不同的存储引擎对于索引结构的支持情况。
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
注意: 我们平常所说的索引,如果没有特别指明,都是指B+树结构组织的索引。
2.2.2 二叉树
假如说MySQL的索引结构采用二叉树的数据结构,比较理想的结构如下:

如果主键是顺序插入的,则会形成一个单向链表,结构如下:

所以,如果选择二叉树作为索引结构,会存在以下缺点:
顺序插入时,会形成一个链表,查询性能大大降低。
大数据量情况下,层级较深,检索速度慢。
此时大家可能会想到,我们可以选择红黑树,红黑树是一颗自平衡二叉树,那这样即使是顺序插入数据,最终形成的数据结构也是一颗平衡的二叉树,结构如下:

但是,即使如此,由于红黑树也是一颗二叉树,所以也会存在一个缺点:
大数据量情况下,层级较深,检索速度慢。
所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,那么什么是B+Tree呢?在详解B+Tree之前,先来介绍一个B-Tree。
2.2.3 B-Tree
B-Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。
以一颗最大度数 (max-degxee)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key,5个指针:

知识小贴士: 树的度数指的是一个节点的子节点个数。
我们可以通过一个数据结构可视化的网站来简单演示一下。 https://www.cs.usfca.edu/\~gall es/visualization/BTree.html

插入一组数据:100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88120 268 250。然后观察一些数据插入过程中,节点的变化情况。

特点:
5阶的B树,每一个节点最多存储4个key,对应5个指针。
一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。
在B树中,非叶子节点和叶子节点都会存放数据。
2.2.4 B+Tree
B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4(4阶)的b+tree为例,来看一下其结构示意图:

我们可以看到,两部分:
绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
我们可以通过一个数据结构可视化的网站来简单演示一下。https://www.cs.usfca.edu/~ga11es/visualization/BPlusTree.htm1
| B+Trees | B+Trees | B+Trees | B+Trees | B+Trees |
|---|---|---|---|---|
| Insert | Datine Find OM | ax. Degree=3 | ||
| Max. Degree=4Max. Degree-5 | Max. Degree=4Max. Degree-5 | Max. Degree=4Max. Degree-5 | Max. Degree=4Max. Degree-5 | |
| O Max. Degree=6 | O Max. Degree=6 | O Max. Degree=6 | O Max. Degree=6 | |
| Max.Degree-7 | Max.Degree-7 | Max.Degree-7 | Max.Degree-7 |
插入一组数据: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88120 268 250 。然后观察一些数据插入过程中,节点的变化情况。

最终我们看到,B+Tree与 B-Tree相比,主要有以下三点区别:
所有的数据都会出现在叶子节点。
叶子节点形成一个单向链表。
非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
上述我们所看到的结构是标准的B+Tree的数据结构,接下来,我们再来看看MySQL中优化之后的B+Tree.
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。

2.2.5 Hash
MySQL中除了支持B+Tree索引,还支持一种索引类型—Hash索引。
1). 结构
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。


如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。


2). 特点
A. Hash索引只能用于对等比较(=,∈),不支持范围查询(between,>,< ,…)
B. 无法利用索引完成排序操作
C. 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
3). 存储引擎支持
在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能,hash索引是InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
A. 相对于二叉树,层级更少,搜索效率高;
B. 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
C. 相对Hash索引,B+tree支持范围匹配及排序操作;
2.3 索引分类
2.3.1 索引分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建, 只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
2.3.2 聚集索引&二级索引
而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(ClusteredIndex) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(SecondaryIndex) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚集索引和二级索引的具体结构如下:

聚集索引的叶子节点下挂的是这一行的数据 。
二级索引的叶子节点下挂的是该字段值对应的主键值。
接下来,我们来分析一下,当我们执行如下的SQL语句时,具体的查找过程是什么样子的。

具体过程如下:
①. 由于是根据name字段进行查询,所以先根据ame=Arm’到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
②. 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。
③. 最终拿到这一行的数据,直接返回即可。
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
| 思考题: |
|---|
| 以下两条SQL语句,那个执行效率高? 为什么? |
| A. select * from user ; |
| B. select * from user where ; 备注: id为主键,name字段创建的有索引; |
| 解答: |
| A 语句的执行性能要高于B 语句。 |
| 因为A语句直接走聚集索引,直接返回数据。 而B语句需要先查询name字段的二级索引,然后再查询聚集索引,也就是需要进行回表查询。 |
| 思考题: InnoDB主键索引的B+tree高度为多高呢? |
|---|

假设:
一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB的指针占用6个字节的空间,主键即使为bigint,占用字节数为8。
高度为2:
n*8+(n+1)6=161024 , 算出n约为 1170
1171*16=18736
也就是说,如果树的高度为2,则可以存储 18000 多条记录。
高度为3:
1171117116=21939856
也就是说,如果树的高度为3,则可以存储 2200w 左右的记录。
2.4 索引语法
1). 创建索引
| 1 | CREATE | [ UNIQUE | | FULLTEXT | ] INDEX | index_nam | e ON tab | le_name ( |
| – | – | – | – | – | – | – | – |
2). 查看索引
| 1 | SHOW | INDEX | FROM | table_name ; |
|---|
3). 删除索引
1DROP INDEX index_name ON table_name ;
案例演示:
先来创建一张表 $t b _ u s e r ,$,并且查询测试数据。
1create table $t b _ u s e r ($
2 id int primary key auto_increment comment ‘主键’,
3 name varchar(50) not null comment ‘用户名’,
4 phone varchar(11) not null comment ‘手机号’,
5 email varchar(100) comment ‘邮箱’,
6 profession varchar(11) comment ‘专业’,
7 age tinyint unsigned comment ‘年龄’,
8 gender char(1) comment ‘性别 , 1: 男, 2: 女’,
9 status char(1) comment ‘状态’,
10 createtime datetime comment ‘创建时间’
- comment ‘系统用户表’;
12
13INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘吕布’, ‘17799990000’, ‘lvbu666@163.com‘, ‘软件工程’, 23, ‘1’,’6’, ‘2001-02-02 00:00:00’);
14INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘曹操’, ‘17799990001’, ‘caocao666@qq.com‘, ‘通讯工程’, 33,’1’, ‘0’, ‘2001-03-05 00:00:00’);
15INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘赵云’, ‘17799990002’, ‘17799990@139.com‘, ‘英语’, 34, ‘1’,’2’, ‘2002-03-02 00:00:00’);
16INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘孙悟空’, ‘17799990003’, ‘17799990@sina.com‘, ‘工程造价’, 54,’1’, ‘0’, ‘2001-07-02 00:00:00’);
17INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘花木兰’, ‘17799990004’, ‘19980729@sina.com‘, ‘软件工程’, 23,’2’, ‘1’, ‘2001-04-22 00:00:00’);
18INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘大乔’, ‘17799990005’, ‘daqiao666@sina.com‘, ‘舞蹈’, 22, ‘2’,’0’, ‘2001-02-07 00:00:00’);
19INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘露娜’, ‘17799990006’, ‘luna_love@sina.com‘, ‘应用数学’, 24,’2’, ‘0’, ‘2001-02-08 00:00:00’);
20INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘程咬金’, ‘17799990007’, ‘chengyaojin@163.com‘, ‘化工’, 38,’1’, ‘5’, ‘2001-05-23 00:00:00’);
21INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘项羽’, ‘17799990008’, ‘xiaoyu666@qq.com‘, ‘金属材料’, 43,’1’, ‘0’, ‘2001-09-18 00:00:00’);
22INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘白起’, ‘17799990009’, ‘baiqi666@sina.com‘, ‘机械工程及其自动化’, 27, ‘1’, ‘2’, ‘2001-08-16 00:00:00’);
23INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘韩信’, ‘17799990010’, ‘hanxin520@163.com‘, ‘无机非金属材料工程’, 27, ‘1’, ‘0’, ‘2001-06-12 00:00:00’);
24INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘荆轲’, ‘17799990011’, ‘jingke123@163.com‘, ‘会计’, 29, ‘1’,’0’, ‘2001-05-11 00:00:00’);
25INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘兰陵王’, ‘17799990012’, ‘lanlinwang666@126.com‘, ‘工程造价’,44, ‘1’, ‘1’, ‘2001-04-09 00:00:00’);
26INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘狂铁’, ‘17799990013’, ‘kuangtie@sina.com‘, ‘应用数学’, 43,’1’, ‘2’, ‘2001-04-10 00:00:00’);
27INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘貂蝉’, ‘17799990014’, ‘84958948374@qq.com‘, ‘软件工程’, 40,’2’, ‘3’, ‘2001-02-12 00:00:00’);
28INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘妲己’, ‘17799990015’, ‘2783238293@qq.com‘, ‘软件工程’, 31,’2’, ‘0’, ‘2001-01-30 00:00:00’);
29INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘芈月’, ‘17799990016’, ‘xiaomin2001@sina.com‘, ‘工业经济’, 35,’2’, ‘0’, ‘2000-05-03 00:00:00’);
30INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘嬴政’, ‘17799990017’, ‘8839434342@qq.com‘, ‘化工’, 38, ‘1’,’1’, ‘2001-08-08 00:00:00’);
31INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (‘狄仁杰’, ‘17799990018’, ‘jujiamlm8166@163.com‘, ‘国际贸易’,30, ‘1’, ‘0’, ‘2007-03-12 00:00:00’);
| 32 |
|---|
| 33 |
| 34 |
| 35 |
| 36 |
表结构中插入的数据如下:
nyaql> select*from tb_useri
| id | name | phone | profention | L | age | gender | Saた期 | Cち | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 吕布 | 17799990000 | lvbu666@163.com | 软件工程 | 23 | 2001-02- | 02 00:00:00 | ||||
| 2 | 1 曹操 | 17799990001 | oaocao666@qq.com | 通讯工程 | 33 | 1 | 0 | 2001-03- | 05 00:00:00 | |
| 3 | |赵云 | 17799990002 | 17799990@139.com | 英语 | 34 | 1 | 2 | 2002-03- | 02 00:00:00 | |
| 4 | 1 孙佰空 | 17799990003 | 177999908s.com | 工程造价 | 5 | 2001-$- 0 7 =$$0 2$ | 00:00:00 | |||
| 5 | 花木兰 | 17799990004 | 19980729@810a.com | 软件工程 | 23 | 2001-04- | 22 00:00:00 | |||
| 6 | 1大乔 | 17799990005 | dagiao666@aina.com | 舞面 | 22 | 2 | 2001-02-0700:00:00 | 2001-02-0700:00:00 | ||
| 7 | 1星非 | 177999900 | Luna Love@sina.com | 应用数学 | 24 | 2 | 2001-02-0800:00:00 | 2001-02-0800:00:00 | ||
| 8 | 1程咬金 | 17799990007 | chengyaojinf163.com | 化工 | 39 | 5 | $2 0 0 1 - 0 5 - 2 3$ | 00:00:00 | ||
| 9 | 1 项羽 | 17799990000 | xiaoyuece@qq.com | 金属材料 | 43 | F | 2001-09- | 18 00100100 | ||
| 10 | 1日起 | 17799990009 | balqi666@sina.com | 机械工程及具自动化 | 27 | 2 | 2001-08- | 16 00:00:00 | ||
| 11 | 1韩信 | 17799990010 | hanxin5208163.com | 无机 金属材料工程 | 27 | $2 0 0 1 - 0 6 - 1 2$00:00:00 | $2 0 0 1 - 0 6 - 1 2$00:00:00 | |||
| 12 | 1 荆轲 | 17799990011 | jingke123@163.com | 会计 | 29 | 0 | $2 0 0 1 - 0 5 - 1 1$ 00:00:00 | $2 0 0 1 - 0 5 - 1 1$ 00:00:00 | ||
| 13 | 1兰陵王 | 17799990012 | Ianlinwang666@126.com | 工程选价 | 44 | 2001-04-0900:00:00 | 2001-04-0900:00:00 | |||
| 14 | 狂铁 | 17799990013 | kuangcie@sina.com | 应用数学 | 43 | 2 | $2 0 0 1 - 0 4 - 1 0$00:00:00 | $2 0 0 1 - 0 4 - 1 0$00:00:00 | ||
| 15 | :招碎 | 17799990014 | 104959949374@qq.com | 软件工程 | 40 | 2 | $2 0 0 1 - 0 2 - 1 2$00:00:00 | $2 0 0 1 - 0 2 - 1 2$00:00:00 | ||
| 16 | 1组己 | 17799990015 | 21032332938qq.com | 软件工程 | 31 | 0 | $2 0 0 1 - 0 1 - 2 0$00:00:00 | $2 0 0 1 - 0 1 - 2 0$00:00:00 | ||
| 17 | 1半月 | 17799990016 | xiaonin2001@sina.com | 工业经济 | 35 | 2000-05- | 03 00:00:00 | |||
| 16 | |真改 | 177999900171 | 6339434342@qq.com | 化工 | 35 | 1 | 1 | 2001-08- | 08 00:00:00 | |
| 19 | 1狄仁杰 | 17799990018 | 1jujianlm8166@163.com | 国际贸易 | 30 | 1 | 0 | $2 0 0 7 - 0 3 - 1 2$00:00:00 | $2 0 0 7 - 0 3 - 1 2$00:00:00 | |
| 20 | |安琪拉 | 17799990019 | jdodnth@126.com | 城市规划 | 51 | 。 | 2001-09-1500:00:00 | 2001-09-1500:00:00 | ||
| 21 | \ 典韦 | 17799990020 | ycaunanjian@163.com | 城市规划 | 52 | 2 | $2 0 0 0 - 0 4 - 1 2$00:00:00 | $2 0 0 0 - 0 4 - 1 2$00:00:00 | ||
| 22 | 麻颖 | 17799990021 | 1ianpo321@126.com | 土木工程 | 19 | 1 | 3 | 2002-07-1800:00:00 | 2002-07-1800:00:00 | |
| 23 | 1后 | 17799990022 | altycj2000@139.com | 城市回林 | 20 | 11 | 0 | 2002-03-1000:00:00 | ||
| 24 | 1 善子牙 | 17799990023 | 374838448qq.com | 工程造价 | 29 | 11 | 4 | 2003-05-26 00:00:00 | 2003-05-26 00:00:00 |
数据准备好了之后,接下来,我们就来完成如下需求:
A.name字段为姓名字段,该字段的值可能会重复,为该字段创建索引。
1 CREATE INDEX idx_user_name ON tb_user(name);
B.phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引。
1 CREATE UNIQUE INDEX idx user_phone ONtb_user(phone);
C.为profession、age、status创建联合索引。
1 CREATE INDEX$i d x _ u s e r p r o a q e _ s t a O $tb_user(profession,age,status);
D.为emai1建立合适的索引来提升查询效率。
| 1 | CREATE |
|---|
完成上述的需求之后,我们再查看$t b _ u s e r$表的所有的索引数据。
1 show index from tb_user;
| Toa | Lay S | In | Ene | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MTEFT | TK | ||||||||||||||
| Licssne | - | ITIFE | TE2 | ||||||||||||
| Lb UE | FA | ITREE | CES | ||||||||||||
| t seer | MTEET | TS | M | ||||||||||||
| L a0 | |||||||||||||||
| LDGE | ataLuR | ITHEE |
Ln ws (0.00
2.5 SQL性能分析
2.5.1 SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
| 1 | –session 是查看当前会话; |
|---|---|
| 2 | –global 是查询全局数据; |
| 3 | SHOW GLOBAL STATUS LIKE Com |
| G | OL OTATO |
|---|---|
| Variabienan | e |
| com Bintog | |
| Com cole | |
| com delete | 11 |
| con InportCcn_1 | 10 1189 |
| 1Con kepair | 10 |
| Com repoke | 10 |
| Con select | 1 21809 |
| com signal | 10 |
| Con updateCom xe end | 0 |
| 11 rows in oet10.08다 | 11 rows in oet10.08다 |
Com delete:删除次数
Com_insert: 插入次数
Com_select: 查询次数
Com_update: 更新次数
我们可以在当前数据库再执行几次查询操作,然后再次查看执行频次,看看 Com_select 参数会不会变化。

通过上述指令,我们可以查看到当前数据库到底是以查询为主,还是以增删改为主,从而为数据库优化提供参考依据。 如果是以增删改为主,我们可以考虑不对其进行索引的优化。 如果是以查询为主,那么就要考虑对数据库的索引进行优化了。
那么通过查询SQL的执行频次,我们就能够知道当前数据库到底是增删改为主,还是查询为主。 那假如说是以查询为主,我们又该如何定位针对于那些查询语句进行优化呢? 次数我们可以借助于慢查询日志。
接下来,我们就来介绍一下MySQL中的慢查询日志。
2.5.2 慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 $s l o w \underline { q u e r y } l o q 。$

如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
1# 开启MySQL慢日志查询开关
2 $s l o w \underline { q u e r y } 1 0 g = 1$
3# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
4 $l o n g _ q u e r y _ t i m e = 2$
配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息/var/lib/mysq1/localhost-slow.log。
| 1 |
|---|
然后,再次查看开关情况,慢查询日志就已经打开了。

| Yarialin Valu |
| $8 1 0 0 0 0 0 0 0 0 0 0 0$ ON |
测试:
A.执行如下sQL语句:
| select * |
|---|
| select c |
| 13.35sec |
| I count() |
|---|
| 10000000 |
| 1 rov in set(13.35sec) |
B.检查慢查询日志:
最终我们发现,在慢查询日志中,只会记录执行时间超多我们预设时间(2s)的sQL,执行较快的sQL
| 。[rootelocalhost mysql]| tail f 1ccalhost-slow.1og/usr/sbin/mysqld,Version:8.0.26 (MysQL Conmunity ServerGPL).started wTcp port:3306 Unix socket:/var/1ib/mysql/mysq1.sockTimo Id command Argument |
| – |
| Timo:2021-10-28T15:45:39.6886798# User@Host: root(root) @ localhost [] Id: 8!Query_time: 13.350650 Lock_time: 0.000358 Rows sent:1 Rows examined: 0use iteast;SET timestamp-1635435926; |
那这样,通过慢查询日志,就可以定位出执行效率比较低的sQL,从而有针对性的进行优化。
2.5.3 profile详情
show profiles 能够在做sQL优化时帮助我们了解时间都耗费到哪里去了。通过have_profiling 参数,能够看到当前MySQL是否支持profile操作:
1 SELECT @@have_profiling;
| myaq1> aelent B@have profiling) |
|---|
| @ehave protiting |
| YBS |
| 1 row in set, I warning (0.00 50c) |
| mynq1>myaqi> anlect BBproftlingi |
| deprotiting |
| 0 |
| 1 row in set, I warning (0.00 sec) |
可以看到,当前MysQL是支持 profile操作的,但是开关是关闭的。可以通过set语句在session/globa1级别开启profiling:
1 SET profi1∈g=1;
开关已经打开了,接下来,我们所执行的sQL语句,都会被MysQL记录,并记录执行时间消耗到哪儿去了。我们直接执行如下的sQL语句:
| 1 | select *from$t b _ u s e r :$ |
|---|---|
| 2 | select*from$t b u s e $where$1 d = 1 ;$ |
| 3 | select *from$b _ u s e $where$n a m e =$白起; |
| 4 | select$\cot ( * )$from$t b _ s k u :$ |
执行一系列的业务sQL的操作,然后通过如下指令查看指令的执行耗时:
| 1 | –查看每一条SQL的耗时基本情况 |
|---|---|
| 2 | show profiles; |
| 3 | |
| 4 | – 查看指定query_id的sQL语句各个阶段的耗时情况 |
| 5 | show profile for query query_id; |
| 6 | |
| 7 | –查看指定query_id的SQL语句cPU的使用情况 |
| 8 | show profile cpu for query query_id; |
查看每一条sQL的耗时情况:
myaqi> ahow procites
| Query_ID | Luration | Query | |
|---|---|---|---|
| 21 | 0.00041925 | SELECT DAABASE | |
| 0.01222200 | ShOWdatabases | ||
| 41 | 0.00726975 | shew tabinn | |
| 51 | 0.00162125 | show tables | |
| 61 | 0.00062300 | selectGroa tb_mser | |
| 0.00097975 | selentCcunt(7) fron Cb_ased | ||
| B I | 0.00053200 | select* Grca ta GBer | |
| 91 | 9.94508625 | 20lectcount(*) fron cb_aku | |
| 10 | 0.00366750 | gelectPanavo_proftling | |
| 11 | 0.00035200 | seleetBepzoEiling | |
| 12 | 0.00015650 | LselenBdprofiling | |
| 131 | 00053075 | select Erom to user | |
| 14 | 0.00062125 | solect* Eromtb_user whero 1d-1 | |
| 15 | 0.00741925 | seleetErcm th user where nanes日起 | |
| 16 1 | 9.53712800 | I select count{*} from tb sku |
15 rows in set, 1 warning (0.00 sec)
查看指定sQL各个阶段的耗时情况:
mysql>showprofileLozqEy16:
| Scatus | Dusetton | |
|---|---|---|
| Starting | 000137 | |
| Executing boak on transactio | n | 0.000009 |
| scarting | 0.000028 | |
| checking permissions | 0.000027 | |
| Cpening tablcs | 0.0000 | |
| init | 0.000006 | |
| System 1ock | 0.000010 | |
| optimizing | 0.000022 | |
| 의tatiaticn | 2050.00 | |
| prepacing | 0.000013 | |
| executing | 9.536456 | |
| end | 0.000025 | |
| queryend | 0.000007 | |
| waiting for handler conmit | 0.000013 | |
| closing tables | 0.000014 | |
| Creeing itens | 0.000048 | |
| Jogging nlow qunry | 0.000244 | |
| cleaning up | 0.000024 |
18 rowp in set, 1 warning (0.01 500)
2.5.4 explain
EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在SELECT 语句执行过程中表如何连接和连接的顺序。
语法:
1 –直接在select语句之前加上关键字 explain/desc
2 EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件:
| mysq1>ex | plainselect frcmtb user where id=1; | |
|---|---|---|
| id se | lect_type table partitions type possible_keys | ( key key len I ref FOCE Filtered |
| 11 | SI | MPLE tb_userNULL const I PRIMARY |
| 、 (0.00 sec)TOwin set, 、warning | 、 (0.00 sec)TOwin set, 、warning | 、 (0.00 sec)TOwin set, 、warning |
Explain 执行计划中各个字段的含义:
| 字段 | 含义 |
|---|---|
| id | select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)。 |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等 |
| type | 表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、 index、all 。 |
| possible_key | 显示可能应用在这张表上的索引,一个或多个。 |
| key | 实际使用的索引,如果为NULL,则没有使用索引。 |
| 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。 | |
| rows | MySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。 |
| filtered | 表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。 |
2.6 索引使用
2.6.1 验证索引效率
在讲解索引的使用原则之前,先通过一个简单的案例,来验证一下索引,看看是否能够通过索引来提升数据查询性能。在演示的时候,我们还是使用之前准备的一张表 $t b _ s k u$ , 在这张表中准备了1000w 的记录。
这张表中id为主键,有主键索引,而其他字段是没有建立索引的。 我们先来查询其中的一条记录,看看里面的字段情况,执行如下SQL:
nyaqt> setect* Ercm tb sku whore 1dc110
1d:1
:100000002145001
name: 华为Metal
price:07901
打票:9961
alert nume100
weight:10
create tine:2019-05-01 00:00:00
update_time: 2019-05-01 00:00:00
categozy_came:真皮包
hrand nane:viney
spee:日色1
Sale num:39
commnt_numi o
status: 1
FOw in set (0.00mec)
可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快,因为主键id是有索引的。那么接下来,我们再来根据sn 字段进行查询,执行如下sQL:
1 SELECT FROM tb_sku WHEREsn=’1000000031450011;
| nysql> select* frhtbsku where se-“10200003145001E |
|---|
| $1 厘 米 4 0 0 m$$( a b c m e a n c h a n g n$ |
| d 1cn1549-5 |
| 1igdtem $1 + x = 1 0$ |
| 10000000314 年 8T90 $9 3 0 2$ |
| 1 15001 方Moca1 1Jpg1g70.jpg.wsbphttps://m.360tuy001 2019-05-0100:00:00 Ivine |
| y |
| 2 |
我们可以看到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低。
那么我们可以针对于sn字段,建立一个索引,建立了索引之后,我们再次根据sn进行查询,再来看一下查询耗时情况。
创建索引:
1 create index idx$\underline { } s k u \underline { } s n$ on tbsku(sn);

然后再次执行相同的sQL语句,再次查看sQL的耗时。
1 SELECT FROM $t b _ s k u$ WHEREsn=11000000031450011
| nyaql> select* | frcm tb_sku whore anc110310010031450011.rcw..* | 108 | |
|---|---|---|---|
| Ld: | 1 | ||
| An: | 100000003145001 | ||
| nane: | 华为Meta1 | ||
| price: | 07901 | ||
| nu期: | 9961 | ||
| alert num: | 100 | ||
| image: | httpa://n.360buying.com/mcbi1ocma/a720x7 | 20_3ra/c5590/64/5811657310/234462/5398e8 | 56/59650173N34179777.jpq1@70.jpg.wobp |
| Imagest | https://n.360buying.com/mcb11ecm9/s720x7 | 20_Jts/c5590/64/5811657380/234462/5398885 | 6/5965e173N34179777.1patq70.1pg.vebp |
| weight | 10 | ||
| ereate time: | 2019-05-01 00:00:00 | ||
| update_time: | 2019-05-01 00:00:00 | ||
| category_name1 | 真皮包 | ||
| hrand rane: | viney | ||
| ne: | 自色: | ||
| sale num: | 39 | ||
| coment_num: | 0 | ||
| status: | status: | status: | |
| Fow in st(0.01 sec) | Fow in st(0.01 sec) | Fow in st(0.01 sec) | Fow in st(0.01 sec) |
我们明显会看到,sn字段建立了索引之后,查询性能大大提升。建立索引前后,查询耗时都不是一个数量级的。
2.6.2 最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
以 tb_user表为例,我们先来查看一下之前$t b _ u s e r$表所创建的索引。
| T | Non_undga | e | I Colunn_ne | Sardinality | Indp | Connt | Indexcoent | Vable | Expon | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | ||||||||||||||
| phane | ||||||||||||||
| Ls HD | 1AS | |||||||||||||
| 3 | At | |||||||||||||
| 1 | 1 | 1 | ||||||||||||
| Ldx anail | *RAI] | TE3 |
in mut (0.00
在$t b \underline u s e r$表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为:profession,age, status。
对于最左前缀法则指的是,查询时,最左变的列,也就是profession必须存在,否则索引全部失效。而且中间不能跳过某一列,否则该列后面的字段索引将失效。接下来,我们来演示几组案例,看一下具体的执行计划:
1 explain select *fromtb_user where profession='软件工程'andaqe=31and status $= \cdot 0 ^ { 1 } ;$
| ayaqi>explain pelect | ayaqi>explain pelect | ayaqi>explain pelect | ayaqi>explain pelect | and statuo | and statuo | and statuo | and statuo | and statuo | and statuo | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| id | selecssype | 1e keys | Key | tre | E | ||||||
| 1 | 0IMP12 | 100.00 | condition | ||||||||
| ECM in oot. I M ning(0.03 | ECM in oot. I M ning(0.03 | ECM in oot. I M ning(0.03 | se0) | se0) | se0) |
1 explain select * from tb_user where profession=软件工程'andaqe=31;
| aelect EEco. | cbusee whoze profooslo | n软件工程* an3 ago | 31 | |||
|---|---|---|---|---|---|---|
| Id | seleos typeI table | 00 | ss1bie kayo Ke | y Ke | y I cet EC | WD riltered1Zass |
| 1 | 8IMELE I tb sserI | NUEL | 49 | comat.comst | 100.00ISILS |
row in set, I warning (0.00 cec)
1 explain select from tb_user where profession='软件工程';
| 1d | l aelect_type | I table | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 1 | 8IMFLE | b user I | NILL | 100.00 | 1MIL |
1 row in ses,1 waraing (0.09 sec)
以上的这三组测试中,我们发现只要联合索引最左边的字段 profession存在,索引就会生效,只不过索引的长度不同。而且由以上三组测试,我们也可以推测出profession字段索引长度为47、age 字段索引长度为2、status字段索引长度为5。
1 explain select fromtb user whereaqe=31and$3 t a t u s = \cdot 0 ^ { \prime } ;$
| 4.17 | Ceing where | |||||||||
| 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 | 1 warning (0.00 5001 |
1 explain select from tb user where status=’0’;
| nyoqlid11 row |
|---|
而通过上面的这两组测试,我们也可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引最左边的列profession不存在。
1 explain select from tb_user where profession=软件工程*and$B t a t u s = \cdot 0 ^ { * } ;$
| 软件程 and atatso |
|---|
| k y |
| 1 cow in aut,1 varning (0.00 ae=) |
上述的sQL查询时,存在profession字段,最左边的列是存在的,索引满足最左前缀法则的基本条件。但是查询时,跳过了age这个列,所以后面的列索引是不会使用的,也就是索引部分生效,所以索引的长度就是47。

当执行sQL语句:explain select * from$t b _ u s e r$whereaqe=31and status = '0' and profession='软件工程'; 时,是否满足最左前缀法则,走不走上述的联合索引,索引长度?
ayegein aele0t Eron to u3eI whece agt=31 abd status end proteosicn-
| 1dl EeItale I taseposee | key ke_len I ret FN ed ta |
|---|---|
| 11 I ED VDOE ML I ret Ldx useE pzo ago s | ta 1ds user peo boe ata 1 34 cossE,const,const 11 200.80 1 Calng Indek cobdition |
1 row in et1 varing 10.00 secl
可以看到,是完全满足最左前缀法则的,索引长度54,联合索引是生效的。
注意:最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是第一个字段)必须存在,与我们编写sQL时,条件编写的先后顺序无关。
2.6.3 范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
1 explain select *fromtb_user where profession='软件工程'and age > 30 and status $= \cdot 0 ^ { * } ;$
| 软件工程 and ag | 软件工程 and ag | e 31oADtatun | e 31oADtatun | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fLitered | Extea | |||||||||||
| 1 | 1 OIMELE | Tde_sser_pro_a0n_ata | Tde_sser_pro_a0n_ata | 149 | 10.00 I | eing inde condition | ||||||
| in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) | in aet, 1 varsing (0:00 0e0) |
当范围查询使用>或<时,走联合索引了,但是索引的长度为49,就说明范围查询右边的status字段是没有走索引的。
| *软件工程 |
|---|
| lng (0.00a) |
当范围查询使用>=或<=时,走联合索引了,但是索引的长度为54,就说明所有的字段都是走索引的。
所以,在业务允许的情况下,尽可能的使用类似于>=或<=这类的范围查询,而避免使用>或<
2.6.4 索引失效情况
2.6.4.1 索引列运算
不要在索引列上进行运算操作,索引将失效。
在tb_user表中,除了前面介绍的联合索引之外,还有一个索引,是phone字段的单列索引。
| Tal | Nosngn | 1ey | 20CoLSAe | COJATON | ICiTy | Su FArE | Pacd | Mall | T | Coment | Inse I1 | ViaLble | on | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tb VeeT | I FRIRT | 3114 | SCES | FIRER | Y23 | SCEI | ||||||||
| 1VOI | Idk O | phose | 21 | NULS | MILG | DIEEE | MTA | |||||||
| Id A | 21 33 | NTEA | VILL | DOFEE | MTI | |||||||||
| 196er | id | peooslon | NSS | DIREE | 158 | M | ||||||||
| 1D S00T | id | Lato | STES | YED | DREE | YE9 | SCEI | |||||||
| IMT | 1i0__ | atatas | N1 | MILG | YE | FINEE | TE | M | ||||||
| 1V | idk | Iap | NTTA | MTLL | YED | DFE | Y | MT | ||||||
| T VT | 10%411 | I emal | N | M | YE | BTEE | TE | MLL |
8 00
A.当根据phone字段进行等值匹配查询时,索引生效。
1 explain select fromtb_user wherephone=17799990015;
| nysql> | explain select | frcm tb uner | where phone= | ‘17795950015’; | ||||
|---|---|---|---|---|---|---|---|---|
| id | select_type | table parti | biona type | posaih$1 e \bot x e y ^ { 3 }$ | I key | $\vert k e y \underline { 2 e n } \vert$r | ef IOKS f | iltered 1Extra |
| 1 1 | 3IMPLE | tb user NULL | const | uaer_phone | idk uaer phon | e 1 46 c | onst 1 | 100.00 |
| 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) | 1 row in set,1 warning (0.00 sea) |
B.当根据phone字段进行函数运算操作之后,索引失效。
1 explain select from tb_user where substring(phone,10,2)=’15’
| nysql> | explain solect | Erom tb_user | where | substr | substr | ||
|---|---|---|---|---|---|---|---|
| id | select_type t | able partitions | Eype | poaaib $O Y E$ | $K O Y$ | kay_len | ref KOMa filter |
| 1← | 3IMPLE t | b_userI NOLL | ALL | NULL | NULL | NULL NULL 24 100. | 00 |
| –1 row in set, 1 warning (0.00 sec) | –1 row in set, 1 warning (0.00 sec) | –1 row in set, 1 warning (0.00 sec) | –1 row in set, 1 warning (0.00 sec) | –1 row in set, 1 warning (0.00 sec) | –1 row in set, 1 warning (0.00 sec) |
2.6.4.2 字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。
接下来,我们通过两组示例,来看看对于字符串类型的字段,加单引号与不加单引号的区别:
1 explain select *fromtb user where profession= 软件工程andaqe=31and status $= 1 0 ^ { \prime }$1
2 explain select * from tb_user where profession=软件工程,andaqe=31and status =0;
| ay | a>exgaia ole | and ago - 31 and status -0 | |||
|---|---|---|---|---|---|
| i | d | seleot pos | stble_keys 1aey 1.keyle | n ref | |
| 1 1 ETHEE | per pro aue ota 1ak user pro aut sta 1 34 | coDT,cst. | conot | 100.00 1 Uslng | |
| 3E | cm In 10.00mec) |
B2ad1>
nyaql>ekplain select ugerMhece Drotes 软件工程and 7-113013at0s-02
| 10 | | meleot | key | $x + y \bot 0 n$ TeT | $x + y \bot 0 n$ TeT | EL | itered ENTEA | |
| – | – | – | – | – | – | – | – |
| 1 | | FINPLE | idk wper_p | ro aue ata 1 15 | ro aue ata 1 15 | | 10.00 | UaingEndex condition | 10.00 | UaingEndex condition |
| row i | n ses,2 varnings (0.00 sec) | | | | | | |
1 explain select *from tb_user where phone = ‘17799990015’;
2 explain select * from tb_user where phone = 17799990015;
phone117793932015
| 1d | selecttype | teble | Teyn | 1ley | lea | I ret | ICWS | $1 t e x e d$ | Ext: | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 PE | ner_chobe | Sdk user chcne | 1 16 | $\cos n s t$ | 100.00 | 1 1 |
1 xow in set, 1 W 10.00 eo
atex phone-177955900151
| 1d I select | posaib1e_Meye | keyI tey len | filtered | Ext | |||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | OTHPLE | NULL I NOLL | NOLL | 2 | 4 10.00 |
I row in set. (0.00 eo)
经过上面两组示例,我们会明显的发现,如果字符串不加单引号,对于查询结果,没什么影响,但是数据库存在隐式类型转换,索引将失效。
2.6.4.3 模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
接下来,我们来看一下这三条sQL语句的执行效果,查看一下其执行计划:
由于下面查询语句中,都是根据profession字段查询,符合最左前缀法则,联合索引是可以生效的,我们主要看一下,模糊查询时,8加在关键字之前,和加在关键字之后的影响。
1 explain select * from tb user where profession like '软件%';
2 explain select*from tb user where profession like '%工程';
3 explain select * from tb_userwhere profession like '%工%';
| ysal> | caplain nelect* frce th | user where p | rofennion 11ke'软件い) | ||||
|---|---|---|---|---|---|---|---|
| 1d、 | select_typeI cable I part | icions | $1 x \cos \theta d x 2 e , x e n y 0$ | Key | key Jen I ret | TOVS1Eilcered I Extra | |
| 1 | 8IHFLE I tb_user I NOLL | x_user_pro_ago_sta | Edx user_pro_age_o | ta 147 NOLL | 100.00 1 U | sing Index condition |
1 row in aot,I warsing (9.01 se0)
nyagl>explain select Ercmtb_9ser where 1001Lxc江程
| id | select_sype | I table I | particions | | possible_keys | 1koy | 1 ley_lea | ret | TON5 | flltere | I Exta |
| – | – | – | – | – | – | – | – | – | – | – |
| 1 I DIHPLE I | to wser I | NULL | | | NOL | I NOLL | NUL | 24 | 11.11 | Using where |
1 omIn 00t, 10:00 40)
nysgl> explain protession e
| id l select type | possible_keys | I key | I key_les | ret | ION5 | filtered | Extra | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 11 BIMELE | NTE | I NOLA | NULL | 24 | 11.11 | Using where |
1 row im ot1 H 1mg(0.00 se0)
经过上述的测试,我们发现,在1ike模糊查询中,在关键字后面加8,索引可以生效。而如果在关键字前面加了%,索引将会失效。
3.6.4.4 or连接条件
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
1 explain select *fromtb_user where1d=100rage=23;
2 explain select * fromtb_user where phone = ‘17799990017’oraqe=23;
| aal> eaplain |
|---|
| id |
코=)
$x ^ { - }$ 755550 DF⋅AB=22:
| BIMPLR | Eey | |||||||
|---|---|---|---|---|---|---|---|---|
| BIMPLR | uepco | 24 | VE0 | |||||
| 10.00 me) | 10.00 me) | 10.00 me) | 10.00 me) | 10.00 me) | 10.00 me) | 10.00 me) | 10.00 me) | 10.00 me) |
由于age没有索引,所以即使id、phone有索引,索引也会失效。所以需要针对于age也要建立索引。
然后,我们可以对age字段建立索引。
1 create indexidxuserageontbuser(aqe);
nyegi> ereate indes ida uenr age on th uaer lngel?
guery ok, o xowa nffected (0.11 seo)
Heoordai o Duplicatent O Marningei 0
建立了索引之后,我们再次执行上述的sQL语句,看看前后执行计划的变化。
| maluis asf44 |sas |
| – |
| 1SILE LLE |
| I oin. Hgials t* fr |
| Idmi |
| 1 14 |
最终,我们发现,当or连接的条件,左右两侧字段都有索引时,索引才会生效。
3.6.4.5 数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
1 select *fromtb_user where phone>= 117799990005’;
2 select *from tb_user where phone >= ‘17799990015’;
nysgl> explain select cm b user where phone 17799590005
| id | select_type | ltable I partitions | type | possible_ke | 1 key | I key len | I ref | | filtered | Extra | |
| – | – | – | – | – | – | – | – | – | – | – |
| 11IMPLE | tb userI NULL | ALL | idx user chone | I NULL | I NUTD | NULL1 | | 79.17 | I Uaing where | |
| | select_type table Part ona | type I key | I key_le | n |ref | | filtered | Extra |
| – | – | – | – | – | – | – |
| | BIKPLE tb_user | range idx user phone | idx_user phone | 1 46 | NULL | 9 1 | 100.00 | Uning Index condition |
1 row in net.
经过测试我们发现,相同的sQL语句,只是传入的字段值不同,最终的执行计划也完全不一样,这是为什么呢?
就是因为MysQL在查询时,会评估使用索引的效率与走全表扫描的效率,如果走全表扫描更快,则放弃索引,走全表扫描。因为索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不如走全表扫描来的快,此时索引就会失效。
接下来,我们再来看看 is nu11 与 is not nu11 操作是否走索引。
执行如下两条语句:
1 explain select * from tb_user where profession is null;
2 explain select * from tb_user where profession is not null;
| paaib | le Laye | kay_Ien | I ref | tarad | ExtEn | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 100.00 | UainInemndis Lan | UainInemndis Lan |
0.00M售)
ny=1>
| Eaya | EOM | filteead | Extra | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| :1 | ATL | NUL | NLL | NOLL | 24 | 100.00 | Uaing where |
10.00
接下来,我们做一个操作将profession字段值全部更新为nu11。
然后,再次执行上述的两条sQL,查看sQL语句的执行计划。
| Trom | T5.L007 | 20O | 00013A | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| id | aelectEyFe | tablc | Fa | possible_Leya | Lay | keycn | SCE | EOMA | filtcred | Eatro | |
| SIHPLS | Th 0502 | NUEL | Al | Idk_us08_p0.o.t | N0CC | C N00L | NULL | 24 | 100.00 | OsteKDere |
S (0.00)sec)
msq1>
maql> caplain aelest frcm th caer whereprofeaaian ia nct null;
| 1d | 1 setect_5ype | Tabe | arEitions | 0oss3b1e_Reys | I key | I key len | 1 rer | rlitered | Bt4 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 SIHLE | th srer | NULL | idx uner pro age ata | l adx aaer Fro age ata | 4) | HULL | 100.00 | Deeg |
1 row in set. 1 warning (0.00 se0)
最终我们看到,一模一样的sQL语句,先后执行了两次,结果查询计划是不一样的,为什么会出现这种现象,这是和数据库的数据分布有关系。查询时MySQL会评估,走索引快,还是全表扫描快,如果全表扫描更快,则放弃索引走全表扫描。 因此,is null、is not nu1l是否走索引,得具体情况具体分析,并不是固定的。
2.6.5 SQL提示
目前tb_user表的数据情况如下:
aelect Ercm tlo_uner
| 1 | d I na | e n:ne | eaa1l | peotessio | n | a01 | e | ndex dz | aEus Icreatetin | e | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 吕 | 布 1779 | 9990000 1vba666@16 | 3.com 软件工程 | 11 | 2001-03- | 02 00100 | 100 | ||||
| 曹 | 課 1779 | 9990001 CaoC0000 | 2.c00 通风工程 | 2001-03- | 05 00:00 | 100 | |||||
| 31赵 | 云 1779 | 9990002 17739398 | 39.com | 2002-07- | 07 00100 | 100 | |||||
| 孙 | 悟空 1779 | 9990003 1773533@ | m 工程证价 | 2021-07- | 02 00:00 | :00 | |||||
| 花 | 木盐 1779 | 9950004 p | a.com 软件工程 | 2001-011- | 22 | 10 | |||||
| 61 大 | 1779 | 5950005 daqian6f6@ | s1na.c00 周后 | 2001-02- | 07 00:00 | :00 | |||||
| 7 国 | 号 1719 | 5950006 Luna Forel | ainaco 血用数学 | 2001-02- | 08 00100 | 100 | |||||
| 程 | 税金 1779 | 9990007 chenggaoji | n163.com | 2001-05- | 23 00100 | 100 | |||||
| 项 | 羽 1779 | 9990008 XI87 | 2.cc0 金属材料 | 2001-09- | 11 00100 | 100 | |||||
| 10 日 | 记 1779 | 9990009 beiqisef8s | ia.com 机械工程 | 及其白动化 | 2001-09- | 16 0010 | 0100 | ||||
| 韩 | 信 1779 | 9990010 hanxin520 | 11.com 无机亚金 | 属材料工程 | 2 | 7 | 2001-06- | 12 00:00 | :00 | ||
| 1 | 21 | 间 1779 | 9950011 Jing | Kocn 合计 | 2 | 9 | 2001-05- | 11 00:00 | :00 | ||
| 1 | 3 兰 | 校王 1719 | 5950012 Laniiawao | 2@126.oom 工程造价 | 2001-04- | 09 00100 | 100 | ||||
| 14 旺 | 铁 1779 | 9990013 Xuo | 血用数学 | 4 | 3 | 2001-04- | 10 00100 | 100 | |||
| 15 旧 | 押 | Hqa.con 现伴工程 | 001-02-10 | 120010 | 0100 | ||||||
| 16 己 | 1779 | 9990015 2783238293 | 80.ocm 软件工程 | 2001-01- | 30 00:00 | :00 | |||||
| 17 | 月 1779 | 9990016 M10omin0 | isina.com 工业经济 | 2000-05- | 03 00:00 | :00 | |||||
| 直 | 政 1779 | 99700 8933474742 | @2.com CI | 2001-08- | 01 00:00 | :00 | |||||
| 19 秋 | 仁杰 1779 | 9950010 | 国际贸易 | 2007-03- | 12 00:00 | :00 | |||||
| 20 安 | 琪地 | 55013mth@12 | 6.com 城市期划 | - | 13 0010 | 0100 | |||||
| 211 典 | 书 1779 | 9990020 yoaunanjia | n@163.oom 城市限划 | 0 | 21 1 | 2000-04- | 12 00100 | 100 | |||
| 22 | 良 | 頭 1779 | 9990021 11aspo | cn 土木工程 | 1 | 9 | 2002-07- | 18 00100 | |||
| 2 | 31后 | 异 1779 | 9990022 altycj2001 | 8139.com 城市日林 | 2 | 0 | 2012-03- | 10 00100 | 100 | ||
| 2 | 4 | 子牙 1779 | 9990023 374338448q | q.com 工程证价 | 2 | 9 | 2001-05- | 26 00100 | 100 |
24 r int (0.00 00)
索引情况如下:
| Taa | Eet | Boe In | Ca Am | Ga4 | Sdinal | Barted | H.1l | Tade Lye | CHrL | Iase D | Tiae | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1F | T | M | NERK | TE | NTA | |||||||||
| u | IEda s phcEs | PhaLe | 24 | ND | 1 | MIEEE | TE | NEA | ||||||
| tb_uner | d_ | nES | 民 | NOTA | TES | NLEA | ||||||||
| HHF | 1 | E F_ | MA | MEF | MA | |||||||||
| 山.unet | 1IH FR CHLA | DEEE | TE | NTA | ||||||||||
| th uer | Lide_er_gro_ee.xta | MEAtUF | TE | N | ||||||||||
| H HE | _ | 1a | TE3 | |||||||||||
| th UREr | 11 | 1 | 1E1 | TE | NTA |
.00
把上述的idx_user_age,idx_emai1 这两个之前测试使用过的索引直接删除。
1 drop index idx_user_age on tb_user;
2 drop index idx_email on tb_user;
A.执行SQL:explain select * from tb user where profession='软件工程';
| nyaq | l> explain select*from tb user where profession='软件工程'; | l> explain select*from tb user where profession='软件工程'; |
|---|---|---|
| I id | I select_type | table I partitions |
| 1 1 | BIMPLE | |
| 1 row in set, 1 warning (0.00 sec) | 1 row in set, 1 warning (0.00 sec) | 1 row in set, 1 warning (0.00 sec) |
查询走了联合索引。
B.执行SQL,创建profession的单列索引:create index idx user pro on
tb_user (profession);
c.创建单列索引后,再次执行A中的sQL语句,查看执行计划,看看到底走哪个索引。
| cm=“软件工程”: | cm=“软件工程”: | cm=“软件工程”: | cm=“软件工程”: | cm=“软件工程”: | cm=“软件工程”: |
|---|---|---|---|---|---|
| filtes | ed | ||||
| 100. | 00 NUE | ||||
| 1E 1 warning (0.00am=) |
测试结果,我们可以看到,possible_keys中 idx_user_pro_age_sta,idx_user_pro 这两个索引都可能用到,最终MySQL选择]了idxuserproaqesta索引。这是MysQL自动选择的结果。
那么,我们能不能在查询的时候,自己来指定使用哪个索引呢?答案是肯定的,此时就可以借助于MySQL的sQI提示来完成。接下来,介绍一下sQL提示。
sQL提示,是优化数据库的一个重要手段,简单来说,就是在sQL语句中加入一些人为的提示来达到优化操作的目的。
1). use index:建议MySQL使用哪一个索引完成此次查询(仅仅是建议,mysq1内部还会再次进行评估)。
1 explain select * from tb_user use index(idx_ user_pro) where profession='软件工程;
2). ignore index:忽略指定的索引。
1 explain select *from tb user ignore index(idx user pro) where profession ='软件工程:
3).force index:强制使用索引。
1 explain select*Eromtb user force index(idx_user_pro) where profession='软件工程写
示例演示:
A. use index
1 explain select * from tb_user use index(idx user_pro) where profession='软件工程:
| nyaql> explain select* from tb user use index(idx_user_pro) where professi | on='软件工程”; |
|---|---|
| lid | select_typeI table partitions type por $k e g s$ key |
| 1 1 31MP18 I th_uaer | NUL ref idx_uaer_pro idx_uae |
| 1 row in met, I warning (0.00 meo) | _ |
B. ignore index
1 explain select * from tb user ignore index(idx user_pro) where profession='软件工程;
| nyeql> explain select* from tb uner ignore index(idx user_pro) where profession='软件工程” |
|---|
| I id |
| I 1 |
| 1 row in aot, 1 warning (0.00 aec) |
C. force index
1 explain select *from tb_user force index(idx_user_pro_age_sta) where profession=软件工程”;
nyaq1> explain select *frcm tb usor force index(idu user pro age sta) where profeasion“软件工程”:
| id | select_type I t | able I partitions | | type I possible_ | keyn 1 key | ke | y_len I ref rovS | 1filtered | Extra |
| – | – | – | – | – | – | – |
| 1 I t | b UReE I NULD | ref idx uaer | pro age_ata Ldw_ue | er pro_age_eta 47 | I conet 4 | 1 100.00 | NULL |
1 row in set,1 warning (0.00 sec)
2.6.6 覆盖索引
尽量使用覆盖索引,减少select*。 那么什么是覆盖索引呢?覆盖索引是指 查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到。
接下来,我们来看一组sQL的执行计划,看看执行计划的差别,然后再来具体做一个解析。
| 1 | explain select id, profession from$t b _ u s e r$where profession-软件工程'and age= |
|---|---|
| 2 | 31 and status=’0’;explain select id,profession,age, status fromtb user where professid$o n =$软件工程and$a q e = 3 1$$a n d s t a t u s = ^ { \prime } 0 ^ { \prime }$; |
| 3 | explain select id,profession,age, status, name fromtb_user where profession=软件工程'and$a q e = 3 1$and$s t a t u s = \cdot 0 ^ { * }$; |
| 4 | explain select *fromtb_user where professio$D n =$软件工程'and$a g e = 3 1$and status$= 1 0 ^ { 1 } ;$ |
上述这几条sQL的执行结果为:
| pauf1d | pauf1d | pauf1d | euaion from L | h sen | whae pouffoaion — | whae pouffoaion — | whae pouffoaion — | Tet | Tet | Ee | Ee | Ee |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NILL | 104.00 | 104.00 | Uing | |||||||||
| 원리 | ||||||||||||
| 원리 | ||||||||||||
| i | d | 45 | 45 | Fate | ||||||||
| MLL | 100.00 | 100.00 | Saing shnuny Daing ins | |||||||||
| F | F | Fes | E | |||||||||
| 104.00 | – - | |||||||||||
I row in met,I warning 10.00mecl
从上述的执行计划我们可以看到,这四条sQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是此时,我们主要关注的是后面的Extra,前面两天sQL的结果为 Using where;Using Index;而后面两条sQL的结果为:Using index condition。
| Extra | 含义 |
|---|---|
| Using where;UsingIndex | 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据 |
| Using indexcondition | 查找使用了索引,但是需要回表查询数据 |
因为,在t$= b _ { - } u s e _ { 1 }$表中有一个联合索引 idx_user_pro_age_sta,该索引关联了三个字段profession、age、status,而这个索引也是一个二级索引,所以叶子节点下面挂的是这一行的主键id。所以当我们查询返回的数据在 id、profession、age、status 之中,则直接走二级索引直接返回数据了。 如果超出这个范围,就需要拿到主键id,再去扫描聚集索引,再获取额外的数据
了,这个过程就是回表。而我们如果一直使用select *查询返回所有字段值,很容易就会造成回表查询(除非是根据主键查询,此时只会扫描聚集索引)。
为了大家更清楚的理解,什么是覆盖索引,什么是回表查询,我们一起再来看下面的这组sQL的执行过程。
A.表结构及索引示意图:
| id | name | gender | Geatedate |
|---|---|---|---|
| 2 | Arm | 2021-01-01 | |
| 3 | Lily | 2021-05-01 | |
| 5 | Rose | 2021-02-14 | |
| 6 | ZOO | 2021-06-01 | |
| 日 | Doc | 2021-03-08 | |
| 11 | Lee | 1 | 2020-12-03 |


id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)。
B.执行sQL select *fromtb_user whereid=2;
| id | name | gender | createdate |
|---|---|---|---|
| 2 | Arm | 2021-01-01 | |
| 3 | Uy | 0 | 2021-05-01 |
| 5 | Rose | 0 | 2021-02-14 |
| 6 | Zoo | 2021-06-01 | |
| 8 | Doc | 2021-03-08 | |
| 11 | Lee | 2020-12-03 |

select*from tb_user where id=t2:
row

根据id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
c.执行SQL:selet id,name fromtb_user wherename$= \cdot A r m ^ { * } ;$

虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,因为覆盖索引,所以不需要回表查询,性能高。
D. 执行SQL:selet id,name,gender from tb_user where $n a m e = \cdot A r m ^ { \prime }$

由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相对较差一点。
| 思考题: 一张表, 有四个字段(id, username, password, status), 由于数据量大,以下SQL语句进行优化, 该如何进行才是最优方案: select id,username,password from tb_user where username = ‘itcast’; 答案: 针对于 username, password建立联合索引, sql为: create indexidx_user_name_pass on tb_user(username,password); |
|---|
2.6.7 前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
1).语法
1 create index idx_xxxx on table_name(column(n));
示例:
为t$t b _ u s e r$表的emai1字段,建立长度为5的前缀索引。
| 1 | create |
|---|
| from t | h_aer | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tabe | Nn | KAT | ne | MHo | Cdy | Pab Dat | ) | ee | Comet | Trdeomen | VTe | x | ||||
| th user | NIML | 15 | YE8 | MH | ||||||||||||
| th uner | Lde se phoe | pacae | NTEB | ITEL | T | NOLL | ||||||||||
| toUseE | 1 | Lisse_0ae | LO | NIES | ETEE | 112 | NOLL | |||||||||
| tb umr | tde ua pro _ | po | LA | SUN | T9 | I MOL | ||||||||||
| t | MTD | FULS | IDE | TEO | I MILL | |||||||||||
| c_user | 1 | tda use pro_han_m | NULS | 10 | ETEEE | T | NLL | |||||||||
| tb unet | Ci | 23 | 证号1 | 10 | 10C | T | MIL |
7 rows in Mt 0.00 이
2).前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
1 select count (distinct email) / count(*) from tb_user;
2 select count (distinct substring(email,1,5))/count(*) from tb_user1
3).前缀索引的查询流程

2.6.8 单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
我们先来看看 tb_user表中目前的索引情况:
| CoLL | GnL | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 18 | MTA | |||||||||||||
| MEL | TEA | MILL | ||||||||||||
| 1 | ML | |||||||||||||
| 1E5 | ME | |||||||||||||
| 1 | ||||||||||||||
| 13 | MLL | |||||||||||||
| Y3 | STREE | 15 | MILL |
在查询出来的索引中,既有单列索引,又有联合索引。
接下来,我们来执行一条sQL语句,看看其执行计划:
hare phine=*17795950010" and nane='西信”
| TaE | I Extra | |||||
|---|---|---|---|---|---|---|
| idx wwer | phone,idx r n | 1.4 | 6 | 100.00 1 |
通过上述执行计划我们可以看出来,在and连接的两个字段 phone、name上都是有单列索引的,但是最终mysq1只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
紧接着,我们再来创建一个phone和name字段的联合索引来查询一下执行计划。
1create unique index idx_user_phone_name on tb_user(phone,name);
此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
如果查询使用的是联合索引,具体的结构示意图如下:

2.7 索引设计原则
1). 针对于数据量较大,且查询比较频繁的表建立索引。
2). 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4). 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
5). 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6). 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
3. SQL优化
3.1 插入数据
3.1.1 insert
如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。
| 1 | insert | into | tb_test | values(1,’tom’); |
|---|---|---|---|---|
| 2 | insert | into | tb_test | values(2,’cat’); |
| 3 | insert | into | tb_test | values(3,’jerry’); |
| 4 | ….. |
1). 优化方案一
批量插入数据
1Insert into tb_test values(1,’Tom’),(2,’Cat’)$, ( 3 , \cdot J e r r y ^ { * } )$
2). 优化方案二
手动控制事务
1start transaction;
2insert into tb⊥test $V a l u e s ( 1 , ^ { \prime } T o m ^ { \prime } )$,$( 2 , ^ { \prime } C a t ^ { \prime } )$,$( 3 , \cdot J e r y ^ { * } )$
3insert into tb⊥test $V a l u e s ( 4 , t g o m ^ { \prime } )$,$( 5 , ^ { * } C a t ^ { * } )$,$( 6 , * J e r x y ^ { * } )$
4insert into tb⊥test $V a l u e s ( 7 , t g o m ^ { \prime } )$,$( 8 , ^ { * } C a t ^ { * } )$,$( 9 , * J e r x y ^ { * } )$
5commit;
3). 优化方案三
主键顺序插入,性能要高于乱序插入。
1主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3
3.1.2 大批量插入数据
如果一次性需要插入大批量数据(比如: 几百万的记录),使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。操作如下:

可以执行如下指令,将数据脚本文件中的数据加载到表结构中:
| 1 | – 客户端连接服务端时,加上参数 |
|---|---|
| 2 | |
| 3 | |
| 4 | – 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关 |
| 5 | set global ; |
| 6 | |
| 7 | – 执行load指令将准备好的数据,加载到表结构中 |
| 8 | load data local infile ‘/root/sql1.log’ into table tb_userterminated by ‘,’ lines terminated by ‘\n’ ; |
主键顺序插入性能高于乱序插入
示例演示:
A. 创建表结构
| 1 | CREATE TABLE tb_user ( |
|---|---|
| 2 | id INT(11) NOT NULL AUTO_INCREMENT, |
| 3 | username VARCHAR(50) NOT NULL, |
| 4 | password VARCHAR(50) NOT NULL, |
| 5 | name VARCHAR(20) NOT NULL, |
| 6 | birthday DATE DEFAULT NULL, |
| 7 | sex CHAR(1) DEFAULT NULL, |
| 8 | PRIMARY KEY (id), |
| 9 | UNIQUE KEY unique_user_username (username) |
| 10 | ) ENGINE=INNODB DEFAULT CHARSET=utf8 ; |
B. 设置参数
| 1 | – 客户端连接服务端时,加上参数 |
|---|---|
| 2 | mysql –-local-infile -u root -p |
| 3 | |
| 4 | – 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关 |
| 5 | set global |
C. load加载数据
| 1 | load | data | local | infile | ‘/root/l | oad_user_100w_sort.sql’ | into | table | tb_user |
|---|---|---|---|---|---|---|---|---|---|
| fields | te | rminated | by ‘,’ | lines | terminated by ‘\n’ ; |
我们看到,插入100w的记录,17s就完成了,性能很好。
3.2 主键优化
在上一小节,我们提到,主键顺序插入的性能是要高于乱序插入的。 这一小节,就来介绍一下具体的原因,然后再分析一下主键又该如何设计。
1). 数据组织方式
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)。

行数据,都是存储在聚集索引的叶子节点上的。而我们之前也讲解过InnoDB的逻辑结构图:

在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储到下一个页中,页与页之间会通过指针连接。
2). 页分裂
页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排列。
A. 主键顺序插入效果
①. 从磁盘中申请页, 主键顺序插入
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| row | row | row | row | row | 6 |
| 1# page | 1# page | 1# page | 1# page | 1# page | 6 |
| 1# page | 1# page | 1# page | 1# page | 1# page | row |
②.第一个页没有满,继续往第一页插入
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| row | row | row | row | row | row | row | row |
1# page
③.当第一个也写满之后,再写入第二个页,页与页之间会通过指针连接

④.当第二页写满了,再往第三页写入

B.主键乱序插入效果
①.加入1#,2#页都已经写满了,存放了如图所示的数据

②.此时再插入id为50的记录,我们来看看会发生什么现象
会再次开启一个页,写入新的页中吗?

不会。因为,索引结构的叶子节点是有顺序的。按照顺序,应该存储在47之后。

但是47所在的1#页,已经写满了,存储不了50对应的数据了。那么此时会开辟一个新的页 3#。


1# page 2# page
但是并不会直接将50存入3#页,而是会将1#页后一半的数据,移动到3#页,然后在3#页,插入50。

47 50

rOw
1# page 28 can0 3# page
移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的。1#的下一个页,应该是3#,3#的下一个页是2#。所以,此时,需要重新设置链表指针。

上述的这种现象,称之为“页分裂”,是比较耗费性能的操作。
3).页合并
目前表中已有数据的索引结构(叶子节点)如下:

当我们对已有数据进行删除时,具体的效果如下:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。

当我们继续删除2#的数据记录

当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。

删除数据,并将页合并之后,再次插入新的数据21,则直接插入3#页

这个里面所发生的合并页的这个现象,就称之为 “页合并”。

4). 索引设计原则
满足业务需求的情况下,尽量降低主键的长度。
插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
业务操作时,避免对主键的修改。

3.3 order by优化
MySQL的排序,有两种方式:
Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
接下来,我们来做一个测试:
A. 数据准备
把之前测试时,为$t b _ u s e r$表所建立的部分索引直接删除掉
1 drop index idx_user phone on tb_user;
2 drop index idx_user_phone name on tb_user;
3 drop index idx_user name on tb_user;
drop n pho
,o 19.03
Recar 0 D0 Maitneo
adrap Lades Lis ares,ghona aane ca th caer;
Qy Oove aff 02
Megaedai Q Duplase 0MaRn
egasl> doap Enine Edas–
QuyO,a attected 10.0202 C
Zmrlar ú Duplinsu00Maaeg
my
| De | I Non_an | Iy | P | Ce | Collation | Nall | Ende | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| th_uner | FREMART | BTREE | 1E | M A | ||||||||||
| -_- | _oe | F | NEE | 13 | NULA | |||||||||
| Lb uar | Idx uaS PED Ap aLa | A | DTREE | : | I34 | |||||||||
| 1 | Mae | NEE | 11 | I MTA | ||||||||||
| 山 u | BTIEE | 1E | NULA |
10.00
B.执行排序SQL
1 explain select id,age,phone from tb_user order by age ;
myaql> explain select id,age,phone from th user order by age:
| I id | se | lect_type I | table I | partition | s I type I | possible_k | eys 1 key | I key_len | I ret I r | ows I filt | ered I Extr | a |
| – | – | – | – | – | – | – | – | – | – | – | – |
| I 1 | BI | NPLE I | tb user I | NULL | 1ALLI | NULL | I NULL | I NULL | I NULL | 10 | 0.00 | Usin | g tilesort |
1 row in set,1 warning (0.01 sec)
1 explain select id,age,phone from tb_user order by age, phone ;
| l> explain aelect id,age,phone from th | uaes order by age,phone; | |
|---|---|---|
| select_type | table partitions | |
| 1 SIMPLE I tb user I NULI I | AL I NULL I NULL I NULL I | NULL 24 1 100.00 |
1 row in aet, 1 warning (0.01 aec)
由于 age,phone 都没有索引,所以此时再排序时,出现Using filesort,排序性能较低。
c.创建索引
| 1 –创建索引 | 1 –创建索引 | 1 –创建索引 | 1 –创建索引 |
|---|---|---|---|
| 2 create index$i d x u s e r a g e p h o n e a a$ | on | tb_user(age,phone); |
D.创建索引后,根据age,phone进行升序排序
1 explain select id,age,phone from tb user order by age;
myagl> explain select id,age,phone frcm tb user order by age;
| | id | aelect_type I table | partitions type possible | y kny | key len | I ref | I rowe i | flltered | flltered | xtra |
| – | – | – | – | – | – | – | – | – |
| | 1 | SIMPLE I tb user I | NULL index | NULL | idx uaer age phone aa | 48 | I NULL | 241 | 100.00 | 1Uaing index | 1Uaing index |
1 row in set, I warning 10.00 eo)
1 explain select id,age,phone from tb user order by age , phone;
nynqi> explain nolect id,age,phone from tb uner order by age, phoner
| id/ | select_type | table | partitions | possible_keys lkey | key_len | I ref | I rows | filtered | Zxtra | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | DINPLE | tb_user | NULL ge phone_aa | 48 | I NUIL | 24 | 1 100.00 | I Using index |
1 row in met, 1 warning (0.00 seo)
建立索引之后,再次进行排序查询,就由原来的Using filesort,变为了 Using index,性能就是比较高的了。
E.创建索引后,根据age,phone进行降序排序
1 explain select id,age,phone from tb user order by age desc, phone desc;
,1 warming 10.00mm)
也出现 Using index,但是此时Extra中出现了 Backward index scan,这个代表反向扫描索引,因为在MysQL中我们创建的索引,默认索引的叶子节点是从小到大排序的,而此时我们查询排序时,是从大到小,所以,在扫描时,就是反向扫描,就会出现 Backward index scan。在MySQL8版本中,支持降序索引,我们也可以创建降序索引。
F.根据phone,age进行升序排序,phone在前,age在后。
1 explain select id,age,phone from tb user order by phone,age;
| Fel | ||||||||
| 48 | NOE 24 1 | 100.00 DaEn nl | mss taing | |||||
| 1 warming (0.00me) | 1 warming (0.00me) | 1 warming (0.00me) |
排序时,也需要满足最左前缀法则,否则也会出现filesort。因为在创建索引的时候,age是第一个字段,phone是第二个字段,所以排序时,也就该按照这个顺序来,否则就会出现 Using filesort.
F.根据age,phone进行降序一个升序,一个降序
| 1 | explain select | id,age,phone |
|---|
| nyogl | >explain aolect des | |
|---|---|---|
| id | selecs_type Table tey | rilsered |
| 1 | 1 0IHP1 | 48 100.00 Unin |
| 2 row in pet, 1 warning (0.00 000) | 2 row in pet, 1 warning (0.00 000) |
因为创建索引时,如果未指定顺序,默认都是按照升序排序的,而查询时,一个升序,一个降序,此时就会出现Using filesort。
| 2M1 | Nn | C | C0 | M | FaCIM | MIl | Sdet | TM | Vlslble | PAETcn | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| th G9er | 114 | 67FRE | Y89 | MEL | |||||||||||
| tb SE | Iprote | saton | DZAED | TED | NTI | ||||||||||
| tb_ser | e | 140 | BTECE | T | MLL | ||||||||||
| th L0e2 | I atata | n | DE | TE | MLL | ||||||||||
| TDG947 | e | BTERE | T | ||||||||||||
| tb 50 | 1 p0 | I | YE0 | MLL | |||||||||||
| TD GOF | aNhme | RRE | T | MLL |
为了解决上述的问题,我们可以创建一个索引,这个联合索引中 age 升序排序,phone 倒序排序。
G.创建联合索引(age 升序排序,phone 倒序排序)
| 1 | create | index | $1 d x \underline { u } s e r \underline { a } g e \underline {$phone_ad | on |
|---|
| T | N | u | BLadex | Celu | 日F | Index coment | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LGd | E3 | |||||||||||||
| Lb_ST | 1Mr | peste | ten | TE3 | ||||||||||
| L S | ||||||||||||||
| Lb_ERE | rpr | ot | MLAto | n | ||||||||||
| Ee ma | onil | TEA | ||||||||||||
| tb: | Lde shar | eP | N& | L | 11 | Nb | ||||||||
| 1F | Ler | phane | TEA | NTA | ||||||||||
| Lax rg | eotad | TE | ||||||||||||
| th.ser | dser_a | ane_ad.gho | Phana | TE3 | NISE |
0.00 리
H.然后再次执行如下SQL
| 1 | explain select | id,age,phone f | rom tb user or | der by age asc | ,phone desc; |
|---|
mysqi> explain selectid.age,phoneFrcm tb_userorder by agePhone deso 7
| id | mniect_type | table | p | osaible_keye I ke | y | key_len re | f IEOKA filte | red | Extra |
| – | – | – | – | – | – | – | – |
| 11 13 | tb uner | NULL | index | N | ULL id | k uaer_age_phone_ | ad l48 | 24 1 100 | .00 | taing Indes |
1 row In set,1 warning (0.01 aeo)
升序/降序联合索引结构图示:
age asc,phone asc 177999900071779999000OA
| 38 9990008 |
1779999 |
|---|---|
| 10 |



| age asc,phone desc | 18 17799990009 |
20 | 23 | 23 | 27 | 33 | 38 | 60 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| age asc,phone desc | 18 17799990009 |
17799990005 | 177999900 | 07 17799990003 | 17799990002 | 17799990004 | 17799990006 | 17799990008 | 17799990001 | 17799990000 |
| 1 | 5 | 3 | 7 | 10 |
由上述的测试,我们得出order by优化原则:
A.根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
B.尽量使用覆盖索引。
c.多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
D.如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
3.4 group by优化
分组操作,我们主要来看看索引对于分组操作的影响。
首先我们先将 tb_user 表的索引全部删除掉。
1 drop index idx user pro age sta on$t b _ u s ;$
2 drop index idx_email_5$o n t b _ u s e r :$
3 drop indexidxuseragehoneaaao$t b _ u a e r :$
4 drop index idx_user_age_phone_ad on tb_user;
| Vinile | Expe | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DTREE | TES | NULA |
接下来,在没有索引的情况下,执行如下sQL,查询执行计划:
1 explain select profession, count(*) from tb_user group by profession;
| nysq1>exptalnseloot proces030 |
|---|
| 1d11 1 8TMPLE |
| La met 、 waralng10.00 |
然后,我们在针对于profession, age, status 创建一个联合索引。
紧接着,再执行前面相同的sQL查看执行计划。
| 1 | explain | select | profession,count(*) | from | tb_user | group | by | profession |
|---|
| nya axplain sele | ct profession,coun | t(*) rrcm th | p by pn / | p by pn / | ||
|---|---|---|---|---|---|---|
| Ld I select_type I | table Par itions | type possible_k | eye I key | hey_l | en I ref fi | ltered IExtra |
| 1 11 11 I | tb user I NUT | index | idw_uner_p | ro_egs_ntn idw_uee | r_pro_age_ata 1 54 | I NUE I 24 |
| ,TOMin set,1 warning10.00 seo) | ,TOMin set,1 warning10.00 seo) | ,TOMin set,1 warning10.00 seo) |
再执行如下的分组查询sQL,查看执行计划:
| myaqI> explain select profenaion,count() from tb_Gaer group by | myaqI> explain select profenaion,count() from tb_Gaer group by | myaqI> explain select profenaion,count() from tb_Gaer group by | myaqI> explain select profenaion,count() from tb_Gaer group by | myaqI> explain select profenaion,count() from tb_Gaer group by | myaqI> explain select profenaion,count() from tb_Gaer group by | Profensicn. | Profensicn. | Profensicn. | Profensicn. | Profensicn. | Profensicn. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 id I | aeleot_type | I table | partitions | Eype | possible_keys | riltered | |||||
| 1 1 | IMPLE | 1 1 | IMPLE | I tb user I NULL Index 54 100.00 1 Ueing inden | I tb user I NULL Index 54 100.00 1 Ueing inden | I tb user I NULL Index 54 100.00 1 Ueing inden | I tb user I NULL Index 54 100.00 1 Ueing inden | I tb user I NULL Index 54 100.00 1 Ueing inden | I tb user I NULL Index 54 100.00 1 Ueing inden | I tb user I NULL Index 54 100.00 1 Ueing inden | I tb user I NULL Index 54 100.00 1 Ueing inden |
myetl> eaplain mlaet Frm — grP
| 1 1 SIHPLE | 1 HUL | 54 | |||
|---|---|---|---|---|---|
| row in sate E saraing 19.9 | 0 mm |
我们发现,如果仅仅根据age分组,就会出现 Using temporary;而如果是 根据
profession,age两个字段同时分组,则不会出现 Using temporary。原因是因为对于分组操作,
在联合索引中,也是符合最左前缀法则的。
所以,在分组操作中,我们需要通过以下两点进行优化,以提升性能:
A.在分组操作时,可以通过索引来提高效率。
B.分组操作时,索引的使用也是满足最左前缀法则的。
3.5 limit优化
在数据量比较大时,如果进行1imit分页查询,在查询时,越往后,分页查询效率越低。
我们一起来看看执行1imit分页查询耗时对比:
| nyngis seletfrom sb_nku 11mit 0,101 |
|---|
| 10ows in sct (0.00 sec) |
| ye1> mietfrom h u iit 1900000,197 |
| 10 rows in set (1.66 500) |
| myaqi>aletfren u ii5000000,101 |
| 10 FOWS IR S6C (10.79 500) |
| nyngi>seiectfrcm tb_aku 11mit 9000000,10: |
| 10 FOMS In 5eE (19.39 300) |
通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在。
因为,当在进行分页查询时,如果执行 1imit 2000000,10,此时需要MySQL排序前2000010 记录,仅仅返回2000000-2000010 的记录,其他记录丢弃,查询排序的代价非常大。
优化思路:一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化。
| 1 | explain | select * | from | tb_sku | t | , (selec | t id | from | tb_sku | order | by | id |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1imit | 2000000,10) | a w | here t.id | = | a.id; |
3.6 count优化
3.6.1 概述
1 select count(*) fromtb_user;
在之前的测试中,我们发现,如果数据量很大,在执行count操作时,是非常耗时的。
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*)的时候会直接返回这个数,效率很高;但是如果是带条件的count,MyISAM也慢。
InnoDB 引擎就麻烦了,它执行 count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
如果说要大幅度提升InnoDB表的count效率,主要的优化思路:自己计数(可以借助于redis这样的数据库进行,但是如果是带条件的count又比较麻烦了)。
3.6.2 count用法
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
| count用法 | 含义 |
|---|---|
| count(主键) | InnoDB 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null) |
| count(字段) | 没有not null 约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。 |
| count(数字) | InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。 |
| count(*) | InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。 |
按照效率排序的话,count(字段)<cott主键 id)<count(1)≈count(),所以尽量使用 count()。
3.7 update优化
我们主要需要注意一下update语句执行时的注意事项。
$n a m e = ^ { x } j a v a E E ^ { \prime }$ 1d=1
当我们在执行删除的SQL语句时,会锁定id为1这一行的数据,然后事务提交之后,行锁释放。
但是当我们在执行如下SQL时。
1update course set name = ‘SpringBoot’ where name = ‘PHP’ ;
当我们开启多个事务,在执行上述的SQL时,我们发现行锁升级为了表锁。 导致该update语句的性能大大降低。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁升级为表锁 。
4. 视图/存储过程/触发器
4.1 视图
4.1.1 介绍
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
通俗的讲,视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
4.1.2 语法
1). 创建
| 1 | CREATE | [OR | REPLACE] | VIEW | 视图名称[(列名列表)] | AS | SELECT语句 | [ WITH [ |
|---|---|---|---|---|---|---|---|---|
| CASCADED | LOCAL ] | CHECK | OPTION ] |
2). 查询
| 1查看创 | 建视图语句 | :SHOW CR | EATE VIEW | 视图名称; |
|---|---|---|---|---|
| 2查看视 | 图数据:SE | LECT * F | ROM 视图 | 名称 ….. |
3). 修改
| 方式一:CREATE | [OR REPLACE] | VIEW 视图名称[(列名列表)] | AS | SELECT语句 | [ WITH |
|---|---|---|---|---|---|
| [ CASCADED | LOCAL ] CHECK | OPTION ] |
2方式二:ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED LOCAL ] CHECK OPTION ]
4). 删除
演示示例:
| 1 | – 创建视图 |
|---|---|
| 2 | create or replace view stu as select id,name from student where |
| 3 | |
| 4 | – 查询视图 |
| 5 | show create view stu ; |
| 6 | |
| 7 | select * from stu_v_1; |
| 8 | select * from stu_v_1 where |
| 9 | |
| 10 | – 修改视图 |
| 11 | create or replace view stu_v_1 as select id,name,no from student where |
| 12 | |
| 13 | alter view stu_v_1 as select id,name from student where id |
| 14 | |
| 15 | |
| 16 | – 删除视图 |
| 17 | drop view if exists stu_v_1; |
上述我们演示了,视图应该如何创建、查询、修改、删除,那么我们能不能通过视图来插入、更新数据呢? 接下来,做一个测试。
| 1 | create or replace view stu as select id,name from student where |
|---|---|
| 2 | |
| 3 | select * from stu ; |
| 4 | |
| 5 | insert into stu values(6,’Tom’); |
| 6 | |
| 7 | insert into st values(17,’Tom22’); |
执行上述的SQL,我们会发现,id为6和17的数据都是可以成功插入的。 但是我们执行查询,查询出来的数据,却没有id为17的记录。
因为我们在创建视图的时候,指定的条件为 id<=10, id为17的数据,是不符合条件的,所以没有查询出来,但是这条数据确实是已经成功的插入到了基表中。
如果我们定义视图时,如果指定了条件,然后我们在插入、修改、删除数据时,是否可以做到必须满足条件才能操作,否则不能够操作呢? 答案是可以的,这就需要借助于视图的检查选项了。
4.1.3 检查选项
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如 插入,更新,删除,以使其符合视图的定义。 MySQL允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项: CASCADED 和 LOCAL ,默认值为 CASCADED 。
1). CASCADED
级联。
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 cascaded,但是v1视图创建时未指定检查选项。 则在执行检查时,不仅会检查v2,还会级联检查v2的关联视图v1。

2). LOCAL
本地。
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 local ,但是v1视图创建时未指定检查选项。 则在执行检查时,知会检查v2,不会检查v2的关联视图v1。

4.1.4 视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,则该视图不可更新:
A. 聚合函数或窗口函数(SUMA. 聚合函数或窗口函数(SUM()、 MIN() ()、 MAX()、 COUNT()等)
B. DISTINCT
C. GROUP BY
D. HAVING
E. UNION 或者 UNION ALL
示例演示:
1create view stu_v_count as select count(*) from student;
上述的视图中,就只有一个单行单列的数据,如果我们对这个视图进行更新或插入的,将会报错。
1insert into stu_v_count values(10);
4.1.5 视图作用
1). 简单
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
2). 安全
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见到的数据
3). 数据独立
视图可帮助用户屏蔽真实表结构变化带来的影响。
4.1.6 案例
1). 为了保证数据库表的安全性,开发人员在操作$t b _ u s e$r表时,只能看到的用户的基本字段,屏蔽手机号和邮箱两个字段。
1create view tb_user_view as select id,name,profession,age,gender,status,createtime from$t b _ u s e r :$
2
3 select*fromtbuserviewi
2). 查询每个学生所选修的课程(三张表联查),这个功能在很多的业务中都有使用到,为了简化操作,定义一个视图。
| create view tb_stu_course_view as se |
|---|
| c.name course_name from student s, s |
| sc.studentid and |
2
3select * from tbstucourseviewi
4.2 存储过程
4.2.1 介绍
存储过程是事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。


特点:
封装,复用 ———————–> 可以把某一业务SQL封装在存储过程中,需要用到的时候直接调用即可。
可以接收参数,也可以返回数据 ——–> 再存储过程中,可以传递参数,也可以接收返回值。
减少网络交互,效率提升 ————-> 如果涉及到多条SQL,每执行一次都是一次网络传输。 而如果封装在存储过程中,我们只需要网络交互一次可能就可以了。
4.2.2 基本语法
1). 创建

2). 调用

3). 查看
| 2SHOW CREATE PROCEDURE | 存储过程名称 ; – 查询某个存储过程的定义 |
|---|
4). 删除
1 DROP PROCEDURE [ IF EXISTS ] 存储过程名称 ;
注意:
在命令行中,执行创建存储过程的SQL时,需要通过关键字 delimiter 指定SQL语句的结束符。
演示示例:
| 1 | – 存储过程基本语法 |
|---|---|
| 2 | – 创建 |
| 3 | create procedure p1() |
| 4 | begin |
| 5 | select count(*) from student; |
| 6 | end; |
| 7 | |
| 8 | – 调用 |
| 9 | call p1(); |
| 10 | |
| 11 | – 查看 |
| 12 | select * from information_schema.ROUTINES where ROUTINE_SCHEMA = ‘itcast’; |
| 13 | |
| 14 | show create procedure p1; |
| 15 | |
| 16 | – 删除 |
| 17 | drop procedure if exists p1; |
4.2.3 变量
在MySQL中变量分为三种类型: 系统变量、用户定义变量、局部变量。
4.2.3.1 系统变量
系统变量 是MySQL服务器提供,不是用户定义的,属于服务器层面。分为全局变量(GLOBAL)、会话变量(SESSION)。
1). 查看系统变量
| 1 | SHOW | [ SESSION | GLOBAL ] | VARIABLES ; | – 查看所有系统变量 |
| – | – | – | – | – |
| 2 | SHOW | [ SESSION | GLOBAL ] | VARIABLES LIKE ‘……’; | – 可以通过LIKE模糊匹配方 |
| 式查找变量 | 式查找变量 | 式查找变量 | 式查找变量 | |
| 3 | SELECT | @@[SESSION | GLOBAL | ] 系统变量名; | – 查看指定变量的值 |
2). 设置系统变量
| 1 | SET | [ SESSION | | GLOBAL | ] 系统变量名 = 值 |
| – | – | – | – | – |
| 2 | SET | @@[SESSION | | GLOBAL | ]系统变量名 = 值 ; |
| 注意: |
|---|
| 如果没有指定SESSION/GLOBAL,默认是SESSION,会话变量。 |
| 1mysql服务重新启动之后,所设置的全局参数会失效,要想不失效,可以在 /etc/my.cnf 中配置。 A. 全局变量(GLOBAL): 全局变量针对于所有的会话。 B. 会话变量(SESSION): 会话变量针对于单个会话,在另外一个会话窗口就不生效了 |
演示示例:
| 1 | – 查看系统变量 |
|---|---|
| 2 | show session variables ; |
| 3 | |
| 4 | show session variables like ‘auto%’; |
| 5 | show global variables like ‘auto%’; |
| 6 | |
| 7 | select @@global.autocommit; |
| 8 | select @@session.autocommit; |
| 9 | |
| 10 | |
| 11 | – 设置系统变量 |
| 12 | set session autocommit = 1; |
| 13 | |
| 14 | insert into course(id, name) VALUES (6, ‘ES’); |
| 15 | |
| 16 | set global autocommit |
| 17 | |
| 18 | select @@global.autocommit; |
4.2.3.2 用户定义变量
用户定义变量 是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用 “@变量名” 使用就可以。其作用域为当前连接。
1). 赋值
方式一:
1SET evarname=expr [,evarname=expr]⋯
2SET 创varname:=e×pr [,(avarname:=expr]⋯
赋值时,可以使用 = ,也可以使用 :=。
方式二:
| 1 | SELECT | [, | |||
|---|---|---|---|---|---|
| 2 | SELECT | 字段名 | INTO @var | _name F | ROM 表名; |
2). 使用

注意: 用户定义的变量无需对其进行声明或初始化,只不过获取到的值为NULL。
演示示例:
| 1 | – 赋值 |
|---|---|
| 2 | |
| 3 | set |
| 4 | set @mygender ‘男’,@myhobby ; |
| 5 | |
| 6 | select @mycolor ; |
| 7 | select count(*) into @mycount from tb_user; |
| 8 | |
| 9 | – 使用 |
| 10 | select @myname,@myage,@mygender,@myhobby; |
| 11 | |
| 12 | select @mycolor , @mycount; |

4.2.3.3 局部变量
局部变量 是根据需要定义的在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的BEGIN … END块。
1). 声明
1DECLARE 变量名 变量类型 [DEFAULT … ]
变量类型就是数据库字段类型:INT、BIGINT、CHAR、VARCHAR、DATE、TIME等。
2). 赋值
| 1 | SET 变量名 = 值 ; | |||
|---|---|---|---|---|
| 2 | SET 变量名 := 值 ; | |||
| 3 | SELECT 字段名 INTO | 变量名 FROM 表名 … ; | 变量名 FROM 表名 … ; |
演示示例:
| 1 | – 声明局部变量 - declare |
|---|---|
| 2 | – 赋值 |
| 3 | create procedure p2() |
| 4 | begin |
| 5 | declare stu_count int default 0; |
| 6 | select count(*) into stu_count from student; |
| 7 | select stu_count; |
| 8 | end; |
| 9 | |
| 10 | call p2(); |
4.2.4 if
1). 介绍
if 用于做条件判断,具体的语法结构为:
| 1 | IF 条件1 THEN | |
|---|---|---|
| 2 | ….. | |
| 3 | ELSEIF 条件2 THEN | – 可选 |
| 4 | ….. | |
| 5 | ELSE | – 可选 |
| 6 | ….. | |
| 7 | END IF; |

在if条件判断的结构中,ELSE IF 结构可以有多个,也可以没有。 ELSE结构可以有,也可以没有。
2). 案例
根据定义的分数score变量,判定当前分数对应的分数等级。
secxe>=85分,等级为优秀。
secxe>=60分 且secte<85分,等级为及格。
secte<60分,等级为不及格
| 1 | create procedure p3() |
|---|---|
| 2 | begin |
| 3 | declare score int default 58; |
| 4 | declare result varchar(10); |
| 5 | |
| 6 | if then |
| 7 | 优秀’; |
| 8 | elseif then |
| 9 | set 及格’; |
| 10 | else |
| 11 | set 不及格’; |
| 12 | end if; |
| 13 | select result; |
| 14 | end; |
| 15 | |
| 16call p3(); | 16call p3(); |
上述的需求我们虽然已经实现了,但是也存在一些问题,比如:score 分数我们是在存储过程中定义死的,而且最终计算出来的分数等级,我们也仅仅是最终查询展示出来而已。
那么我们能不能,把score分数动态的传递进来,计算出来的分数等级是否可以作为返回值返回呢?答案是肯定的,我们可以通过接下来所讲解的 参数 来解决上述的问题。
4.2.5 参数
1). 介绍
参数的类型,主要分为以下三种:IN、OUT、INOUT。 具体的含义如下:
| 类型 | 含义 | 备注 |
|---|---|---|
| IN | 该类参数作为输入,也就是需要调用时传入值 | 默认 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 | |
| INOUT | 既可以作为输入参数,也可以作为输出参数 |
用法:
| 1 | CREATE | PROCEDURE | 存储过程名称 ([ IN/OUT/INOUT | 参数名 | 参数类型 ]) |
|---|---|---|---|---|---|
| 2 | BEGIN | ||||
| 3 | – | SQL语句 | |||
| 4 | END ; | END ; |
2). 案例一
根据传入参数score,判定当前分数对应的分数等级,并返回。
secxe>=85分,,等级为优秀。
secte>=60分 且secte<85分,等级为及格。
score < 60分,等级为不及格。
1create procedure p4(in score int, out result varchar(10))
2 begin
3 if secxe>=85then
4 secresu1t:=’优秀’;
5 e1seif secxe>=60then
| 6 | set result ‘及格’; |
|---|---|
| 7 | else |
| 8 | set ‘不及格’; |
| 9 | end if; |
| 10 | end; |
| 11 | |
| 12 | – 定义用户变量 @result来接收返回的数据, 用户变量可以不用声明 |
| 13 | call p4(18, @result); |
| 14 | |
| 15 | select @result; |
3). 案例二
将传入的200分制的分数,进行换算,换算成百分制,然后返回。
| 1 | create procedure p5(inout score double) |
|---|---|
| 2 | begin |
| 3 | set score |
| 4 | end; |
| 5 | |
| 6 | |
| 7 | call p5(@score); |
| 8 | |
| 9 | select @score; |
4.2.6 case
1). 介绍
case结构及作用,和我们在基础篇中所讲解的流程控制函数很类似。有两种语法格式:
语法1:
| 1 2 |
– 含义: 当case_value的值为 when_value1时,执行statement_list1,当值为 when_value2时,执行statement_list2, 否则就执行 statement_listCASE case_value |
|---|---|
| 3 | WHEN when_value1 THEN statement_list1 |
| 4 | [ WHEN when_value2 THEN statement_list2] … |
| 5 | [ ELSE statement_list ] |
| 6 | END CASE; |
语法2:
| 1 | – 含义: 当条件search_condition1成立时,执行statement_list1,当条件search_condition2成立时,执行statement_list2, 否则就执行 statement_list | – 含义: 当条件search_condition1成立时,执行statement_list1,当条件search_condition2成立时,执行statement_list2, 否则就执行 statement_list | – 含义: 当条件search_condition1成立时,执行statement_list1,当条件search_condition2成立时,执行statement_list2, 否则就执行 statement_list |
|---|---|---|---|
| 2 | CASE | CASE | CASE |
| 3 | WHEN | search_condition1 THEN statement_lis | t1 |
| 4 | [WHEN | search_condition2 THEN statement_li | st2] … |
| 5 | [ELSE | statement_list] | |
| 6 | END CASE; | END CASE; | END CASE; |
2). 案例
根据传入的月份,判定月份所属的季节(要求采用case结构)。
1-3月份,为第一季度
4-6月份,为第二季度
7-9月份,为第三季度
10-12月份,为第四季度
1create procedure p6(in month int)
2begin
3 declare result varchar(10);
4 case
5 when month >=1and month <= 3 then
6 set result := ‘第一季度’;
7 when month>=4and month <= 6 then
8 secxesult:=’第二季度’;
9 when month>=7and month <= 9 then
10 setxesult:=’第三季度’;
| 11 | when month and then |
|---|---|
| 12 | ‘第四季度’; |
| 13 | else |
| 14 | set ‘非法参数’; |
| 15 | end case ; |
| 16 | |
| 17 | select concat(‘您输入的月份为: ‘,month, ‘, 所属的季度为: ‘,result); |
| 18 | end; |
| 19 | |
| 20 | call p6(16); |
注意:如果判定条件有多个,多个条件之间,可以使用 and 或 or 进行连接。
4.2.7 while
1). 介绍
while 循环是有条件的循环控制语句。满足条件后,再执行循环体中的SQL语句。具体语法为:
| 1 | – 先判定条件,如果条件为true,则执行逻辑,否则,不执行逻辑 |
|---|---|
| 2 | WHILE 条件 DO |
| 3 | SQL逻辑… |
| 4 | END WHILE; |
2). 案例
计算从1累加到n的值,n为传入的参数值。
| 1 | – A. 定义局部变量, 记录累加之后的值; |
|---|---|
| 2 | – B. 每循环一次, 就会对n进行减1 , 如果n减到0, 则退出循环 |
| 3 | |
| 4 | create procedure p7(in n int) |
| 5 | begin |
| 6 | declare total int default 0; |
| 7 | |
| 8 | while n>0 do |
| 9 | |
| 10 | |
| 11 | end while; |
| 12 | |
| 13 | select total; |
| 14 | end; |
| 15 | |
| 16 | call p7(100); |
4.2.8 repeat
1). 介绍
repeat是有条件的循环控制语句, 当满足until声明的条件的时候,则退出循环 。具体语法为:
| 1 | – 先执行一次逻辑,然后判定UNTIL条件是否满足,如果满足,则退出。如果不满足,则继续下一次循环 |
|---|---|
| 2 | REPEAT |
| 3 | SQL逻辑… |
| 4 | UNTIL 条件 |
| 5 | END REPEAT; |
2). 案例
计算从1累加到n的值,n为传入的参数值。(使用repeat实现)
| 1 | – A. 定义局部变量, 记录累加之后的值; |
|---|---|
| 2 | – B. 每循环一次, 就会对n进行-1 , 如果n减到0, 则退出循环 |
| 3 | create procedure p8(in n int) |
| 4 | begin |
| 5 | declare total int default 0; |
| 6 | |
| 7 | repeat |
| 8 | |
| 9 | |
| 10 | until |
| 11 | end repeat; |
| 12 | |
| 13 | select total; |
| 14 | end; |
| 15 | |
| 16 | call p8(10); |
| 17 | call p8(100); |
4.2.9 loop
1). 介绍
LOOP 实现简单的循环,如果不在SQL逻辑中增加退出循环的条件,可以用其来实现简单的死循环。LOOP可以配合一下两个语句使用:
LEAVE :配合循环使用,退出循环。
ITERATE:必须用在循环中,作用是跳过当前循环剩下的语句,直接进入下一次循环。
| 1 | [begin_label:] LOOP |
|---|---|
| 2 | SQL逻辑… |
| 3 | END LOOP [end_label]; |
| 1 | LEAVE label; – 退出指定标记的循环体 |
2ITERATE label; – 直接进入下一次循环
上述语法中出现的 begin_label,end_label,label 指的都是我们所自定义的标记。
2). 案例一
计算从1累加到n的值,n为传入的参数值。
| 1 | – A. 定义局部变量, 记录累加之后的值; |
|---|---|
| 2 | – B. 每循环一次, 就会对n进行-1 , 如果n减到0, 则退出循环 —-> leave xx |
| 3 | |
| 4 | create procedure p9(in n int) |
| 5 | begin |
| 6 | declare total int default 0; |
| 7 | |
| 8 | sum:loop |
| 9 | if then |
| 10 | leave sum; |
| 11 | end if; |
| 12 | |
| 13 | set |
| 14 | ; |
| 15 | end loop sum; |
| 16 | |
| 17 | select total; |
| 18 | end; |
| 19 | |
| 20 | call p9(100); |
3). 案例二
计算从1到n之间的偶数累加的值,n为传入的参数值。
| 1 | – A. 定义局部变量, 记录累加之后的值; |
|---|---|
| 2 | – B. 每循环一次, 就会对n进行-1 , 如果n减到0, 则退出循环 —-> leave xx |
| 3 | – C. 如果当次累加的数据是奇数, 则直接进入下一次循环. ——–> iterate xx |
| 4 | |
| 5 | create procedure p10(in n int) |
| 6 | begin |
| 7 | declare total int default 0; |
| 8 | |
| 9 | sum:loop |
| 10 | if then |
| 11 | leave sum; |
| 12 | end if; |
| 13 | |
| 14 | if then |
| 15 | set n |
| 16 | iterate sum; |
| 17 | end if; |
| 18 | |
| 19 | set |
| 20 | |
| 21 | end loop sum; |
| 22 | |
| 23 | select total; |
| 24 | end; |
| 25 | |
| 26 | call p10(100); |
| 27 |
4.2.10 游标
1). 介绍
游标(CURSOR)是用来存储查询结果集的数据类型 , 在存储过程和函数中可以使用游标对结果集进行循环的处理。游标的使用包括游标的声明、OPEN、FETCH 和 CLOSE,其语法分别如下。
A. 声明游标
| 1 | DECLARE | 游标名称 | CURSOR | FOR | 查询语句 ; |
|---|
B. 打开游标
| 1OPEN | 游标名称 ; |
|---|
C. 获取游标记录
| 1 | FETCH | 游标名称 | INTO | 变量 [, 变量 ] ; |
|---|
D. 关闭游标
| 1CLOSE | 游标名称 ; |
|---|
2). 案例
根据传入的参数uage,来查询用户表$t b \underline u s e r$中,所有的用户年龄小于等于uage的用户姓名(name)和专业(profession),并将用户的姓名和专业插入到所创建的一张新表(id,name,profession)中。
| 1 | – 逻辑: |
|---|---|
| 2 | – A. 声明游标, 存储查询结果集 |
| 3– B. 准备: 创建表结构 | 3– B. 准备: 创建表结构 |
| 4 | – C. 开启游标 |
| 5 | – D. 获取游标中的记录 |
| 6 | – E. 插入数据到新表中 |
| 7 | – F. 关闭游标 | |
|---|---|---|
| 8 | ||
| 9 | create procedure p11(in uage int) | |
| 10 | begin | |
| 11 | declare uname varchar(100); | |
| 12 | declare upro varchar(100); | |
| 13 | declare u_cursor cursor for select na | me,profession from tb_user where age <= |
| uage; | uage; | |
| 14 | ||
| 15 16 |
drop table if exists tb_user_pro; create table if not exists | |
| 17 | id int primary key auto_increment | , |
| 18 | name varchar(100), | |
| 19 | profession varchar(100) | |
| 20 | ); | |
| 21 | ||
| 22 | ||
| 23 | while true do | |
| 24 | fetch u_cursor into uname,upro; | |
| 25 | insert into values (nu | ll, uname, upro); |
| 26 | end while; | |
| 27 | close | |
| 28 | ||
| 29 | end; | |
| 30 | ||
| 31 | ||
| 32 | call p11(30); |
上述的存储过程,最终我们在调用的过程中,会报错,之所以报错是因为上面的while循环中,并没有退出条件。当游标的数据集获取完毕之后,再次获取数据,就会报错,从而终止了程序的执行。

但是此时,$t b _ u s e r \underline p r c$表结构及其数据都已经插入成功了,我们可以直接刷新表结构,检查表结构中的数据。
| MySQL-@192.168.200.202 6information_schema | WHERE | WHERE | WHERE | WHERE | E-ORDER BY |
|---|---|---|---|---|---|
| itcast | id | name | profession 0 | profession 0 | |
| tables 6 | 1 | 1 | 吕布 | 软件工程 | 软件工程 |
| coursestudent | 2 | 2 | 曹操 | 通讯工程 | 通讯工程 |
| student_course | 3 | 3 | 赵云 | 英语 | 英语 |
| tb_sku | 4 | 4 | 花木兰 | 软件工程 | 软件工程 |
| > tb_user | |||||
| tb_user_pro | 5 | 5 | 大乔 | 舞蹈 | 舞蹈 |
| > views 9tines | 6 | 6 | 露娜 | 应用数学 | 应用数学 |
| rou11Pp1 0 | 7 | 7 | 程咬金 | 化工 | 化工 |
| Pp2 0 | 8 | 8 | 机械工程及其自动化 | 机械工程及其自动化 | |
| P p3 0 | 8 | 8 | 白起 | 机械工程及其自动化 | 机械工程及其自动化 |
| P p4 (int, OUT varchar) | 9 | 9 | 韩信 | 无机非金属材料工程 | 无机非金属材料工程 |
| P p5 (INOUT double) | 10 | 10 | 荆轲 | 会计 | 会计 |
| P p6 (int) | 软件工程 | 软件工程 | |||
| P p7 (int) | 11 | 11 | 貂蝉 | 软件工程 | 软件工程 |
| P p8 (int) | 12 | 12 | 妲己 | 软件工程 | 软件工程 |
| P p9 (int)P p10 (int) | 13 | 13 | 芈月 | 工业经济 | 工业经济 |
| P p11 (int) | 14 | 14 | 赢政 | 化工 | 化工 |
| itheimamysql | 15 | 15 | 狄仁杰 | 国际贸易 | 国际贸易 |
上述的功能,虽然我们实现了,但是逻辑并不完善,而且程序执行完毕,获取不到数据,数据库还报错。接下来,我们就需要来完成这个存储过程,并且解决这个问题。
要想解决这个问题,就需要通过MySQL中提供的 条件处理程序 Handler 来解决。
4.2.11 条件处理程序
1).介绍
条件处理程序(Handler)可以用来定义在流程控制结构执行过程中遇到问题时相应的处理步骤。具体语法为:
| 1DECLARE handl | er_action HANDLER F | OR condition_valu | e [, condition_value |
|---|---|---|---|
| … statement2 | ; | ||
| 的取值: | 的取值: | ||
| 3handler_action | |||
| 4 CONTINUE: | 继续执行当前程序 | 继续执行当前程序 | |
| 5 EXIT: 终止执 | 行当前程序 | 行当前程序 | |
| 6 | |||
| 7condition_value | 的取值: | 的取值: | 的取值: |
| 8 SQLSTATE s | qlstate_value: 状态码,如 02000 | qlstate_value: 状态码,如 02000 | qlstate_value: 状态码,如 02000 |
| 9 | |||
| 10 SQLWARNING: | 所有以01开头的SQLSTATE | 代码的简写 | |
| 11 NOT FOUND: | 所有以02开头的SQLSTATE代码的简写 | 所有以02开头的SQLSTATE代码的简写 | 所有以02开头的SQLSTATE代码的简写 |
| 12 SQLEXCEPTIO | N: 所有没有被SQLWARNING 或 NOT FOUND捕获的SQLSTATE代码的简写 | N: 所有没有被SQLWARNING 或 NOT FOUND捕获的SQLSTATE代码的简写 | N: 所有没有被SQLWARNING 或 NOT FOUND捕获的SQLSTATE代码的简写 |
2). 案例
我们继续来完成在上一小节提出的这个需求,并解决其中的问题。
根据传入的参数uage,来查询用户表tb_user中,所有的用户年龄小于等于uage的用户姓名(name)和专业(profession),并将用户的姓名和专业插入到所创建的一张新表(id,name,profession)中。
A. 通过SQLSTATE指定具体的状态码
| 1 | – 逻辑: |
|---|---|
| 2 | – A. 声明游标, 存储查询结果集 |
| 3– B. 准备: 创建表结构 | 3– B. 准备: 创建表结构 |
| 4 | – C. 开启游标 |
| 5 | – D. 获取游标中的记录 |
| 6 | – E. 插入数据到新表中 |
| 7 | – F. 关闭游标 |
| 8 | |
| 9 | create procedure p11(in uage int) |
| 10 | begin |
| 11 | declare uname varchar(100); |
| 12 | declare upro varchar(100); |
| 13 | declare u_cursor cursor for select name,profession from tb_user where age <= |
| uage; | uage; |
| 14 | – 声明条件处理程序 : 当SQL语句执行抛出的状态码为02000时,将关闭游标u_cursor,并退出 |
| 15 | declare exit handler for SQLSTATE ‘02000’ close u_cursor; |
| 16 | |
| 17 | drop table if exists tb_user_pro; |
| 18 | create table if not exists tb_user_pro( |
| 19 | id int primary key auto_increment, |
| 20 | name varchar(100), |
| 21 | profession varchar(100) |
| 22 | ); |
| 23 | |
| 24 | open u_cursor; |
| 25 | while true do |
| 26 | fetch u_cursor into uname,upro; |
| 27 | insert into values (null, uname, upro); |
| 28 | end while; |
| 29 | close u_cursor; |
| 30 | |
| 31 | end; |
| 32 | |
| 33 | call p11(30); |
B. 通过SQLSTATE的代码简写方式 NOT FOUND
02 开头的状态码,代码简写为 NOT FOUND
| 1 | create procedure p12(in uage int) |
|---|---|
| 2 | begin |
| 3 | declare uname varchar(100); |
| 4 | declare upro varchar(100); |
| 5 | declare u_cursor cursor for select name,profession from tb_user where age <= |
| uage; | |
| 6 | – 声明条件处理程序 : 当SQL语句执行抛出的状态码为02开头时,将关闭游标u_cursor,并退出 |
| 7 | declare exit handler for not found close |
| 8 | |
| 9 | drop table if exists tb_user_pro; |
| 10 | create table if not exists tb_user_pro( |
| 11 | id int primary key auto_increment, |
| 12 | name varchar(100), |
| 13 | profession varchar(100) |
| 14 | ); |
| 15 | |
| 16 | open u_cursor; |
| 17 | while true do |
| 18 | fetch u_cursor into uname,upro; |
| 19 | insert into tb_user_pro values (null, uname, upro); |
| 20 | end while; |
| 21 | close u_cursor; |
| 22 | |
| 23 | end; |
| 24 | |
| 25 | |
| 26 | call p12(30); |
具体的错误状态码,可以参考官方文档:
https://dev.mysql.com/doc/refman/8.0/en/declare-handler.html
https://dev.mysql.com/doc/mysql-errors/8.0/en/server-error-reference.html
4.3 存储函数
1). 介绍
存储函数是有返回值的存储过程,存储函数的参数只能是IN类型的。具体语法如下:
| 1 | CREATE | FUNCTIO | N 存储函数名称 ([ 参数列表 ]) | |
|---|---|---|---|---|
| 2 | RETURNS | type | [characteristic …] | |
| 3 | BEGIN | BEGIN | ||
| 4 | – SQL语句 | – SQL语句 | ||
| 5 | RETURN …; | RETURN …; | RETURN …; | |
| 6END ; | 6END ; | 6END ; | 6END ; | 6END ; |

characteristic说明:
DETERMINISTIC:相同的输入参数总是产生相同的结果
NO SQL :不包含 SQL 语句。
READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句。
2). 案例
计算从1累加到n的值,n为传入的参数值。
| 1 | create function fun1(n int) |
|---|---|
| 2 | returns int deterministic |
| 3 | begin |
| 4 | declare total int default 0; |
| 5 | |
| 6 | while |
| 7 | set total |
| 8 | |
| 9 | end while; |
| 10 | |
| 11 | return total; |
| 12 | end; |
| 13 | |
| 14 | select fun1(50); |
在mysql8.0版本中binlog默认是开启的,一旦开启了,mysql就要求在定义存储过程时,需要指定characteristic特性,否则就会报如下错误:
4.4 触发器
4.4.1 介绍
触发器是与表有关的数据库对象,指在insert/update/delete之前(BEFORE)或之后(AFTER),触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。
使用别名OLD和NEW来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
| 触发器类型 | NEW 和 OLD |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据 |
| UPDATE 型触发器 | OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的数据 |
4.4.2 语法
1). 创建
| 1 | CREATE TRIGGER trigger_name |
|---|---|
| 2 | BEFORE/AFTER INSERT/UPDATE/DELETE |
| 3 | ON tbl_name FOR EACH ROW – 行级触发器 |
| 4 | BEGIN |
| 5 | trigger_stmt ; |
| 6 | END; |
2). 查看

| 1 | SHOW | TRIGGERS ; |
|---|
3). 删除
| DROP | TRIGGER | [schema_name.]trigger_name ; – 如果没有指定 schema_name,默认为 |
|---|---|---|
| 据库 。 | 据库 。 |
4.4.3 案例
通过触发器记录 tb_user 表的数据变更日志,将变更日志插入到日志表user_logs中, 包含增加,修改 , 删除 ;
表结构准备:
| 1 | – 准备工作 : 日志表 user_logs |
|---|---|
| 2 | create table user_logs( |
| 3 | id int(11) not null auto_increment, |
| 4 | operation varchar(20) not null comment ‘操作类型, insert/update/delete’, |
| 5 | operate_time datetime not null comment ‘操作时间’, |
| 6 | operate_id int(11) not null comment ‘操作的ID’, |
| 7 | operate_params varchar(500) comment ‘操作参数’, |
| 8 | primary key(id) |
| 9 | )engine=innodb default charset=utf8; |
A. 插入数据触发器
1create trigger tb_user_insert_trigger
| 1 | create trigger tb_user_insert_trigger |
|---|---|
| 2 | after insert on tb_user for each row |
| 3 | begin |
| 4 | insert into user_logs(id, operation, operate_time, operate_id, operate_params)VALUES |
| 5 | (null, ‘insert’, now(), new.id, concat(‘插入的数据内容为: id=’,new.id,’,name=’,new.name, ‘, phone=’, NEW.phone, ‘, email=’, NEW.email, ‘, |
| 6 | profession=’, NEW.profession));end; |
测试:
| 1– 查看 | 1– 查看 |
|---|---|
| 2 | show triggers ; |
| 3 | |
| 4 | – 插入数据到tb_user |
| 5 | insert into tb_user(id |
| createtime) VALUES (26 | |
| 程’,23, ; |
测试完毕之后,检查日志表中的数据是否可以正常插入,以及插入数据的正确性。
B. 修改数据触发器
| 1 | create trigger tb_user_update_trigger |
|---|---|
| 2 | after update on tb_user for each row |
| 3 | begin |
| 4 | insert into user_logs(id, operation, operate_time, operate_id, operate_params |
| VALUES | |
| 5 6 |
(null, ‘update’, now(), new.id, concat(‘更新之前的数据: id=’,old.id,’,name=’,old.name, ‘, ph , |
| old.phone, ‘, , old.email, ‘, profession=’, old.profession, | |
| 7 | ‘ |
| 8 | NEW.phone, ‘, NEW.email, ‘, professi , NEW.profession));end; |
测试:

测试完毕之后,检查日志表中的数据是否可以正常插入,以及插入数据的正确性。
C. 删除数据触发器
| 1 | create trigger tb_user_delete_trigger |
|---|---|
| 2 | after delete on tb_user for each row |
| 3 | begin |
| 4 | insert into user_logs(id, operation, operate_time, operate_id, operate_params)VALUES |
| 5 | (null, ‘delete’, now(), old.id, |
| 6 | concat(‘删除之前的数据: id=’,old.id,’,name=’,old.name, ‘, pho , |
| 7 | old.phone, ‘, email=’, old.email, ‘, professi old.profession));end; |
测试:

测试完毕之后,检查日志表中的数据是否可以正常插入,以及插入数据的正确性。
5. 锁
5.1 概述
锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CPU、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
MySQL中的锁,按照锁的粒度分,分为以下三类:
全局锁:锁定数据库中的所有表。
表级锁:每次操作锁住整张表。
行级锁:每次操作锁住对应的行数据。
5.2 全局锁
5.2.1 介绍
全局锁就是对整个数据库实例加锁,加锁后整个实例就处于只读状态,后续的DML的写语句,DDL语句,已经更新操作的事务提交语句都将被阻塞。
其典型的使用场景是做全库的逻辑备份,对所有的表进行锁定,从而获取一致性视图,保证数据的完整性。
为什么全库逻辑备份,就需要加全就锁呢?
A. 我们一起先来分析一下不加全局锁,可能存在的问题。
假设在数据库中存在这样三张表: $t b _ s t o c k$ 库存表,$t b \underline { } \circ r d e r$ 订单表,tb_orderlog 订单日志表。


在进行数据备份时,先备份了tb_stock库存表。
然后接下来,在业务系统中,执行了下单操作,扣减库存,生成订单(更新tb_stock表,插入tb_order表)。
然后再执行备份 $t b \underline { } \circ r d e r$表的逻辑。
业务中执行插入订单日志操作
最后,又备份了tb_orderlog表
此时备份出来的数据,是存在问题的。因为备份出来的数据,$t b _ s t o$ck表与tb_order表的数据不一致(有最新操作的订单信息,但是库存数没减)。
那如何来规避这种问题呢? 此时就可以借助于MySQL的全局锁来解决。
B. 再来分析一下加了全局锁后的情况

对数据库进行进行逻辑备份之前,先对整个数据库加上全局锁,一旦加了全局锁之后,其他的DDL、DML全部都处于阻塞状态,但是可以执行DQL语句,也就是处于只读状态,而数据备份就是查询操作。那么数据在进行逻辑备份的过程中,数据库中的数据就是不会发生变化的,这样就保证了数据的一致性和完整性。
5.2.2 语法
1). 加全局锁
| 1 | flush tab | les with r | ead lock ; |
|---|
2). 数据备份
1mysqldump -uroot –p1234 itcast > itcast.sql
数据备份的相关指令, 在后面MySQL管理章节, 还会详细讲解.
3). 释放锁

| 1unlock tables ; |
|---|
5.2.3 特点
数据库中加全局锁,是一个比较重的操作,存在以下问题:
如果在主库上备份,那么在备份期间都不能执行更新,业务基本上就得停摆。
如果在从库上备份,那么在备份期间从库不能执行主库同步过来的二进制日志(binlog),会导致主从延迟。
在InnoDB引擎中,我们可以在备份时加上参数 –single-transaction 参数来完成不加锁的一致性数据备份。
1mysqldump –single-transaction -uroot –p123456 itcast > itcast.sql
5.3 表级锁
5.3.1 介绍
表级锁,每次操作锁住整张表。锁定粒度大,发生锁冲突的概率最高,并发度最低。应用在MyISAM、InnoDB、BDB等存储引擎中。
对于表级锁,主要分为以下三类:
表锁
元数据锁(meta data lock,MDL)
意向锁
5.3.2 表锁
对于表锁,分为两类:
表共享读锁(read lock)
表独占写锁(write lock)
语法:
加锁:lock tables 表名… read/write。
释放锁:unlock tables / 客户端断开连接 。
特点:
A. 读锁

左侧为客户端一,对指定表加了读锁,不会影响右侧客户端二的读,但是会阻塞右侧客户端的写。
测试:



左侧为客户端一,对指定表加了写锁,会阻塞右侧客户端的读和写
测试:

结论: 读锁不会阻塞其他客户端的读,但是会阻塞写。写锁既会阻塞其他客户端的读,又会阻塞其他客户端的写。
5.3.3 元数据锁
meta data lock , 元数据锁,简写MDL。
MDL加锁过程是系统自动控制,无需显式使用,在访问一张表的时候会自动加上。MDL锁主要作用是维护表元数据的数据一致性,在表上有活动事务的时候,不可以对元数据进行写入操作。为了避免DML与DDL冲突,保证读写的正确性。
这里的元数据,大家可以简单理解为就是一张表的表结构。 也就是说,某一张表涉及到未提交的事务时,是不能够修改这张表的表结构的。
在MySQL5.5中引入了MDL,当对一张表进行增删改查的时候,加MDL读锁(共享);当对表结构进行变更操作的时候,加MDL写锁(排他)。
常见的SQL操作时,所添加的元数据锁:
| 对应SQL | 锁类型 | 说明 |
|---|---|---|
| lock tables xxx read /write | SHARED_READ_ONLY /SHARED_NO_READ_WRITE | |
| select 、select …lock in share mode | SHARED_READ | 与SHARED_READ、SHARED_WRITE兼容,与EXCLUSIVE互斥 |
| insert 、update、delete、select … forupdate | SHARED_WRITE | 与SHARED_READ、SHARED_WRITE兼容,与EXCLUSIVE互斥 |
| alter table … | EXCLUSIVE | 与其他的MDL都互斥 |
演示:
当执行SELECT、INSERT、UPDATE、DELETE等语句时,添加的是元数据共享锁(SHARED_READ /SHARED_WRITE),之间是兼容的。

当执行SELECT语句时,添加的是元数据共享锁(SHARED_READ),会阻塞元数据排他锁(EXCLUSIVE),之间是互斥的。

我们可以通过下面的SQL,来查看数据库中的元数据锁的情况:
1 select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
我们在操作过程中,可以通过上述的sQL语句,来查看元数据锁的加锁情况。
| I object_type | objec | t_schema object | _name I lock type | lock duration |
| – | – | – | – |
| I TABLE db01 | score | SHARED READ | TRANSACTION |
| I TABLE perfor | mance_schema metada | ta locks SHARED READ | TRANSACTION |
| 2 rows in set (0.00 sec) | 2 rows in set (0.00 sec) | 2 rows in set (0.00 sec) | 2 rows in set (0.00 sec) |
5.3.4 意向锁
1).介绍
为了避免DML在执行时,加的行锁与表锁的冲突,在InnoDB中引入了意向锁,使得表锁不用检查每行数据是否加锁,使用意向锁来减少表锁的检查。
假如没有意向锁,客户端一对表加了行锁后,客户端二如何给表加表锁呢,来通过示意图简单分析一下:
首先客户端一,开启一个事务,然后执行DML操作,在执行DML语句时,会对涉及到的行加行锁。
| id | name | age | job | salary | entrydate | managerid | dept_id | |
|---|---|---|---|---|---|---|---|---|
| begin; | 1金庸 | 6 | 6总裁 | 20000 | 2000-01-01 | (Nu11) | 5 | |
| begin; | 2张无忌 | 2 | 0项目经理 | 12500 | 2005-12-05 | 1 | 1 | |
| update… | 5 | 3杨逍 | 3 | 3开发 | 8400 | 2000-11-03 | 1 | |
| update… | 4韦一笑 | 4 | 8开发 | 11000 | 2002-02-05 | 2 | 1 | |
| update… | 5常遇春 | 4 | 3开发 | 10500 | 2004-09-07 | 3 | ||
| update… | 6小昭 | 1 | 9程序员鼓励师 | 6600 | 2004-10-12 | 2 | 1 | |
| update… | 7灭绝 | 6 | 0财务总监 | 8500 | 2002-09-12 | |||
| update… | 8周芷若 | 1 | 9会计 | 48000 | 2006-06-02 | 7 | 3 | |
| update… | 9丁敏君 | 2 | 3出纳 | 5250 | 2009-05-13 | 7 | ||
| update… | 10赵敏 | 2 | 0市场部总监 | 12500 | 2004-10-12 | 1 | 2 | |
| update… | 11鹿杖客 | 5 | 6职员 | 3750 | 2006-10-03 | 10 | 2 | |
| update… | 12鹤笔翁 | 1 | 9职员 | 3750 | 2007-05-09 | 10 | 2 | |
| 13方东白 | 1 | 9职员 | 5500 | 2009-02-12 | 10 | 2 | ||
| 14张三丰 | 8 | 8 销售总监 | 14000 | 2004-10-12 | 1 | 4 | ||
| 15俞莲舟 | 3 | 8销售 | 4600 | 2004-10-12 | 14 | |||
| 16宋远桥 | 4 | 0销售 | 4600 | 2004-10-12 | 14 | 4 |
线程A
当客户端二,想对这张表加表锁时,会检查当前表是否有对应的行锁,如果没有,则添加表锁,此时就会从第一行数据,检查到最后一行数据,效率较低。
| 1d | nam | e age | Job | salar | y entry | date managerid | dept_id | lock tables xoxx read/write; | |
|---|---|---|---|---|---|---|---|---|---|
| 1金南 | 6 | 6总裁 | 200 | 00 2000- | 01-01 (NU11 | ) | |||
| begin; | 2张无 | 忌 2 | 0项目经 | 理 125 | 00 2005- | 12-05 | |||
| update | 图 | 3杨道 | 3 | 3开发 | 84 | 00 2000- | 11-03 | ||
| .. | 4韦一 | 笑 4 | 0开发 | 110 | 00 2002- | 02-05 2 | |||
| 5 常遇 | 春 4 | 3开发 | 105 | 00 2004- | 09-07 | ||||
| 6小明 | 1 | 9程序员 | 鼓励师 66 | 00 2004- | 10-12 2 | ||||
| 7灭 | 绝 6 | 0财务总 | 监 85 | 00 2002- | 09-12 | ||||
| 8周芷 | 若 1 | 9会计 | 400 | 00 2006- | 06-02 7 | ||||
| 9丁敏 | 君 2 | 3出纳 | 52 | 50 2009- | 05-13 7 | ||||
| 1 | 0赵敏 | 2 | 0市场部 | 总监 125 | 00 2004- | 10-12 | |||
| 1 | 1鹿杖 | 客 5 | 6职员 | 37 | 50 2006- | 10-03 10 | |||
| 1 | 2鹤笔 | 翁 1 | 9职员 | 37 | 50 2007- | 05-09 10 | |||
| 1 | 3方东 | 白 1 | 9职员 | 55 | 00 2009- | 02-12 10 | |||
| 1 | 4张 | 三丰 8 | 8销售总 | 监 140 | 00 2004- | 10-12 | |||
| 1 | 5俞莲 | 舟 3 | 8销售 | 46 | 00 2004- | 10-12 14 | |||
| 1 | 6宋远 | 桥 40销售 | 桥 40销售 | 46 | 00 2004- | 10-12 14 | 检查 |
线程A
有了意向锁之后:
客户端一,在执行DML操作时,会对涉及的行加行锁,同时也会对该表加上意向锁。
| id | name | age | job | salary | entrydate | managerid | dept_id | |
|---|---|---|---|---|---|---|---|---|
| begin; | 1 | 金庸 | 6 | 6总裁 | 20000 | 2000-01-01 | (Nu11) | 5 |
| begin; | 2 | 张无忌 | 2 | 0项目经理 | 12500 | 2005-12-05 | 1 | 1 |
| update… | 〒 3 | 杨逍 | 3 | 3开发 | 8400 | 2000-11-03 | 2 | 1 |
| update… | 4 | 韦一笑 | 4 | 8开发 | 11000 | 2002-02-05 | 2 | 1 |
| update… | 5 | 常遇春 | 4 | 3开发 | 10500 | 2004-09-07 | 3 | 1 |
| update… | 6 | 小昭 | 1 | 9程序员鼓励师 | 6600 | 2004-10-12 | 2 | 1 |
| update… | 7 | 灭绝 | 6 | 0财务总监 | 8500 | 2002-09-12 | 1 | 3 |
| update… | 8 | 周芷若 | 1 | 9会计 | 48000 | 2006-06-02 | 7 | 3 |
| update… | 9 | 丁敏君 | 2 | 3出纳 | 5250 | 2009-05-13 | 7 | 3 |
| update… | 意向锁 10 | 赵敏 | 2 | 0市场部总监 | 12500 | 2004-10-12 | 1 | 2 |
| update… | 11 | 鹿杖客 | 5 | 6职员 | 3750 | 2006-10-03 | 10 | 2 |
| 12 | 鹤笔翁 | 19职员 | 19职员 | 3750 | 2007-05-09 | 10 | 2 | |
| 13 | 方东白 | 19职员 | 19职员 | 5500 | 2009-02-12 | 10 | 2 | |
| 14 | 张三丰 | 8 | 8销售总监 | 14000 | 2004-10-12 | 1 | 4 | |
| 15 | 俞莲舟 | 38销售 | 38销售 | 4600 | 2004-10-12 | 14 | 4 | |
| 16 | 宋远桥 | 40销售 | 40销售 | 4600 | 2004-10-12 | 14 | 4 |
线程A
而其他客户端,在对这张表加表锁的时候,会根据该表上所加的意向锁来判定是否可以成功加表锁,而不用逐行判断行锁情况了。

| id | nam | e age | Job | salary | entrydate | manageriddept_id | lock tables xx | |
|---|---|---|---|---|---|---|---|---|
| 1 金 | 庸 6 | 6总裁 | 20000 | 2000-01-01 | (Nu11) | read/urite; | ||
| begin: | 2张 | 无总 2 | 0项目经理 | 12500 | 2005-12-05 | 1 | ||
| update | 1 | 3杨道 | 3 | 3开发 | 8400 | 2000-11-03 | ||
| 4韦 | 一笑 4 | 8开发 | 11000 | 2002-02-05 | ||||
| 5常遇 | 春 43开发 | 春 43开发 | 10500 | 2004-09-07 | ||||
| 6小明 | 1 | 9程序员鼓励师 | 6600 | 2004-10-12 | ||||
| 7天绝 | 6 | 0财务总监 | 8500 | 2002-09-12 | 1 | |||
| 8周 | 芷若 1 | 9会计 | 48000 | 2006-06-02 | ||||
| 9丁敏 | 君 2 | 3出纳 | 5250 | 2009-05-13 | 7 | |||
| 意向锁 1 | 0赵敏 | 2 | 0市场部总监 | 12500 | 2004-10-12 | 1 | ||
| 1 | 1鹿杖 | 客 5 | 6职员 | 3750 | 2006-10-03 | 10 | ||
| 1 | 2鹤笔 | 翁 1 | 9职员 | 3750 | 2007-05-09 | 10 2 | ||
| 1 | 3方 | 东白 1 | 9职员 | 5500 | 2009-02-12 | 10 2 | ||
| 1 | 4张二 | 丰 0 | 0销售总监 | 14000 | 2004-10-12 | 1 | ||
| 1 | 5俞 | 莲舟 38销售 | 莲舟 38销售 | 4600 | 2004-10-12 | 14 | ||
| 1 | 6宋远 | 桥 40销售 | 桥 40销售 | 4600 | 2004-10-12 | 14 | ||
| 线程A | 线程A | 线程B | 线程B | 线程B | 线程B | 线程B |
2).分类
意向共享锁(IS): 由语句select … lock in share mode添加 。 与 表锁共享锁(read)兼容,与表锁排他锁(write)互斥。
意向排他锁(IX): 由insert、update、delete、select…for update添加 。与表锁共享锁(read)及排他锁(write)都互斥,意向锁之间不会互斥。
一旦事务提交了,意向共享锁、意向排他锁,都会自动释放。
可以通过以下SQL,查看意向锁及行锁的加锁情况:
1select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
演示:
A. 意向共享锁与表读锁是兼容的


B. 意向排他锁与表读锁、写锁都是互斥的


5.4 行级锁
5.4.1 介绍
行级锁,每次操作锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB存储引擎中。
InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。对于行级锁,主要分为以下三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。

- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。

- 临键锁(Next-KeyLock):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。在RR隔离级别下支持。

5.4.2 行锁
1).介绍
InnoDB实现了以下两种类型的行锁:
共享锁(s):允许一个事务去读一行,阻止其他事务获得相同数据集的排它锁。
排他锁(x):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。
两种行锁的兼容情况如下:
| 请求锁类型当前锁类型 | S(共享锁) | X(排他锁) |
|---|---|---|
| S(共享锁) | 兼容 | 冲突 |
| X(排他锁) | 冲突 | 冲突 |
常见的SQL语句,在执行时,所加的行锁如下:
| SQL | 行锁类型 | 说明 |
|---|---|---|
| INSERT … | 排他锁 | 自动加锁 |
| UPDATE … | 排他锁 | 自动加锁 |
| DELETE … | 排他锁 | 自动加锁 |
| SELECT(正常) | 不加任何锁 | |
| SELECT … LOCK IN SHAREMODE | 共享锁 | 需要手动在SELECT之后加LOCK IN SHAREMODE |
| SELECT … FOR UPDATE | 排他锁 | 需要手动在SELECT之后加FOR UPDATE |
2). 演示
默认情况下,InnoDB在 REPEATABLE READ事务隔离级别运行,InnoDB使用 next-key 锁进行搜索和索引扫描,以防止幻读。
针对唯一索引进行检索时,对已存在的记录进行等值匹配时,将会自动优化为行锁。
InnoDB的行锁是针对于索引加的锁,不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,此时 就会升级为表锁。
可以通过以下SQL,查看意向锁及行锁的加锁情况:
1select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
示例演示
数据准备:
| 1 | CREATE | TABLE ‘stu | ‘( | |
|---|---|---|---|---|
| 2 | “id’ | int NOT NU | LL PRIMARY K | EY AUTO_INCRE |
| 3 | ‘name | ‘ varchar( | 255) DEFAULT | NULL, |
| 4 | ‘age’ int NOT NULL | ‘age’ int NOT NULL | ‘age’ int NOT NULL | |
| 5 | )ENGIN | E = InnoDB | CHARACTER S | ET = utf8mb4; |
| 6 | ||||
| 7 | INSERT | INTO ‘stu’ | VALUES (1,’ | tom”,1); |
| 8 | INSERT | INTO ‘stu | ‘VALUES (3,’ | cat’,3); |
| 9 | INSERT | INTO ‘stu | ‘VALUES (8,’ | rose”,8); |
| 10 | INSERT | INTO ‘stu’ | VALUES (11, | ‘jetty’,11); |
| 11 | INSERT | INTO ‘stu | “VALUES (19, | ‘1ily’,19); |
| 12 | INSERT | INTO ‘stu’ | VALUES (25, | ‘luci’, 25); |
演示行锁的时候,我们就通过上面这张表来演示一下。
A.普通的select语句,执行时,不会加锁。
| 数 | 数 | 数 | 数 | 数 | 数 | 数 | 数 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 192,168,200.202 | Bcsted (3.00 cea) | Bcsted (3.00 cea) | 数 | 数 | 数 | 数 | 数 | 数 | 数 | 数 | |||||||
| syoql> poginiquasy ck, 0 sane co001ot | syoql> poginiquasy ck, 0 sane co001ot | Bcsted (3.00 cea) | Bcsted (3.00 cea) | ||||||||||||||
| syoql> poginiquasy ck, 0 sane co001ot | syoql> poginiquasy ck, 0 sane co001ot | Bcsted (3.00 cea) | Bcsted (3.00 cea) | ||||||||||||||
| $1 4 1 0 0 0 0$ | $1 4 1 0 0 0 0$ | Bcsted (3.00 cea) | Bcsted (3.00 cea) | ||||||||||||||
| $1 1 0 0 0 0 1 0$ | $1 1 0 0 0 0 1 0$ | Bcsted (3.00 cea) | Bcsted (3.00 cea) | ||||||||||||||
| $-$ $( 0 . 0 ) = e ( F e )$ayog | $-$ $( 0 . 0 ) = e ( F e )$ayog | Bcsted (3.00 cea) | Bcsted (3.00 cea) | ||||||||||||||
| $-$ $( 0 . 0 ) = e ( F e )$ayog | $-$ $( 0 . 0 ) = e ( F e )$ayog | Bcsted (3.00 cea) | Bcsted (3.00 cea) | ||||||||||||||
B. select…lock in share mode,加共享锁,共享锁与共享锁之间兼容。


共享锁与排他锁之间互斥。


客户端一获取的是id为1这行的共享锁,客户端二是可以获取id为3这行的排它锁的,因为不是同一行数据。 而如果客户端二想获取id为1这行的排他锁,会处于阻塞状态,以为共享锁与排他锁之间互斥。
C. 排它锁与排他锁之间互斥

当客户端一,执行update语句,会为id为1的记录加排他锁;客户端二,如果也执行update语句更新id为1的数据,也要为id为1的数据加排他锁,但是客户端二会处于阻塞状态,因为排他锁之间是互斥的。直到客户端一,把事务提交了,才会把这一行的行锁释放,此时客户端二,解除阻塞。
D.无索引行锁升级为表锁
stu表中数据如下:
| mysq$4 - - - +$ | 1> | select | * from | stu; |
|---|---|---|---|---|
| I id$- - - +$ | name | age | ||
| 1 1 | I | Java | I 1 | |
| I 3I | I 3I | Java | L 3 | |
| 8 | rose | - 8 | ||
| I 11 | 1 | jetty | 11 | |
| 19 | I | 1i1y | 19 | |
| - 25 | I | luci | 25 | |
| 6 ro | ws in set (0.00 sec) | ws in set (0.00 sec) | ws in set (0.00 sec) | ws in set (0.00 sec) |
我们在两个客户端中执行如下操作:


在客户端一中,开启事务,并执行update语句,更新name为Lily的数据,也就是id为19的记录。然后在客户端二中更新id为3的记录,却不能直接执行,会处于阻塞状态,为什么呢?
原因就是因为此时,客户端一,根据name字段进行更新时,name字段是没有索引的,如果没有索引,此时行锁会升级为表锁(因为行锁是对索引项加的锁,而name没有索引)。
接下来,我们再针对name字段建立索引,索引建立之后,再次做一个测试:


此时我们可以看到,客户端一,开启事务,然后依然是根据name进行更新。而客户端二,在更新id为3的数据时,更新成功,并未进入阻塞状态。 这样就说明,我们根据索引字段进行更新操作,就可以避免行锁升级为表锁的情况。
5.4.3 间隙锁&临键锁
默认情况下,InnoDB在 REPEATABLE READ事务隔离级别运行,InnoDB使用 next-key 锁进行搜索和索引扫描,以防止幻读。
索引上的等值查询(唯一索引),给不存在的记录加锁时, 优化为间隙锁 。
索引上的等值查询(非唯一普通索引),向右遍历时最后一个值不满足查询需求时,next-key lock 退化为间隙锁。
索引上的范围查询(唯一索引)–会访问到不满足条件的第一个值为止。
注意:间隙锁唯一目的是防止其他事务插入间隙。间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务在同一间隙上采用间隙锁。
示例演示
A. 索引上的等值查询(唯一索引),给不存在的记录加锁时, 优化为间隙锁 。


B. 索引上的等值查询(非唯一普通索引),向右遍历时最后一个值不满足查询需求时,next-key lock 退化为间隙锁。
介绍分析一下:
我们知道InnoDB的B+树索引,叶子节点是有序的双向链表。 假如,我们要根据这个二级索引查询值为18的数据,并加上共享锁,我们是只锁定18这一行就可以了吗? 并不是,因为是非唯一索引,这个结构中可能有多个18的存在,所以,在加锁时会继续往后找,找到一个不满足条件的值(当前案例中也就是29)。此时会对18加临键锁,并对29之前的间隙加锁。



C. 索引上的范围查询(唯一索引)–会访问到不满足条件的第一个值为止。


查询的条件为id>=19,并添加共享锁。 此时我们可以根据数据库表中现有的数据,将数据分为三个部分:
[19]
(19,25]
(25,+∞]
所以数据库数据在加锁是,就是将19加了行锁,25的临键锁(包含25及25之前的间隙),正无穷的临键锁(正无穷及之前的间隙)。
6. InnoDB引擎
6.1 逻辑存储结构
InnoDB的逻辑存储结构如下图所示:

1). 表空间
表空间是InnoDB存储引擎逻辑结构的最高层, 如果用户启用了参数 innodb_file_per_table(在8.0版本中默认开启) ,则每张表都会有一个表空间(xxx.ibd),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
2). 段
段,分为数据段(Leaf node segment)、索引段(Non-leaf node segment)、回滚段(Rollback segment),InnoDB是索引组织表,数据段就是B+树的叶子节点, 索引段即为B+树的非叶子节点。段用来管理多个Extent(区)。
3). 区
区,表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
4). 页
页,是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
5). 行
行,InnoDB 存储引擎数据是按行进行存放的。
在行中,默认有两个隐藏字段:
$T r x _ { - } i d$
Roll_pointer:每次对某条引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
6.2 架构
6.2.1 概述
MySQL5.5 版本开始,默认使用InnoDB存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发中使用非常广泛。下面是InnoDB架构图,左侧为内存结构,右侧为磁盘结构。

6.2.2 内存结构

在左侧的内存结构中,主要分为这么四大块儿: Buffer Pool、Change Buffer、Adaptive Hash Index、Log Buffer。 接下来介绍一下这四个部分。
InnoDB存储引擎基于磁盘文件存储,访问物理硬盘和在内存中进行访问,速度相差很大,为了尽可能弥补这两者之间的I/O效率的差值,就需要把经常使用的数据加载到缓冲池中,避免每次访问都进行磁盘I/O。
在InnoDB的缓冲池中不仅缓存了索引页和数据页,还包含了undo页、插入缓存、自适应哈希索引以及InnoDB的锁信息等等。
缓冲池 Buffer Pool,是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
• free page:空闲page,未被使用。
• clean page:被使用page,数据没有被修改过。
• dirty page:脏页,被使用page,数据被修改过,也中数据与磁盘的数据产生了不一致。
在专用服务器上,通常将多达80%的物理内存分配给缓冲池 。参数设置: show variables
like ‘innodb_buffer_pool_size’;
2). Change Buffer
Change Buffer,更改缓冲区(针对于非唯一二级索引页),在执行DML语句时,如果这些数据Page 没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区 Change Buffer 中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。
Change Buffer的意义是什么呢?
先来看一幅图,这个是二级索引的结构图:

与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了ChangeBuffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
3). Adaptive Hash Index
自适应hash索引,用于优化对Buffer Pool数据的查询。MySQL的innoDB引擎中虽然没有直接支持hash索引,但是给我们提供了一个功能就是这个自适应hash索引。因为前面我们讲到过,hash索引在进行等值匹配时,一般性能是要高于B+树的,因为hash索引一般只需要一次IO即可,而B+树,可能需要几次匹配,所以hash索引的效率要高,但是hash索引又不适合做范围查询、模糊匹配等。
InnoDB存储引擎会监控对表上各索引页的查询,如果观察到在特定的条件下hash索引可以提升速度,则建立hash索引,称之为自适应hash索引。
自适应哈希索引,无需人工干预,是系统根据情况自动完成。
参数: adaptive_hash_index
4). Log Buffer
Log Buffer:日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log 、undo log),默认大小为 16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘 I/O。
参数:
innodb_log_buffer_size:缓冲区大小
∈odbflushlogdettxommit:日志刷新到磁盘时机,取值主要包含以下三个:
1: 日志在每次事务提交时写入并刷新到磁盘,默认值。
0: 每秒将日志写入并刷新到磁盘一次。
2:日志在每次事务提交后写入,并每秒刷新到磁盘一次。
| yeql> ahow variabien l |
|---|
| Variable name |
| innodb_flushin set(0.00S0C1 |
6.2.3 磁盘结构
接下来,再来看看InnoDB体系结构的右边部分,也就是磁盘结构:

1). System Tablespace
系统表空间是更改缓冲区的存储区域。如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)
参数:innodb_data_file_path
| nyaql> show varlables l |
|---|
| Varinble nam |
| innodb_data_file_path/$1 0 w i a m t ( 0 . 0 0 ) a e n$ |
系统表空间,默认的文件名叫 ibdata1。
2). File-Per-Table Tablespaces
如果开启了innodb_file_per_table开关,则每个表的文件表空间包含单个InnoDB表的数据和索引,并存储在文件系统上的单个数据文件中。
开关参数:innodb_file_per_table,该参数默认开启。
| Variable name |
| En- 10.00售 |
那也就是说,我们没创建一个表,都会产生一个表空间文件,如图:
| TA00 | 1 | ||||
|---|---|---|---|---|---|
| ENE | 147456 | :月 | |||
| mysdl myugl114608 | 1月 | ||||
| myaq1my1114688 | 1月 | 24 | |||
| 1 myemysgl 114688 | 1月 | ||||
| -ev-pocon | Imyagl nymgl212992 | 1月 | 24 | 13:40 | th uibd |
3). General Tablespaces
通用表空间,需要通过 CREATE TABLESPACE 语法创建通用表空间,在创建表时,可以指定该表空间。
A.创建表空间
1 CREATE TABLESPACE ts_name ADD DATAFILE ‘file_name’ ENGINE =engine_name;

B.创建表时指定表空间
1 CREATE TABLE XXX … TABLESPACE ts_name;
nysql> create tablo afid int prinary koy auto_incremont, Dago vazchar(10))orgino-imeo Sablouonb 9e_Lthetmal
Qunzy OK,a rowa affected (0.01 anc)
4).Undo Tablespaces
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
5). Temporary Tablespaces
InnoDB 使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
6). Doublewrite Buffer Files
双写缓冲区,innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
7). Redo Log
重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log
buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中, 用于在刷新脏页到磁盘时,发生错误时, 进行数据恢复使用。
以循环方式写入重做日志文件,涉及两个文件:
前面我们介绍了InnoDB的内存结构,以及磁盘结构,那么内存中我们所更新的数据,又是如何到磁盘中的呢? 此时,就涉及到一组后台线程,接下来,就来介绍一些InnoDB中涉及到的后台线程。

6.2.4 后台线程


在InnoDB的后台线程中,分为4类,分别是:Master Thread 、IO Thread、Purge Thread、Page Cleaner Thread。
1). Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中, 保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收 。
2). IO Thread
在InnoDB存储引擎中大量使用了AIO来处理IO请求, 这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
| 线程类型 | 默认个数 | 职责 |
|---|---|---|
| Read thread | 4 | 负责读操作 |
| Write thread | 4 | 负责写操作 |
| Log thread | 1 | 负责将日志缓冲区刷新到磁盘 |
| Insert buffer thread | 1 | 负责将写缓冲区内容刷新到磁盘 |
我们可以通过以下的这条指令,查看到InnoDB的状态信息,其中就包含IO Thread信息。

3). Purge Thread
主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
4). Page Cleaner Thread
协助 Master Thread 刷新脏页到磁盘的线程,它可以减轻 Master Thread 的工作压力,减少阻塞。
6.3 事务原理
6.3.1 事务基础
1). 事务
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
2). 特性
• 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
• 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
• 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
• 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
那实际上,我们研究事务的原理,就是研究MySQL的InnoDB引擎是如何保证事务的这四大特性的。




而对于这四大特性,实际上分为两个部分。 其中的原子性、一致性、持久化,实际上是由InnoDB中的两份日志来保证的,一份是redo log日志,一份是undo log日志。 而持久性是通过数据库的锁,加上MVCC来保证的。


我们在讲解事务原理的时候,主要就是来研究一下redolog,undolog以及MVCC。
6.3.2 redo log
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中, 用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用。
如果没有redolog,可能会存在什么问题的? 我们一起来分析一下。
我们知道,在InnoDB引擎中的内存结构中,主要的内存区域就是缓冲池,在缓冲池中缓存了很多的数据页。 当我们在一个事务中,执行多个增删改的操作时,InnoDB引擎会先操作缓冲池中的数据,如果缓冲区没有对应的数据,会通过后台线程将磁盘中的数据加载出来,存放在缓冲区中,然后将缓冲池中的数据修改,修改后的数据页我们称为脏页。 而脏页则会在一定的时机,通过后台线程刷新到磁盘中,从而保证缓冲区与磁盘的数据一致。 而缓冲区的脏页数据并不是实时刷新的,而是一段时间之后将缓冲区的数据刷新到磁盘中,假如刷新到磁盘的过程出错了,而提示给用户事务提交成功,而数据却没有持久化下来,这就出现问题了,没有保证事务的持久性。

那么,如何解决上述的问题呢? 在InnoDB中提供了一份日志 redo log,接下来我们再来分析一下,通过redolog如何解决这个问题。

有了redolog之后,当对缓冲区的数据进行增删改之后,会首先将操作的数据页的变化,记录在redo log buffer中。在事务提交时,会将redo log buffer中的数据刷新到redo log磁盘文件中。 过一段时间之后,如果刷新缓冲区的脏页到磁盘时,发生错误,此时就可以借助于redo log进行数据恢复,这样就保证了事务的持久性。 而如果脏页成功刷新到磁盘 或 或者涉及到的数据已经落盘,此时redolog就没有作用了,就可以删除了,所以存在的两个redolog文件是循环写的。
那为什么每一次提交事务,要刷新redo log 到磁盘中呢,而不是直接将buffer pool中的脏页刷新到磁盘呢 ?
因为在业务操作中,我们操作数据一般都是随机读写磁盘的,而不是顺序读写磁盘。 而redo log在往磁盘文件中写入数据,由于是日志文件,所以都是顺序写的。顺序写的效率,要远大于随机写。 这种先写日志的方式,称之为 WAL(Write-Ahead Logging)。
6.3.3 undo log
回滚日志,用于记录数据被修改前的信息 , 作用包含两个 : 提供回滚(保证事务的原子性) 和MVCC(多版本并发控制) 。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
Undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
Undo log存储:undo log采用段的方式进行管理和记录,存放在前面介绍的 rollback segment 回滚段中,内部包含1024个undo log segment。
6.4 MVCC
6.4.1 基本概念
1). 当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:select … lock in share mode(共享锁),select … for update、update、insert、delete(排他锁)都是一种当前读。
测试:


在测试中我们可以看到,即使是在默认的RR隔离级别下,事务A中依然可以读取到事务B最新提交的内容,因为在查询语句后面加上了 lock in share mode 共享锁,此时是当前读操作。当然,当我们加排他锁的时候,也是当前读操作。
2). 快照读
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
• Read Committed:每次select,都生成一个快照读。
• Repeatable Read:开启事务后第一个select语句才是快照读的地方。
• Serializable:快照读会退化为当前读。
测试:


在测试中,我们看到即使事务B提交了数据,事务A中也查询不到。 原因就是因为普通的select是快照读,而在当前默认的RR隔离级别下,开启事务后第一个select语句才是快照读的地方,后面执行相同的select语句都是从快照中获取数据,可能不是当前的最新数据,这样也就保证了可重复读。
3). MVCC
全称 Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log日志、readView。
接下来,我们再来介绍一下InnoDB引擎的表中涉及到的隐藏字段 、undolog 以及 readview,从而来介绍一下MVCC的原理。
6.4.2 隐藏字段
6.4.2.1 介绍
当我们创建了上面的这张表,我们在查看表结构的时候,就可以显式的看到这三个字段。 实际上除了这三个字段以外,InnoDB还会自动的给我们添加三个隐藏字段及其含义分别是:
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本。 |
| 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 |
而上述的前两个字段是肯定会添加的, 是否添加最后一个字段DB_ROW_ID,得看当前表有没有主键,如果有主键,则不会添加该隐藏字段。
6.4.2.2 测试
1). 查看有主键的表 stu
进入服务器中的 /var/lib/mysql/itcast/ , 查看stu的表结构信息, 通过如下指令:
1ibd2sdi stu.ibd
查看到的表结构信息中,有一栏 columns,在其中我们会看到处理我们建表时指定的字段以外,还有额外的两个字段 分别是:$D B _ T R X _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _$、 DBROLLPTR,因为该表有主键,所以没有$D B _ R O W _ I D$ 隐藏字段。
{
“name”:”DB_TRX_ID”,
“type”: 10,
“is_nullable”: false,
“is_zerofill”: false,
“is_unsigned”: false,
“is_auto_increment”: false,
“is_virtual”: false,
“hidden”: 2,
“ordinal position”: 4,
“char_length”: 6,
“numeric precision”: 0,
“numeric_scale”: 0,
“numeric_scale_null”: true,
“datetime precision”: 0,
“datetime precision_null”: 1,
“has_no_default”: false,
“default_value_null”: true,
“srs_id_null”: true,
“srs_id”: 0,
“default_value”: “”,
“default_value_utf8_null”: true,
“default_value_utf8”: “”,
“default_option”: “”,
“update_option”: “”,
“comment”: “”,
“generation_expression”: “”,
“generation_expression_utf8”: “”,
“options”: “”,
“se_private_data”: “table_id=1167;”,
“engine_attribute”: “”,
“secondary_engine_attribute”: “”,
“column_key”: 1,
“column_type_utf8”: “”,
“elements”: [],
“collation id”: 63,
“is explicit_collation”: false
{
“name”: “DB_ROLL_PTR”,
“type”: 9,
“is_nullable”: false,
“is_zerofill”: false,
“is_unsigned”: false,
“is auto increment”: false,
“is virtual”: false,
“hidden”: 2,
“ordinal position”: 5,

2). 查看没有主键的表 employee
建表语句:
1create table employee (id int , name varchar(10));
此时,我们再通过以下指令来查看表结构及其其中的字段信息:
1ibd2sdi employee.ibd
查看到的表结构信息中,有一栏 columns,在其中我们会看到处理我们建表时指定的字段以外,还有额外的三个字段 分别是:DBTRXTD、 DBROLLPTR、$D B R O W _ I D$,因为employee表是没有指定主键的。
{
“name”: “DB_ROW_ID”,
“type”: 10,
“is_nullable”: false,
“is_zerofill”: false,
“is_unsigned”: false,
“is_ auto_increment”: false,
“is_virtual”: false,
“hidden”: 2,
“ordinal position”: 3,
“char_length”: 6,
“numeric precision”: 0,
“numeric_scale”: 0,
“numeric_scale_null”: true,
“datetime precision”:0,
“datetime precision null”: 1,
“has_no_default”: false,
“default_value_null”: true,
“srs id_null”: true,
“srs_id”: 0,
“default_value”: “”,
“default_value_utf8_null”: true,
“default_value_utf8”: “”,
“default_option”: “”,
“update_option”: “”,
“comment”: “”,
“generation_expression”: “”,
“generation_expression_utf8”: “”,
“options”: “”,
“se_private_data”: “table_id=1168;”,
“engine attribute”:””,
“secondary_engine_attribute”: “”,
“column_key”: 1,
“column_type_utf8”: “”,
“elements”: [],
“collation id”: 63,
“is_explicit_collation”: false
{
“name”:”DB_TRX_ID”,
“type”: 10,
“is_nullable”: false,
“is_zerofill”: false,
“is_unsigned”: false,
“is auto_increment”: false,
“is_virtual”: fa1se,
“hidden”: 2,
“char _length”: 6,
“numeric precision”: 0,
“numeric_scale”: 0,
“numeric_scale null”: true,
“datetime precision”: 0,
“datetime precision null”: 1,
“has_no_default”: false,
“default_value_null”: true,
“srs_id_null”: true,
“srs_id”: 0,
“default_value”: “”,
“default_value_utf8_nul1”: true,
“default_value_utf8”: “”,
“default_option”: “”,
“update_option”: “”,
“comment”: “”,
“generation expression”:””,
“generation_expression_utf8”: “”,
“options”: “”,
“se_private_data”: “table_id=1168;”
“engine attribute”: “”,
“secondary_engine_attribute”: “”,
“column_key”: 1,
“column_type_utf8”: “”,
“elements”: [],
“collation_id”: 63,
“is_explicit_collation”: false
“name”:”DB_ROLL_PTR”,
“type”: 9,
“is_nullable”: false,
“is_zerofill”: false,
“is_unsigned”: false,
“is_auto_increment”: false,
“is_virtual”: false,
“hidden”: 2,
“ordinal position”: 5,
“char_length”: 7,
“numeric precision”: 0,
“numeric_scale”: 0,
“numeric_scale_ null”: true,
“datetime precision”: 0,
“datetime precision_null”: 1,
“has_no_default”: false,
“default_value_null”: true,
“srs id null”: true,
}
6.4.3 undolog
6.4.3.1介绍
回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志。
当insert的时候,产生的undo 1og日志只在回滚时需要,在事务提交后,可被立即删除。
而update、delete的时候,产生的undo 1og日志不仅在回滚时需要,在快照读时也需要,不会立即被删除。
6.4.3.2 版本链
有一张表原始数据为:
| id | age | name | DB_TRX_ID | DB_ROLL_PTR |
|---|---|---|---|---|
| 30 | 30 | A30 | 1 | null |
DB_TRX_ID:代表最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID,是自增的。
DB_ROLL_PTR:由于这条数据是才插入的,没有被更新过,所以该字段值为nu11。
然后,有四个并发事务同时在访问这张表。
A.第一步
| 事务2 | 事务3 | 事务4 | 事务5 |
|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 |
| 修改id为30记录.age改为3 | 查询id为30的记录 | ||
| 提交事务 | |||
| 修改id为30记录,name改为A3 | |||
| 查询id为30的记录 | |||
| 提交事务 | |||
| 修改id为30记录,age改为10 | |||
| 查询id为30的记录 | |||
| 查询id为30的记录 | |||
| 提交事务 |
当事务2执行第一条修改语句时,会记录undo 1og日志,记录数据变更之前的样子;然后更新记录,并且记录本次操作的事务ID,回滚指针,回滚指针用来指定如果发生回滚,回滚到哪一个版本。


B.第二步
| 事务2 | 事务3 | 事务4 | 事务5 |
|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 |
| 修改id为30记录.age改为3 | 查询id为30的记录 | ||
| 提交事务 | |||
| 修改id为30记录,name改为A3 | |||
| 查询id为30的记录 | |||
| 提交事务 | |||
| 修改id为30记录,age改为10 | |||
| 查询id为30的记录 | |||
| 查询id为30的记录 | |||
| 提交事务 |
当事务3执行第一条修改语句时,也会记录undo 1og日志,记录数据变更之前的样子;然后更新记录,并且记录本次操作的事务ID,回滚指针,回滚指针用来指定如果发生回滚,回滚到哪一个版本。

c.第三步
| 事务2 | 事务3 | 事务4 | 事务5 |
|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 |
| 修改id为30记录,age改为3 | 查询id为30的记录 | ||
| 提交事务 | |||
| 修改id为30记录.name改为A3 | |||
| 查询id为30的记录 | |||
| 提交事务 | |||
| 修改id为30记录,age改为10 | |||
| 查询id为30的记录 | |||
| 查询id为30的记录 | |||
| 提交事务 |
当事务4执行第一条修改语句时,也会记录undo 1og日志,记录数据变更之前的样子;然后更新记录,并且记录本次操作的事务ID,回滚指针,回滚指针用来指定如果发生回滚,回滚到哪一个版本。

最终我们发现,不同事务或相同事务对同一条记录进行修改,会导致该记录的undolog生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录。
6.4.4 readview
ReadView(读视图)是 快照读 SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
ReadView中包含了四个核心字段:
| 字段 | 含义 |
|---|---|
| 当前活跃的事务ID集合 | |
| 最小活跃事务ID | |
| 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) | |
| ReadView创建者的事务ID |
而在readview中就规定了版本链数据的访问规则:
txx⊥d 代表当前undolog版本链对应事务ID。
| 条件 | 是否可以访问 | 说明 |
|---|---|---|
| 可以访问该版本 | 成立,说明数据是当前这个事务更改的。 | |
| 可以访问该版本 | 成立,说明数据已经提交了。 | |
| 不可以访问该版本 | 成立,说明该事务是在ReadView生成后才开启。 | |
| 如果trx_id不在m_ids中,是可以访问该版本的 | 成立,说明数据已经提交。 |
不同的隔离级别,生成ReadView的时机不同:
READ COMMITTED :在事务中每一次执行快照读时生成ReadView。
REPEATABLE READ:仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
6.4.5 原理分析
6.4.5.1 RC隔离级别
RC隔离级别下,在事务中每一次执行快照读时生成ReadView。
我们就来分析事务5中,两次快照读读取数据,是如何获取数据的?
在事务5中,查询了两次id为30的记录,由于隔离级别为Read Committed,所以每一次进行快照读都会生成一个ReadView,那么两次生成的ReadView如下。
| 事务2 | 事务3 | 事务4 | 事务5 | |
|---|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 | |
| 修改id为30记录,age改为3 | 查询id为30的记录 | |||
| 提交事务 | Readview | |||
| 修改id为30记录,name改为A3 | m_idsi(3.4.5) | |||
| 查询id为30的记录 | min_trx_id:3 | |||
| 提交事务 | max_trx_id:6creator_trx_ld:5 | |||
| 修改id为30记录,age改为10 | max_trx_id:6creator_trx_ld:5 | |||
| 查询id为30的记录 | max_trx_id:6creator_trx_ld:5 | |||
| 查询id为30的记录 | ||||
| 提交事务 |
那么这两次快照读在获取数据时,就需要根据所生成的ReadView以及ReadView的版本链访问规则,到undolog版本链中匹配数据,最终决定此次快照读返回的数据。
A.先来看第一次快照读具体的读取过程:
| 事务2 | 事务3 | 事务4 | 事务5 | |
|---|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 | |
| 修改id为30记录,age改为3 | 查询id为30的记录 | |||
| ReadView | ||||
| 提交事务 | ||||
| 修改id为30记录,name改为A3 | m_ids:{3,4,5} | |||
| 查询id为30的记录 | min_trx_id:3 | |||
| 提交事务 | max_trx_id:6 | |||
| 修改id为30记录.age改为10 | creator_trx_id:5 | |||
| 查询id为30的记录 | creator_trx_id:5 | |||
| 查询id为30的记录 | ||||
| 提交事务 |


在进行匹配时,会从undo 1og的版本链,从上到下进行挨个匹配:
| * 先匹配 | id | age | name | DB_TRX_ID | DB_ROLL_PTR | 这条记录,这条记录对应的 |
|---|---|---|---|---|---|---|
| 30 | 10 | A3 | 4 | 0x00003 | 这条记录,这条记录对应的 |
trx_id为4,也就是将4带入右侧的匹配规则中。①不满足 ②不满足 ③不满足 ④也不满足,都不满足,则继续匹配undo 1og版本链的下一条。
- 再匹配第二条 0x00003 30 3 A3 3 0x00002 ,这条记录对应的trx_id为3,也就是将3带入右侧的匹配规则中。①不满足 ②不满足 ③不满足 ④也不满足,都不满足,则继续匹配undo 1og版本链的下一条。
| * 再匹配第三条 | 0x00002 | 30 | 3 | A30 | 2 | 0x00001 |
|---|
录对应的trx_id为2,也就是将2带入右侧的匹配规则中。①不满足 ②满足 终止匹配,此次快照读,返回的数据就是版本链中记录的这条数据。
B.再来看第二次快照读具体的读取过程:
| 事务2 | 事务3 | 事务4 | 事务5 | ||
|---|---|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 | ||
| 修改id为30记录.age改为3 | 查询id为30的记录 | ||||
| ReadView | |||||
| 提交事务 | ReadView | ||||
| 修改id为30记录,name改为A3 | m_lds:{3,4.5) | ReadView | |||
| 查询id为30的记录 | min_trx_ld:3 | ReadView | |||
| 提交事务 | max_trx_id:6creator_trx_id:5 | ReadView | |||
| 修改id为30记录,age改为10 | max_trx_id:6creator_trx_id:5 | ReadView | |||
| 查询id为30的记录 | ReadView | ||||
| 查询id为30的记录 | m_ids:{4, | ||||
| 提交事务 | min_trx_i |
creator_trx_id:5


在进行匹配时,会从undo 1og的版本链,从上到下进行挨个匹配:
| * 先匹配 | id | age | name | DB_TRX_ID | DB_ROLL_PTR | 这条记录,这条记录对应的 |
|---|---|---|---|---|---|---|
| 30 | 10 | A3 | 4 | Ox00003 | 这条记录,这条记录对应的 |
trx⊥d为4,,也就是将4带入右侧的匹配规则中。①不满足②不满足③不满足 ④也不满足,都不满足,则继续匹配undo 1og版本链的下一条。
- 再匹配第二条 0x00003 30 3 A3 3 0x00002 ,这条记录对应的trx_id为3,也就是将3带入右侧的匹配规则中。①不满足 ②满足。终止匹配,此次快照读,返回的数据就是版本链中记录的这条数据。
6.4.5.3 RR隔离级别
RR隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。而RR 是可重复读,在一个事务中,执行两次相同的select语句,查询到的结果是一样的。
那MysQL是如何做到可重复读的呢?我们简单分析一下就知道了
| 事务2 | 事务3 | 事务4 | 事务5 |
|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 |
| 修改id为30记录,age改为3 | 查询id为30的记录 | ||
| 提交事务 | |||
| 修改id为30记录,name改为A3 | |||
| 查询id为30的记录 | |||
| 提交事务 | |||
| 修改id为30记录,age改为10 | |||
| 查询id为30的记录 | |||
| 查询id为30的记录 | |||
| 提交事务 |
我们看到,在RR隔离级别下,只是在事务中第一次快照读时生成ReadView,后续都是复用该ReadView,那么既然ReadView都一样,ReadView的版本链匹配规则也一样,那么最终快照读返回的结果也是一样的。
所以呢,MvCC的实现原理就是通过 InnoDB表的隐藏字段、UndoLog 版本链、ReadView来实现的。而MVCC+锁,则实现了事务的隔离性。而一致性则是由redolog 与 undolog保证。

7.MySQL管理
7.1 系统数据库
Mysq1数据库安装完成后,自带了一下四个数据库,具体作用如下:
| 数据库 | 含义 |
|---|---|
| mysql | 存储MySQL服务器正常运行所需要的各种信息 (时区、主从、用户、权限等) |
| information_schema | 提供了访问数据库元数据的各种表和视图,包含数据库、表、字段类型及访问权限等 |
| performance_schema | 为MySQL服务器运行时状态提供了一个底层监控功能,主要用于收集数据库服务器性能参数 |
| sys | 包含了一系列方便 DBA 和开发人员利用 performance_schema性能数据库进行性能调优和诊断的视图 |
7.2 常用工具
7.2.1 mysql
该mysql不是指mysql服务,而是指mysql的客户端工具。
| 2 | mysql [options] [database] | mysql [options] [database] |
|---|---|---|
| 3 | 选项 : | 选项 : |
| 4 | #指定用户名 | |
| 5 | #指定密码 | |
| 6 | #指定服务器IP或域名 | |
| 7 | #指定连接端口 | |
| 8 | #执行SQL语句并退出 |
-e选项可以在Mysql客户端执行SQL语句,而不用连接到MySQL数据库再执行,对于一些批处理脚本,这种方式尤其方便。
示例:
1mysql -uroot –p123456 db01 -e “select * from stu”;

| mysql:[Warnin | g] | Usin |
|---|---|---|
| id | name l | agn |
| Jsp | ||
| 3 PHP | ||
| Enby | ||
| 8 Fose11 Jetcy | 11 | 11 |
| 19 Li1y | 19 | |
| 25 1uci | 25 | |
| [rootElocalhos | t | |
| ErootPlocathost- | ErootPlocathost- | 1 |
7.2.2 mysqladmin
mysqladmin 是一个执行管理操作的客户端程序。可以用它来检查服务器的配置和当前状态、创建并删除数据库等。
1 通过帮助文档查看选项:
2 mysqladmin –help
| —SEnd , | – -1– n-1 |
|---|---|
| Crent a ney data量 | |
| dahug | Instrurt rauver to vritn dabug isfornation to log |
| drap databagenmme | Teladtl |
| exhended-atatue | Givo an xtenad tata oge frcm th TT |
| fluah-hoNtN | rluah all carbad haata |
| Fluah-loge | Fluah all loga |
| Clushetatu | |
| Fushtabian | rLunh all tabie |
| Flush-theesde | Flush the Lh |
| Elunh-peivilege | Teload guant tabl |
| kill id,id…. | Till nyaql thre |
| Pastvord [nenFasawc | ed]Change ird to naw papovend in copsunt Foamat |
| ping | |
| Pracatiat | |
| reload | |
| Fah | |
| whutdon | |
| N | f |
| wtaxt-replice | |
| plien inatend | |
| atop-raplicm | Stop =splEcation |
| Lave | TapaaenBoe: uas atep-caplica |
| variablen | Printa variablaa |
| VeEon | Gal varion info |
| 1 | 语法: | 语法: |
|---|---|---|
| 2 | mysqladmin [options] command | mysqladmin [options] command |
| 3 | 选项: | 选项: |
| 4 | $- u , - u s e r = n a m e$ | #指定用户名 |
| 5 | $- p _ { t } - p a s s w o r d [ = n a m e ]$ | #指定密码 |
| 6 | $- h _ { t } - - h o s t = n a m e$ | #指定服务器IP或域名 |
| 7 | $- P , - - P O r t = p O r t$ | #指定连接端口 |
示例:
1 mysqladmin -uroot -p1234 drop ‘test01’;
2 mysqladmin -uroot -p1234 version;

7.2.3 mysqlbinlog
由于服务器生成的二进制日志文件以二进制格式保存,所以如果想要检查这些文本的文本格式,就会使用到mysqlbinlog 日志管理工具。
| 1 | 语法 : | ||
|---|---|---|---|
| 2 | mysqlbinlog [options] log-files1 log-files2 … | mysqlbinlog [options] log-files1 log-files2 … | mysqlbinlog [options] log-files1 log-files2 … |
| 3 | 选项 : | 选项 : | |
| 4 | -d, –database=name | 指定数据库名称,只列出指定的数据库相 | 关操作。 |
| 5 | 忽略掉日志中的前n行命令。 | ||
| 6 | -r,–result-fi | 将输出的文本格式日志输出到指定文件。 | |
| 7 | -s, | 显示简单格式, 省略掉一些信息。 | 显示简单格式, 省略掉一些信息。 |
| 8 | 指定日 | 期间隔内的所有日志 | |
| 9 | 指定位 | 置间隔内的所有日志 |
示例:
A. 查看 binlog.000008这个二进制文件中的数据信息

上述查看到的二进制日志文件数据信息量太多了,不方便查询。 我们可以加上一个参数 -s 来显示简单格式。

7.2.4 mysqlshow
mysqlshow 客户端对象查找工具,用来很快地查找存在哪些数据库、数据库中的表、表中的列或者索引。
| 1 | 语法 : |
|---|---|
| 2 | mysqlshow [options] [db_name [table_name [col_name]]] |
| 3 | 选项 : |
| 4 | –count 显示数据库及表的统计信息(数据库,表 均可以不指定 |
| 5 | -i 显示指定数据库或者指定表的状态信息 |
| 6 | 示例: |
| 7 | |
| 8 | |
| 9 | #查询test库中每个表中的字段书,及行数 |
| 10 | mysqlshow -uroot -p2143 test –count |
| 11 | |
| 12 | #查询test库中book表的详细情况 |
| 13 | mysqlshow -uroot -p2143 test book –count |
示例:
A.查询每个数据库的表的数量及表中记录的数量
mysqlshow -uroot -pl234 –count
| Datahanes | 密abion | Tatal Revs |
|---|---|---|
| db01 | 19 | |
| inforation e | 12932 | |
| ItcasL | 0t06 | |
| 1tbeina | 1000000 | |
| mgsql | 37 | 3956 |
| pertornance scherd | 110 | 45517 |
| aya | 101 | 150 |
| 7 rows 1m sec | 7 rows 1m sec | 7 rows 1m sec |
B.查看数据库db01的统计信息
mysqlshow -uroot -p1234 db01 –count
| [root@localhost aysgl]t nyagishow-uroot-p1234,db01-count | |
|---|---|
| myoqlshow:[Matning] daing a password on tho command tico Intorraco can Database:db01 | to inmaduro. |
| Yables Total Bows | |
| CO대ESCOED | |
| studentstudent course | |
| 4 roe in get. | 4 roe in get. |
c.查看数据库db01中的course表的信息
mysqlshow -uroot -p1234 db01 course –count
| Field | Type collatio | n Nu11 Koy | Dotaolt 00r0 | 019110000 | Ccanont |
| id | int | NO PRI0900 YEJ HOE | 0u50 B0n00 | 09 0 cohent,tnoane,opdstnd | ,re ferencos 十 D程名称 |
| Eame | varchar(10) ua-4 | 201001,1001s.upato | ,coforenoo 课( |
D.查看数据库db01中的course表的id字段的信息
mysqlshow -uroot -p1234 db01 course id –count
| (rostPlaenihont: synpllf nynginhoy -uractF1229 d01CHCACecuntnyaginhaw:[Marningl dalng a pannseed co the segpandLine intorface con Eo inso | (rostPlaenihont: synpllf nynginhoy -uractF1229 d01CHCACecuntnyaginhaw:[Marningl dalng a pannseed co the segpandLine intorface con Eo inso | (rostPlaenihont: synpllf nynginhoy -uractF1229 d01CHCACecuntnyaginhaw:[Marningl dalng a pannseed co the segpandLine intorface con Eo inso |
|---|---|---|
| Database: db01 Table: course Rowss | o WildcardE Ld | |
| Field I Type | Collation | Null |
| 1d 1int 1N0 | FRI auto tnorenont1 cote | ct,insort,apdito,rofororcon(主規ID 1 |

7.2.5 mysqldump
mysqldump 客户端工具用来备份数据库或在不同数据库之间进行数据迁移。备份内容包含创建表,及插入表的sQL语句。
| 1 | 语法: | 语法: |
|---|---|---|
| 2 | mysqldump [options] db_name [tables] | mysqldump [options] db_name [tables] |
| 3 | mysqldump [options]–database/-B db1 [db2 db3…] | mysqldump [options]–database/-B db1 [db2 db3…] |
| 4 | mysqldump [options] –all-databases/-A | mysqldump [options] –all-databases/-A |
| 5 | 连接选项: | 连接选项: |
| 6 | $- u _ { r } - u _ { S } e r = n a m e$ | 指定用户名 |
| 7 | $- p _ { t } - p a s s w o r d [ = n a m e ]$ | 指定密码 |
| 8 | $- h , - - h o s t = n a m e$ | 指定服务器ip或域名 |
| 9 | $- P , - p O r t = \psi$ | 指定连接端口 |
| 10 | 输出选项: | |
| 11 | $- - a d d - d r o p - d a t a b a s e$ | 在每个数据库创建语句前加上 drop database 语句 |
| 12 | $- - a d d - d r o p - t a b 1 e$ | 在每个表创建语句前加上 drop table 语句,默认开启;不 |
| 开启 $( - - s k 1 p - a d d - d x o p - t a b 1 e )$ | ||
| 13 | $- n _ { f } - n _ { 0 } - C r e a t e - d b$ | 不包含数据库的创建语句 |
| 14 | $- t , - n o - C r e a t e - \in f o$ | 不包含数据表的创建语句 |
| 15 | $- d - n o - d a t a$ | 不包含数据 |
| 16 | $- T , - - \tan s u n e$ | 自动生成两个文件:一个,sq1文件,创建表结构的语句:一 |
| 个.txt文件,数据文件 |
示例:
A.备份db01数据库
mysqldump -uroot -p1234 db01 > db01.sq1
| [root8localhost-1t nysgldunp-uroot-p1234 db01 > db01.col | [root8localhost-1t nysgldunp-uroot-p1234 db01 > db01.col | [root8localhost-1t nysgldunp-uroot-p1234 db01 > db01.col | [root8localhost-1t nysgldunp-uroot-p1234 db01 > db01.col | [root8localhost-1t nysgldunp-uroot-p1234 db01 > db01.col | [root8localhost-1t nysgldunp-uroot-p1234 db01 > db01.col | [root8localhost-1t nysgldunp-uroot-p1234 db01 > db01.col |
|---|---|---|---|---|---|---|
| ayaqldunp:[Marning] tainga pasaword cnLiCon[coot@localhost-]#[rootelocalhost -1# 11 | ayaqldunp:[Marning] tainga pasaword cnLiCon[coot@localhost-]#[rootelocalhost -1# 11 | ayaqldunp:[Marning] tainga pasaword cnLiCon[coot@localhost-]#[rootelocalhost -1# 11 | ayaqldunp:[Marning] tainga pasaword cnLiCon[coot@localhost-]#[rootelocalhost -1# 11 | ayaqldunp:[Marning] tainga pasaword cnLiCon[coot@localhost-]#[rootelocalhost -1# 11 | nandLineinterface con be inscaure | |
| 总用量 789348 | 总用量 789348 | 总用量 789348 | 总用量 789348 | 总用量 789348 | ||
| dENNE–R,2 Foot | root | 19月 | 11 | 19:36 | 0 | |
| devxe-xr 3 root | 200月 | 11 | 19:05 | 68 | ||
| —- 1 Loot | root | 12576月 | 10 | 03:54 | anacond | |
| LOO5 | 493712月 | 25 | 23:18 | 1501.591 | ||
| drwxr-xr-x. root | 21月 | 11 | 19:03 | :90898 | ||
| dEwr–x.2 rooE | roat | 21明月 | 11 | 19:05 | se | |
| drwxr-xz-x 2root | Foot | 409611月 | 1 | 00:08 | QE0 | |
| coot60 | 6273920 9月 | 15 | B00:41 | wym1-0-0.26-8-c5f.zt0.c0.apm-bundic.tom | ||
| drwxr-xr-x 2 COOL | COOL | 10111月 | B | 09:21 | 9혼 |
可以直接打开db01.sq1,来查看备份出来的数据到底什么样。

备份出来的数据包含:
删除表的语句
创建表的语句
数据插入语句
如果我们在数据备份时,不需要创建表,或者不需要备份数据,只需要备份表结构,都可以通过对应的参数来实现。
B. 备份db01数据库中的表数据,不备份表结构(-t)
mysqldump -uroot -p1234 -tdb01>db01.sq1

打开 db02.sql ,来查看备份的数据,只有insert语句,没有备份表结构。

C. 将db01数据库的表的表结构与数据分开备份(-T)
执行上述指令,会出错,数据不能完成备份,原因是因为我们所指定的数据存放目录/root,MySQL认为是不安全的,需要存储在MySQL信任的目录下。那么,哪个目录才是MysQL信任的目录呢,可以查看一下系统变量 secure_file_priv。执行结果如下:

| nyaql> ahow vaziableaLike | ‘Aae |
|---|---|
| Variable_name Valueandure File_priv | /var/ |
| 1 row in pot (0.01 900) |
| [rootE]ocalhost-11nysqldonp -urootp1214-t/var/1ib/nysql-fales/.db01.acorenysqldunpi [Warning]Using a pansword cn the ccan Line interto Can to ana[root8localhost-]#rootRlocalhost-11[root8locahost-18od/van/1ib/mys)-Cten/IrootBlocalhost nysqi-fes 11总用量IM-r–r–1 root root 1585 12月25 23:30 score.sq1-w-1nyaq1nyaq1 5012月25 23:30 acore.Lxt |
|---|
上述的两个文件score.sq1 中记录的就是表结构文件,而score.txt 就是表数据文件,但是需要注意表数据文件,并不是记录一条条的insert语句,而是按照一定的格式记录表结构中的数据。如下:

7.2.6 mysqlimport/source
1). mysqlimport
mysqlimport 是客户端数据导入工具,用来导入mysqldump 加-T 参数后导出的文本文件。
| 1 | 语法: |
|---|---|
| 2 | mysqlimport [options] db_name textfile1 [ |
| 3 4 |
示例:mysqlimport -uroot -p2143 test /tmp/city.txt |

2). source
如果需要导入sq1文件,可以使用mysq1中的source 指令:
| 1 语法: |
|---|
| 2 source /root/xxxxx.sq1 |
Mysql运维
1.日志
1.1 错误日志
错误日志是MysQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
该日志是默认开启的,默认存放目录/var/log/,默认的日志文件名为 mysqld.log。查看日志位置:
1 show variables like ‘%log_errors’;
| TarLabie nam |
|---|
| bislog arror action |
| Icg_aErorTodett |
| lcg srror varbos |
1.2 二进制日志
1.2.1 介绍
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
作用:①.灾难时的数据恢复;②.MysQL的主从复制。在MySQL8版本中,默认二进制日志是开启着的,涉及到的参数如下:
1 show variables like ‘%log_bin%’;
| myan> chi vaeiaiee Liae | myan> chi vaeiaiee Liae | |||
|---|---|---|---|---|
| Varil DATH | ||||
| Varil DATH | ||||
| Tein1eg_blab TAlog pin indexlog bin truat Function coeator log_hin_w.vi_nov_nvuntaaqlog.hin | mal/binaog |
6rc in met (0.00c
| 1ayewy | 912月 | 912月 | 3 | 1 15:51 | slalsg-000201 | |
|---|---|---|---|---|---|---|
| 1 | myy | 2015年1 | 2月 | 22:43 | hlalog-040102 | |
| 1A.す | anyg | 1751 | 月 | 10:30 | bialog.000003 | |
| 1 | mys=yaa- | 661537 1 | 月 | 16:06 | binlog.010104 | |
| TT | nynqL 2 | 13111 | 月 | 22:22 | bisleg05 | |
| 1E | nyaql nya | 3123631 | 月 | 16:04 | bislog. | |
| 1- | nyaqlnyaq | 57643 1576 | 月 | 2 | 2 16:07 | bi-leg 07 |
| IA-E | myaqhmyoa | 86321 | 月 | 2 | 51C14 | C00 |
| nyaql m | 1281 | 月 | 22:16:07 | 22:16:07 | binlog.index |
参数说明:
log_bin_basename:当前数据库服务器的binlog日志的基础名称(前缀),具体的binlog文件名需要再该basename的基础上加上编号(编号从000001开始)。
$\log _ b \in$index:binlog的索引文件,里面记录了当前服务器关联的binlog文件有哪些。
1.2.2 格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
| 日志格式 | 含义 |
|---|---|
| STATEMENT | 基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中。 |
| ROW | 基于行的日志记录,记录的是每一行的数据变更。(默认) |
| MIXED | 混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下会自动切换为ROW进行记录。 |
1show variables like ‘%binlog_format%’;

如果我们需要配置二进制日志的格式,只需要在 /etc/my.cnf 中配置 binlog_format 参数即可。
1.2.3 查看
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看,具体语法:
| 1 | mysqlbinlog | [ 参数选项 ] logfilename |
|---|---|---|
| 2 | ||
| 3 | 参数选项: | |
| 4 | -d | 指定数据库名称,只列出指定的数据库相关操作。 |
| 5 | -o | 忽略掉日志中的前n行命令。 |
| 6 | -v | 将行事件(数据变更)重构为SQL语句 |
| 7 | -vv | 将行事件(数据变更)重构为SQL语句,并输出注释信息 |
1.2.4 删除
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种方式清理日志:
| 指令 | 含义 |
|---|---|
| reset master | 删除全部 binlog 日志,删除之后,日志编号,将从 binlog.000001重新开始 |
| purge master logs to’binlog.*’ | 删除 * 编号之前的所有日志 |
| purge master logs before’yyyy-mm-dd hh24:mi:ss’ | 删除日志为 “yyyy-mm-dd hh24:mi:ss” 之前产生的所有日志 |
也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。
1show variables like ‘%binlog_expire_logs_seconds%’;
1.3 查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下,查询日志是未开启的。
如果需要开启查询日志,可以修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
1#该选项用来开启查询日志 , 可选值 : 0 或者 1 ; 0 代表关闭, 1 代表开启
2 $g e n e r a 1 _ 1 o q = 1$
3#设置日志的文件名 , 如果没有指定, 默认的文件名为 host_name.log
4 $g e n e r a l \bot o g f i l e = m y s q l _ { - } q u e x y . 1 0 g$
开启了查询日志之后,在MySQL的数据存放目录,也就是 /var/lib/mysql/ 目录下就会出现 $m y s q l _ q u e r y .$log 文件。之后所有的客户端的增删改查操作都会记录在该日志文件之中,长时间运行后,该日志文件将会非常大。
1.4 慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于 min_examined_row_limit 的所有的SQL语句的日志,默认未开启。long_query_time 默认为10 秒,最小为 0, 精度可以到微秒。
如果需要开启慢查询日志,需要在MySQL的配置文件 /etc/my.cnf 中配置如下参数:
| 1 | #慢查询日志 |
|---|---|
| 2 | 2 |
| 3 | #执行时间参数 |
| 4 |
默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用
10gslowadminstatements和 更改此行为 log_queries_not_using_indexes,如下所述。
| 1 | #记录执行较慢的管理语句 |
|---|---|
| 2 | |
| 3 | #记录执行较慢的未使用索引的语句 |
| 4 |
上述所有的参数配置完成之后,都需要重新启动MySQL服务器才可以生效。
2. 主从复制
2.1 概述
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。

MySQL 复制的优点主要包含以下三个方面:
主库出现问题,可以快速切换到从库提供服务。
实现读写分离,降低主库的访问压力。
可以在从库中执行备份,以避免备份期间影响主库服务。
2.2 原理
MySQL主从复制的核心就是 二进制日志,具体的过程如下:

从上图来看,复制分成三步:
Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
slave重做中继日志中的事件,将改变反映它自己的数据。
2.3 搭建
2.3.1 准备

准备好两台服务器之后,在上述的两台服务器中分别安装好MySQL,并完成基础的初始化准备(安装、密码配置等操作)工作。 其中:
192.168.200.200 作为主服务器master
192.168.200.201 作为从服务器slave
2.3.2 主库配置
- 修改配置文件 /etc/my.cnf
| 1 | #mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1 |
|---|---|
| 2 | |
| 3 | #是否只读,1 代表只读, 0 代表读写 |
| 4 | |
| 5 | #忽略的数据, 指不需要同步的数据库 |
| 6 | |
| 7 | #指定同步的数据库 |
| 8 |
2. 重启MySQL服务器
| 1 | systemc | tl restar | t mysqld |
|---|
3. 登录mysql,创建远程连接的账号,并授予主从复制权限
| 1 | #创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务 |
|---|---|
| 2 | CREATE USER ‘itcast‘@’%’ IDENTIFIED WITH mysql_nati |
| 3 | ; |
| 4 | #为 ‘itcast‘@’%’ 用户分配主从复制权限 |
| 5 | GRANT REPLICATION SLAVE ON . TO ‘itcast‘@’%’; |
4. 通过指令,查看二进制日志坐标
| 1 | show | master | status ; |
|---|
字段含义说明:
file : 从哪个日志文件开始推送日志文件
position : 从哪个位置开始推送日志
binlog_ignore_db : 指定不需要同步的数据库
2.3.3 从库配置
1. 修改配置文件 /etc/my.cnf
1#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,和主库不一样即可
2 secvwer-id=2
3#是否只读,1 代表只读, 0 代表读写
4 read-on1y=1
2. 重新启动MySQL服务
| 1 | systemctl | restart | mysqld |
|---|
3. 登录mysql,设置主库配置
上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本,执行如下SQL:
| CHANGE MASTER TO MA |
|---|
| ; |
| 参数名 | 含义 | 8.0.23之前 |
|---|---|---|
| SOURCE_HOST | 主库IP地址 | MASTER_HOST |
| SOURCE_USER | 连接主库的用户名 | MASTER_USER |
| SOURCE_PASSWORD | 连接主库的密码 | MASTER_PASSWORD |
| SOURCE_LOG_FILE | binlog日志文件名 | MASTER_LOG_FILE |
| SOURCE_LOG_POS | binlog日志文件位置 | MASTER_LOG_POS |
4. 开启同步操作
| 1 | start replica ; #8.0.22之后 |
|---|---|
| 2 | start slave ; #8.0.22之前 |
5. 查看主从同步状态
| 1 | show | replica | status ; | #8.0.22之后 |
|---|---|---|---|---|
| 2 | show | slave | status ; | #8.0.22之前 |

2.3.4 测试
1. 在主库 192.168.200.200 上创建数据库、表,并插入数据
| 1 | create database db01; |
|---|---|
| 2 | use db01; |
| 3 | create table tb_user( |
| 4 | id int(11) primary key not null auto_increment, |
| 5 | name varchar(50) not null, |
| 6 | sex varchar(1) |
| 7 | )engine=innodb default charset=utf8mb4; |
| 8 | insert into tb_user(id,name,sex) values(null,’Tom’, ‘1’),(null,’Trigger’,’0’),(null,’Dawn’,’1’); |
2. 在从库 192.168.200.201 中查询数据,验证主从是否同步
3. 分库分表
3.1 介绍
3.1.1 问题分析

随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存储,存在以下性能瓶颈:
IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。 请求数据太多,带宽不够,网络IO瓶颈。
CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
为了解决上述问题,我们需要对数据库进行分库分表处理。

分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
3.1.2 拆分策略
分库分表的形式,主要是两种:垂直拆分和水平拆分。而拆分的粒度,一般又分为分库和分表,所以组成的拆分策略最终如下:

3.1.3 垂直拆分
1.垂直分库

垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点:
每个库的表结构都不一样。
每个库的数据也不一样。
所有库的并集是全量数据。
2.垂直分表

垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
特点:
每个表的结构都不一样。
每个表的数据也不一样,一般通过一列(主键/外键)关联。
所有表的并集是全量数据。
3.1.4 水平拆分
1. 水平分库

水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。
特点:
每个库的表结构都一样。
每个库的数据都不一样。
所有库的并集是全量数据。
2. 水平分表

水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。
特点:
每个表的表结构都一样。
每个表的数据都不一样。
所有表的并集是全量数据。
在业务系统中,为了缓解磁盘IO及CPU的性能瓶颈,到底是垂直拆分,还是水平拆分;具体是分库,还是分表,都需要根据具体的业务需求具体分析。
3.1.5 实现技术
shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。


本次课程,我们选择了是MyCat数据库中间件,通过MyCat中间件来完成分库分表操作。
3.2 MyCat概述
3.2.1 介绍
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。
开发人员只需要连接MyCat即可,而具体底层用到几台数据库,每一台数据库服务器里面存储了什么数据,都无需关心。 具体的分库分表的策略,只需要在MyCat中配置即可。

优势:
性能可靠稳定
强大的技术团队
体系完善
社区活跃
3.2.2 下载

3.2.3 安装
Mycat是采用java语言开发的开源的数据库中间件,支持Windows和Linux运行环境,下面介绍MyCat的Linux中的环境搭建。我们需要在准备好的服务器中安装如下软件。
MySQL
JDK
Mycat
| 服务器 | 安装软件 | 说明 |
|---|---|---|
| 192.168.200.210 | JDK、Mycat | MyCat中间件服务器 |
| 192.168.200.210 | MySQL | 分片服务器 |
| 192.168.200.213 | MySQL | 分片服务器 |
| 192.168.200.214 | MySQL | 分片服务器 |
具体的安装步骤: 参考资料中提供的 《MyCat安装文档》即可,里面有详细的安装及配置步骤。
3.2.4 目录介绍
| [root@localhost mycat]#1 | [root@localhost mycat]#1 | [root@localhost mycat]#1 | 1 | ||
|---|---|---|---|---|---|
| 总用量 12 | |||||
| drwxr-xr-x 2 root | root | 1 | 90 12月 | 31 | 00:56 DAm |
| drwxruxrux 2 root | root | 4月 | 15 | 2020 | |
| dEWXEWXENX 4 root | root | 40 | 96 12月 | 31 | 00:56 |
| drwxE-xE-x 2 root | root | 40 | 9612月 | 31 | 00:56ES0 |
| drWXEWXENX2root | root | 612月 | 10 | 22:54 | |
| -EWXEr 1 root | root | 2 | 27 12月 | 21 | 14:22veraion.tt |
bin:存放可执行文件,用于启动停止mycat
conf:存放mycat的配置文件
lib:存放mycat的项目依赖包(jar)
logs:存放mycat的日志文件
3.2.5 概念介绍
在MyCat的整体结构中,分为两个部分:上面的逻辑结构、下面的物理结构。

在MyCat的逻辑结构主要负责逻辑库、逻辑表、分片规则、分片节点等逻辑结构的处理,而具体的数据存储还是在物理结构,也就是数据库服务器中存储的。
在后面讲解MyCat入门以及MyCat分片时,还会讲到上面所提到的概念。
3.3 MyCat入门
3.3.1 需求
由于 tb_order 表中数据量很大,磁盘Io及容量都到达了瓶颈,现在需要对tb_order 表进行数据分片,分为三个数据节点,每一个节点主机位于不同的服务器上,具体的结构,参考下图:

3.3.2 环境准备
准备3台服务器:
192.168.200.210:MyCat中间件服务器,同时也是第一个分片服务器。
192.168.200.213:第二个分片服务器。
192.168.200.214:第三个分片服务器。

并且在上述3台数据库中创建数据库 db01 。
3.3.3 配置
1). schema.xml
在schema.xml中配置逻辑库、逻辑表、数据节点、节点主机等相关信息。具体的配置如下:
| 1 | |
|---|---|
| 2 | <!DOCTYPE mycat:schema SYSTEM “schema.dtd”> |
| 3 | <mycat:schema xmlns:mycat=”http://io |
| 4 | <schema checkSQLschema=”true” sqlMaxLimit=”100”> |
| 5 | <table ORDER” ,dn2,dn3” |
| /> | /> |
| 6 | </schema> |
| 7 | |
| 8 | <dataNode |
| 9 | <dataNode |
| 10 | <dataNode |
| 11 | |
| 12 | <dataHost |
| 13 | “ |
| 13 | |
| 14 | <heartbeat>select user()</heartbeat> |
| 15 | |
| 16 | <writeHost dbc:mysql://192.168.200.210:3306? |
| 16 | useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8” |
| 17 | </dataHost> |
| 18 | |
| 19 | <dataHost |
| 20 | “ switchTy “ |
| 21 | <heartbeat>select |
| 22 | |
| 23 | <writeHost dbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8” |
| 24 | </dataHost> |
| 25 | |
| 26 | <dataHost |
| 27 | “ |
| 28 | <heartbeat>select |
| 29 | |
| 30 | <writeHost url=”jdbc:mysql://192.168.200.214:3306? |
| useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8” | |
| 31 | </dataHost> |
| 32 | </mycat:schema> |
2). server.xml
需要在server.xml中配置用户名、密码,以及用户的访问权限信息,具体的配置如下:
| 1 | |
|---|---|
| 2 | <property |
| 3 | <property |
| 4 | |
| 5 | <!– 表级 DML 权限设置 –> |
| 6 | |
| 7 | <privileges |
| 8 | <schema > |
| 9 | <table |
| 10 | </schema> |
| 11 | </privileges> |
| 12 | –> |
| 13 | |
| 14 | |
| 15 | <property |
| 16 | <property |
| 17 | <property |
| 18 |
上述的配置表示,定义了两个用户 root和 user,这两个用户都可以访问 DB01 这个逻辑库,访问密码都是123456,但是root用户访问DB01逻辑库,既可以读,又可以写,但是 user用户访问DB01逻辑库是只读的。
3.3.4 测试
3.3.4.1 启动
配置完毕后,先启动涉及到的3台分片服务器,然后启动MyCat服务器。切换到Mycat的安装目录,执行如下指令,启动Mycat:
| 1 | #启动 |
|---|---|
| 2 | bin/mycat start |
| 3 | #停止 |
| 4 | bin/mycat stop |
Mycat启动之后,占用端口号 8066。
启动完毕之后,可以查看1ogs目录下的启动日志,查看Mycat是否启动完成。
| [root@l | ocalhost | myca | t]# tail - | f lcgs/wra | pper.log |
|---|---|---|---|---|---|
| INFO | jvm 1 | 2021/12/31 | 01:58:24 | ||
| INFO | jvm 1 | 2021/12/31 | 01:58:25 | I MycAT Server startup successfully.see logs in lcgs/mycat.log | |
| STATUS | wrapper | 2021/12/31 | 02:03:58 | TERM trapped. Shutting downe | |
| 5TATUS | vrapper | 2 | 021/12/31 | 02:04:00 | I <– Wrapper Stopped |
| STATUS | I vrapper | 2 | 021/12/31 | 02:04:15 | 0Wrapper Started Of Daemon |
| STATUS | I vrapper | 2021/12/31 | 02:04:15 | I Launching a JVMo0 | |
| INFO | jvm 1 | 2 | 021/12/31 | 02:04:16 | [ Wrapper (Version 3.2.3) httpt//wrapper.Canukisoftware.org |
| INFO | jva 1 | 2021/12/31 | 02:04:16 | Copyright 1999-2006 Tanuki Softvare,Ine. All Rights Reserved. | |
| INFO | 5vm1 | 2021/12/31 | 02:04:16 | ||
| INFO | I jvm 1 | 2 | 021/12/31 | 02:04:10 | I MycAT Server startup succossfuliy,ceo loge in legs/mycat.log |
3.3.4.2 测试
1),连接MyCat
通过如下指令,就可以连接并登陆MyCat。
1 mysq1 -h 192.168.200.210 -P 8066 -uroot -p123456
我们看到我们是通过MysQL的指令来连接的MyCat,因为MyCat在底层实际上是模拟了MySQL的协议。
2).数据测试
然后就可以在MyCat中来创建表,并往表结构中插入数据,查看数据在MysQL中的分布情况。
| 1 | CREATE TABLE TB_ORDER ( |
|---|---|
| 2 | id BIGINT(20) NOT NULL, |
| 3 | title VARCHAR(100) NOT | title VARCHAR(100) NOT | NULL , | |
|---|---|---|---|---|
| 4 | PRIMARY KEY (id) | PRIMARY KEY (id) | ||
| 5 | ) ENGINE=INNODB DEFAULT C | ) ENGINE=INNODB DEFAULT C | HARSET=utf8 ; | |
| 6 | ||||
| 7 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(1,’goods1 | ‘); |
| 8 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(2,’goods2 | ‘); |
| 9 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(3,’goods3 | ‘); |
| 10 | ||||
| 11 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(1,’goods1 | ‘); |
| 12 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(2,’goods2 | ‘); |
| 13 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(3,’goods3 | ‘); |
| 14 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(5000000,’ | goods5000000’); |
| 15 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(10000000, | ‘goods10000000’); |
| 16 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(10000001, | ‘goods10000001’); |
| 17 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(15000000, | ‘goods15000000’); |
| 18 | INSERT IN | TO TB_ORDER(id,t | itle) VALUES(15000001, | ‘goods15000001’); |
经过测试,我们发现,在往 TB_ORDER 表中插入数据时:
如果id的值在1-500w之间,数据将会存储在第一个分片数据库中。
如果id的值在500w-1000w之间,数据将会存储在第二个分片数据库中。
如果id的值在1000w-1500w之间,数据将会存储在第三个分片数据库中。
如果id的值超出1500w,在插入数据时,将会报错。
为什么会出现这种现象,数据到底落在哪一个分片服务器到底是如何决定的呢? 这是由逻辑表配置时的一个参数 rule 决定的,而这个参数配置的就是分片规则,关于分片规则的配置,在后面的课程中会详细讲解。
3.4 MyCat配置
3.4.1 schema.xml
schema.xml 作为MyCat中最重要的配置文件之一 , 涵盖了MyCat的逻辑库 、 逻辑表 、 分片规则、分片节点及数据源的配置。
cnycatiachena xninainycat=”http://io.myoat/“>
主要包含以下三组标签:
schema标签
datanode标签
datahost标签
3.4.1.1 schema标签
1).schema 定义逻辑库
<schema name=”DB01” checkSQLschema=”true”sqlMaxLimit=”100”4
<table name=”TB_ORDER” dataNode=”dn1,dn2,dn3”rule=”auto-sharding-long”/></schema>
schema 标签用于定义 MyCat实例中的逻辑库,一个MyCat实例中,可以有多个逻辑库,可以通过schema 标签来划分不同的逻辑库。MyCat中的逻辑库的概念,等同于MysQL中的database概念,需要操作某个逻辑库下的表时,也需要切换逻辑库(use xxx)。
核心属性:
name:指定自定义的逻辑库库名
checkSQLschema:在sQL语句操作时指定了数据库名称,执行时是否自动去除;true:自动去除,false:不自动去除
sq1MaxLimit:如果未指定1imit进行查询,列表查询模式查询多少条记录
2),schema 中的table定义逻辑表
<schema name=”DB01” checkSQLschema=”true”8qlMaxLimit=”100”>
<table name=”TB ORDER”$d a t a N o d = ^ { n } d n 1 , d n 2 , d n 3 ^ { n }$ $x u l e = u a u t o - s h a x d i n g - 1 o n g ^ { \prime \prime }$</schema>
table 标签定义了MyCat中逻辑库schema下的逻辑表,所有需要拆分的表都需要在table标签中定义。
核心属性:
name:定义逻辑表表名,在该逻辑库下唯一
dataNode:定义逻辑表所属的dataNode,该属性需要与dataNode标签中name对应;多个dataNode逗号分隔
rule:分片规则的名字,分片规则名字是在rule.xm1中定义的
primaryKey:逻辑表对应真实表的主键
type:逻辑表的类型,目前逻辑表只有全局表和普通表,如果未配置,就是普通表;全局表,配置为 globa1
3.4.1.2 datanode标签
<dataNodename=”dn1” dataHOst=”dhost1” database=”db01” 1><dataNodename=”dn2” dataHOst=”dhost2” database=”db01” 1><dataNodename=”dn3” dataHOst=”dhost3” database=”db01”
核心属性:
name:定义数据节点名称
dataHost:数据库实例主机名称,引用自 dataHost 标签中name属性
database:定义分片所属数据库
3.4.1.3 datahost标签
<datallost nane=”dhost1” maxCon=”1000” minCon=10 balance=”0”writeType=”0”$d b T ) P o = “ m / s q 1 ^ { n }$bDriver=”jdbe”>cheartbeat>select user(}</heartbeat>
cwritelost host=”master” url=*jdbo:mysql://192.168.200.210:33067use88L-false6ampz8erve1 Asia/Shanghaisamp:characterEncoding=utf8”uner=”root” password=”1234”></writeHont>
</datalont>
该标签在MyCat逻辑库中作为底层标签存在,直接定义了具体的数据库实例、读写分离、心跳语句。
核心属性:
name:唯一标识,供上层标签使用
maxCon/minCon:最大连接数/最小连接数
balance:负载均衡策略,取值0,1,2,3
writeType:写操作分发方式(0:写操作转发到第一个writeHost,第一个挂了,切换到第二个;1:写操作随机分发到配置的writeHost)
dbDriver:数据库驱动,支持 native、jdbc
3.4.2 rule.xml
rule.xml中定义所有拆分表的规则, 在使用过程中可以灵活的使用分片算法, 或者对同一个分片算法使用不同的参数, 它让分片过程可配置化。主要包含两类标签:tableRule、Function。

3.4.3 server.xml
server.xml配置文件包含了MyCat的系统配置信息,主要有两个重要的标签:system、user。
1). system标签
主要配置MyCat中的系统配置信息,对应的系统配置项及其含义,如下:
| 属性 | 取值 | 含义 |
|---|---|---|
| charset | utf8 | 设置Mycat的字符集, 字符集需要与MySQL的字符集保持一致 |
| nonePasswordLogin | 0,1 | 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户 |
| useHandshakeV10 | 0,1 | 使用该选项主要的目的是为了能够兼容高版本的jdbc驱动, 是否采用HandshakeV10Packet来与client进行通信, 1:是, 0:否 |
| useSqlStat | 0,1 | 开启SQL实时统计, 1 为开启 , 0 为关闭 ;开启之后, MyCat会自动统计SQL语句的执行情况 ; mysql -h 127.0.0.1 -P 9066-u root -p 查看MyCat执行的SQL, 执行效率比较低的SQL , SQL的整体执行情况、读写比例等 ; show @@sql ; show@@sql.slow ; show @@sql.sum ; |
| useGlobleTableCheck | 0,1 | 是否开启全局表的一致性检测。1为开启 ,0为关闭 。 |
| sqlExecuteTimeout | 1000 | SQL语句执行的超时时间 , 单位为 s ; |
| sequnceHandlerType | 0,1,2 | 用来指定Mycat全局序列类型,0 为本地文件,1 为数据库方式,2 为时间戳列方式,默认使用本地文件方式,文件方式主要用于测试 |
| sequnceHandlerPattern | 正则表达式 | 必须带有MYCATSEQ或者 mycatseq进入序列匹配流程 注意MYCATSEQ_有空格的情况 |
| subqueryRelationshipCheck | true,false | 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false |
| useCompression | 0,1 | 开启mysql压缩协议 , 0 : 关闭, 1 : 开启 |
| fakeMySQLVersion | 5.5,5.6 | 设置模拟的MySQL版本号 |
| 属性 | 取值 | 含义 |
|---|---|---|
| defaultSqlParser | 由于MyCat的最初版本使用了FoundationDB的SQL解析器, 在MyCat1.3后增加了Druid解析器, 所以要设置defaultSqlParser属性来指定默认的解析器; 解析器有两个 :druidparser 和 fdbparser, 在MyCat1.4之后,默认是druidparser,fdbparser已经废除了 | |
| processors | 1,2…. | 指定系统可用的线程数量, 默认值为CPU核心x 每个核心运行线程数量; processors 会影响processorBufferPool,processorBufferLocalPercent,processorExecutor属性, 所有, 在性能调优时, 可以适当地修改processors值 |
| processorBufferChunk | 指定每次分配Socket Direct Buffer默认值为4096字节, 也会影响BufferPool长度,如果一次性获取字节过多而导致buffer不够用, 则会出现警告, 可以调大该值 | |
| processorExecutor | 指定NIOProcessor上共享businessExecutor固定线程池的大小;MyCat把异步任务交给 businessExecutor线程池中, 在新版本的MyCat中这个连接池使用频次不高, 可以适当地把该值调小 | |
| packetHeaderSize | 指定MySQL协议中的报文头长度, 默认4个字节 | |
| maxPacketSize | 指定MySQL协议可以携带的数据最大大小, 默认值为16M | |
| idleTimeout | 30 | 指定连接的空闲时间的超时长度;如果超时,将关闭资源并回收, 默认30分钟 |
| 属性 | 取值 | 含义 |
| txIsolation | 1,2,3,4 | 初始化前端连接的事务隔离级别,默认为REPEATED_READ , 对应数字为3READ_UNCOMMITED=1;READ_COMMITTED=2; REPEATED_READ=3;SERIALIZABLE=4; |
| sqlExecuteTimeout | 300 | 执行SQL的超时时间, 如果SQL语句执行超时,将关闭连接; 默认300秒; |
| serverPort | 8066 | 定义MyCat的使用端口, 默认8066 |
| managerPort | 9066 | 定义MyCat的管理端口, 默认9066 |
2). user标签
配置MyCat中的用户、访问密码,以及用户针对于逻辑库、逻辑表的权限信息,具体的权限描述方式及配置说明如下:

在测试权限操作时,我们只需要将 privileges 标签的注释放开。 在 privileges 下的schema 标签中配置的dml属性配置的是逻辑库的权限。 在privileges的schema下的table标签的dml属性中配置逻辑表的权限。
3.5 MyCat分片
3.5.1 垂直拆分
3.5.1.1 场景
在业务系统中, 涉及以下表结构 ,但是由于用户与订单每天都会产生大量的数据, 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分, 原有的数据库表如下。

现在考虑将其进行垂直分库操作,将商品相关的表拆分到一个数据库服务器,订单表拆分的一个数据库服务器,用户及省市区表拆分到一个服务器。最终结构如下:

3.5.1.2 准备
准备三台服务器,IP地址如图所示:

并且在192.168.200.210,192.168.200.213, 192.168.200.214上面创建数据库shopping。
3.5.1.3 配置
1). schema.xml
| 1 | <schema name=”SHOPPING” checkSQLsche sqlMaxLimi | <schema name=”SHOPPING” checkSQLsche sqlMaxLimi |
|---|---|---|
| 2 | <ta | ble “ /> |
| 3 | <ta | ble “ /> |
| 4 | <ta | ble primaryK /> |
| 5 | primary “ /> | |
| 6 | /> | |
| 7 | ||
| 8 | <ta | ble item” primaryK /> |
| 9 | <ta | ble /> |
| 10 | primary / | |
| 11 | ||
| 12 | <ta | ble /> |
| 13 | primaryKey=”id” | |
| 14 | ||
| 15 | <ta | ble name=”tb_areas_provinces” dataNode=”dn3” |
| 16 | <table | |
| 17 | <table | primaryKey=”id”/> |
| 18 | </schema> | |
| 19 | ||
| 20 | <dataNode | |
| 21 | <dataNode | |
| 22 | <dataNode | |
| 23 | ||
| 24 | <dataHost dhost1” | |
| 25 | ||
| 26 | <heartbeat>select user()</heartbea | t> |
| 27 | <writeHost | :mysql://192.168.200.210:3306? |
| useSSL=false&serverTimezone=Asia/S | hanghai&characterEncoding= | |
| 28 | </dataHost> | |
| 29 | ||
| 30 | <dataHost | |
| 31 | ||
| 32 33 |
<heartbeat>select user()</heartbea <writeHost dbc | t>:mysql://192.168.200.213:3306? |
| 32 33 |
useSSL=false&serverTimezone=Asia/S | hanghai&characterEncoding= |
| 34 | </dataHost> | |
| 35 | ||
| 36 | <dataHost | |
| 37 | ||
| 38 39 |
<heartbeat>select user()</heartbea <writeHost dbc | t>:mysql://192.168.200.214:3306? |
| 38 39 |
lse&serverTimezone=Asia/S | hanghai&characterEncoding= |
| 40 | </dataHost> |
| 1 | $< u s e r n a m e = ^ { n } r o o t ^ { n }$$\det a u l t A c c c o u n t = “ 七 r u e ^ { n } >$ |
|---|---|
| 2 | <property$n a m e = “ p a s s w o r d “ > 1 2 3 4 5 6 < / p x o p e r t y >$ |
| 3 | <property$n a m e = “ s c h e m a s ^ { \prime \prime } > S H O P I N G < / p x O p e x t y >$ |
| 4 | |
| 5 | <1–表级 DML 权限设置–> |
| 6 | $< ! - -$ |
| 7 | <privileges$c h e c k = “ 七 r u e “ >$ |
| 8 | <schema$n a m e = “ D B 0 1 “$$d m 1 = “ 0 1 1 0 “ >$ |
| 9 | $< t a b l e$$n a m e = “ T B O R D E R “$$d m l = ^ { n } 1 1 1 0 ^ { n } > < / \tan 1 e >$ |
| 10 | </schema> |
| 11 | </privileges> |
| 12 | –> |
| 13 | </user> |
| 14 | |
| 15 | $< u S e r n a m e = “ u s e r “ >$ |
| 16 | <property$n a m e = ^ { n } P a s s w o x d ^ { n } > 1 2 3 4 5 6 < / p x o p e x t y >$ |
| 17 | <property$n a m e = ^ { \prime \prime } S c h e m a s ^ { \prime \prime } > S H O P P I N G < / p r o p e r t y >$ |
| 18 | <property$n a m e = “ x e a d O n l y “ > t x u e < / p x o p e x t y >$ |
| 19 | $< / u s e r >$ |
3.5.1.4 测试
1).上传测试SQL脚本到服务器的/root目录
—– 1 root root 233274 1月 7 00:20shopping-insert.sq1
-EN-F–F- 1 raat reet 91901月 7 00:29 shopping-table.co
2).执行指令导入测试数据
重新启动MyCat后,在mycat的命令行中,通过source指令导入表结构,以及对应的数据,查看数据分布情况。
1 source /root/shopping-table.sq1
2 source/root/shopping-insert.sq1
将表结构及对应的测试数据导入之后,可以检查一下各个数据库服务器中的表结构分布情况。检查是否和我们准备工作中规划的服务器一致。
MySQL-192.168.200.214
db01
등information_schema
mysql
performance_schema
shopping


tables 5
tb_areas_city
tb_areas_provinces
tb_areas_region
tb_user
tb_user_address
3).查询用户的收件人及收件人地址信息(包含省、市、区)。
在MyCat的命令行中,当我们执行以下多表联查的sQL语句时,可以正常查询出数据。
| select ua.user_id, ua.contact, p.province, c.city,r.area, ua.address from$t b u s e r a d d r e s s$a%$t b a r e a s c i t y c ,$tb_areas provinces p,tb_areas region r$u a \cdot p r o v \in c e i d = p .$ |
|---|
| where provinceid and ua.city_id=c.cityid and ua.town_id- |
| and ua.city_id=c.cityid | and ua.city_id=c.cityid | and ua.city_id=c.cityid | |||
|---|---|---|---|---|---|
| CITY | Add1es | ||||
| deng | 市信区 | 西城区 | 咏春式信日部 | ||
| dang | 1德区 | 文区 | 承有试信 | ||
| 李佳红 | 北京市 | 市辖区 | 文区 | 修正大? | |
| zhaou | 코三 | 市辖区 | 宣武区 | 西白门 | |
| 李住星 | 市辖区 | 明归区 | 中药大厦 | ||
| 运 | 非国区 | 区 | 会态龙办公 | ||
4).查询每一笔订单及订单的收件地址信息(包含省、市、区)。
实现该需求对应的sQL语句如下:
| SELECT$o r d e r _ { - } i d$,payment ,receiver, province, city, area FROMtb_order_master ,tb_areas_provinces p,$t b a r e a s c i t y$$c ,$tb_areas region r WHEREo.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND |
|---|
但是现在存在一个问题,订单相关的表结构是在192.168.200.213 数据库服务器中,而省市区的数据库表是在192.168.200.214 数据库服务器中。那么在MyCat中执行是否可以成功呢?

经过测试,我们看到,sQL语句执行报错。原因就是因为MyCat在执行该sQL语句时,需要往具体的数据库服务器中路由,而当前没有一个数据库服务器完全包含了订单以及省市区的表结构,造成SQL语句失败,报错。
对于上述的这种现象,我们如何来解决呢?下面我们介绍的全局表,就可以轻松解决这个问题。
3.5.1.5 全局表
对于省、市、区/县表tb_areas_provinces,$t b \underline { } a r e a s \underline { c i t y }$1 tbareasregion,是属于数据字典表,在多个业务模块中都可能会遇到,可以将其设置为全局表,利于业务操作。
修改schema.xm1中的逻辑表的配置,修改tb_areas_provinces、tbareascity、
tb_areas_region 三个逻辑表,增加 type 属性,配置为global,就代表该表是全局表,就会在所涉及到的dataNode中创建给表。对于当前配置来说,也就意味着所有的节点中都有该表了。
1 <table$n a m e = “ 七 b _ { - }$reas provinces” dataNdΔde=dn1,dn2,dn3”primaryKey=”id”$t y p e = ^ { \prime \prime } g 1 o b a 1 ^ { \prime \prime } / >$
2 <tab1e$n a m e = “ t b a r e a s c i t y ^ { n }$detaNode=”dn1,dn2,dn3”primaryKey=”id”type=”global”/>
3 <table$n a m e = “ t b a r e a s r e q i o n ^ { n }$dataNcde=”dn1,dn2,dn3”$p r i m a r y k e y = ^ { \prime \prime } i d ^ { \prime \prime }$type=”g1oba1”/>

配置完毕后,重新启动MyCat。
1). 删除原来每一个数据库服务器中的所有表结构
2). 通过source指令,导入表及数据
| 1 | source /root/shopping-table.sql |
|---|---|
| 2source /root/shopping-insert.sql | 2source /root/shopping-insert.sql |
3). 检查每一个数据库服务器中的表及数据分布,看到三个节点中都有这三张全局表
4). 然后再次执行上面的多表联查的SQL语句
| SELECT order_id, payment,receiver, province, city , area FROM tb_order mastertb_areas provincesP,tb_areas$\underline c i t y$ $。$ tb_areas region r WHERE$0 . r e c e i v e r \underline { p r } p r o v \in e e = p$.provinceid ANDo.receiver_city = c.cityid AND |
|---|
| order_id | Fayrepcnt | IECCITCT | PECVIBCe | cEty | arce | |
|---|---|---|---|---|---|---|
| 992605539282190336 | 0.03 | 开码 | 北京市 | 市辖区 | 寿汕区 | |
| 173906429952 | 0.01 | HO | 北京市 | 非住区 | 海鸿区 | |
| 9925 | 0.02 | 时间 | 北京市 | 市辖区 | 海陀区 | |
| 992554565454827809 | 0.02 | 时刻 | 北市 | 海淀区 | ||
| 2197263067447296 | 01 | 叶月 | 北京市 | 市籍区 | 专 区 | |
| 992197105547137792 | 0.01 | 时可 | 北京市 | 市国区 | 证国 | |
| 992196968627306496 | 0.01 | 计日 | 北京市 | 市林区 | 鲁区 | |
| 992196116772552704 | 0.01 | 计日 | 北京市 | 市 区 | 海淀区 | |
| 992195664538501120 | 0.01 | 许号 | 北京市 | 证号 | 海达区 | |
| 92194631620224560 | 0.01 | H리 | 北京市 | 市辖区 | 海建区 | |
| 992192599722146204 | 0.01 | 时리 | 北京市 | 辖区 | ||
| 992192064319912994 | 0.01 | 叶间 | 北京市 | +® | 定区 | |
| 992191916919455512 | 0.01 | HO | 北京市 | 市 | 海淀区 | |
| 992190947183620600 | 0.02 | 时间 | 北京市 | C | 海鸿区 | |
| 992190237948957440 | 0.17 | HG | 1京市 | 非籍区 | 证区 | |
| 919059760849863424 | 0.02 | 李 证 | 北京市 | 住籍区 | 有证码 | |
| 919055624054031536 | 0.01 | 李佳早 | 市话区 | |||
| 910035712441212920 | 0.01 | 佳号 | 非京市 | 市籍区 | 海地区 | |
| 910033405639001904 | 0.01 | 李佳早 | 년 | 福州市 | 甘营区 | |
| 910006410454654976 | 0.01 | 李佳呈 | 恒建省 | 福州市 | 巨安区 | |
| 916780408353546240 | 0.01 | 李小22 | 福建省 | 福州市 | 百安区 | |
| 73289399160832 | 200.00 | 李小龙 | 福建省 | 福州市 | 日安 | |
| 9102349946901438641 | 1799.00 | 1 李小龙 | 有建台 | 福州市 | 白安区 |
是可以正常执行成功的。
5).当在MyCat中更新全局表的时候,我们可以看到,所有分片节点中的数据都发生了变化,每个节点的全局表数据时刻保持一致。
3.5.2 水平拆分
3.5.2.1 场景
在业务系统中,有一张表(日志表),业务系统每天都会产生大量的日志数据,单台服务器的数据存储及处理能力是有限的,可以对数据库表进行拆分。


tb_log
3.5.2.2 准备

并且,在三台数据库服务器中分表创建一个数据库itcast。
3.5.2.3 配置
1). schema.xml
| 1 | <schema ITCAST” checkSQLschema=”true” sqlMaxLimit=”100”> |
|---|---|
| 2 | <table ,dn5,dn6” / |
| 3 | </schema> |
| 4 | |
| 5 | <dataNode /> |
| 6 | <dataNode /> |
| 7 | <dataNode /> |
tb_log表最终落在3个节点中,分别是 dn4、dn5、dn6 ,而具体的数据分别存储在 dhost1、dhost2、dhost3的itcast数据库中。
2). server.xml
配置root用户既可以访问 SHOPPING 逻辑库,又可以访问ITCAST逻辑库。
| 1 | <user |
|---|---|
| 2 | <property |
| 3 | <property chemas”>SHOPPING,ITCAST</property> |
| 4 | |
| 5 | <!– 表级 DML 权限设置 –> |
| 6 | |
| 7 | <privileges |
| 8 | <schema name=”DB01” |
| 9 | <table |
| 10 | </schema> |
| 11 | </privileges> |
| 12 | –> |
| 13 | </user> |
3.5.2.4 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
| 1 | CREATE TABLE tb_log ( |
|---|---|
| 2 | id bigint(20) NOT NULL COMMENT ‘ID’, |
| 3 | model_name varchar(200) DEFAULT NULL COMMENT ‘模块名’, |
| 4 | model_value varchar(200) DEFAULT NULL COMMENT ‘模块值’, |
| 5 | return_value varchar(200) DEFAULT NULL COMMENT ‘返回值’, |
| 6 | return_class varchar(200) DEFAULT NULL COMMENT ‘返回值类型’, |
| 7 | operate_user varchar(20) DEFAULT NULL COMMENT ‘操作用户’, |
| 8 | operate_time varchar(20) DEFAULT NULL COMMENT ‘操作时间’, |
| 9 | param_and_value varchar(500) DEFAULT NULL COMMENT ‘请求参数名及参数值’, |
| 10 | operate_class varchar(200) DEFAULT NULL COMMENT ‘操作类’, |
| 11 | operate_method varchar(200) DEFAULT NULL COMMENT ‘操作方法’, |
| 12 | cost_time bigint(20) DEFAULT NULL COMMENT ‘执行方法耗时, 单位 ms’, |
| 13 | source int(1) DEFAULT NULL COMMENT ‘来源 : 1 PC , 2 Android , 3 IOS’, |
| 14 | PRIMARY KEY (id) |
| 15 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; |
| 16 |
17INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source)
VALUES(‘1’,’user’,’insert’,’success’,’java.lang.String’,’10001’,’2022-01-06 18:12:28’,${ \vert ^ { n } a g e \vert ^ { n } : \vert ^ { n } 2 0 \vert ^ { n } , \vert ^ { n } n a$me":"Tom","gender":"1"}’,’cn.itcast.contro ller.UserController’,’insert’,’10’,1);
18INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source)
VALUES(‘2’,’user’,’insert’,’success’,’java.lang.String’,’10001’,’2022-01-06 18:12:27”,”{|”a9e|”:|”20|”,|”name|”:|”TOm|”,|”gender":"1"}’,’cn.itcast.contro ller.UserController’,’insert’,⋅23⋅2);
19INSERT INTO tb10g(id, model_name, model_value, return_value, return_class,operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source)
VALUES(‘3’,’user’,’update’,’success’,’java.lang.String’,’10001’,’2022-01-06 18:16:45’,${ \vert ^ { \prime \prime } d g e \vert ^ { n } : \vert ^ { n } 2 0 \vert ^ { n } , \vert ^ { n } n a m e \vert ^ { n } : \vert ^ { n } T o n \vert ^ { n } , \vert ^ { n } g e$nder":"1"}’,’cn.itcast.contro ller.UserController’,’update’,’34’,1);
20INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source)
VALUES(‘4’,’user’,’update’,’success’,’java.lang.String’,’10001’,’2022-01-06 $1 8 : 1 6 : 4 5 ‘ , ‘ { 1 ^ { \prime \prime } a g e \vert “ : \vert ^ { \prime \prime } 2 0 \vert “ , \vert “ n a$me":"Tom∖”,∖”gender":"1"}’,’cn.itcast.contro ller.UserController’,’update’,$1 3 ^ { * } , 2 )$;
21INSERT INTO tb⊥oq (id, model_name, model_value, return_value, return_class,operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source)
VALUES(‘5’,’user’,’insert’,’success’,’java.lang.String’,’10001’,’2022-01-06 $1 8 : 3 0 : 3 1 “ , “ { \vert ^ { \prime \prime } a g e \vert ^ { \prime \prime } : \vert ^ { \prime \prime } 2 0 0 \vert ^ { \prime \prime \prime } , \vert ^ { \prime \prime } n _ {$me":"Tom$c a t \setminus ^ { n } , \vert ^ { n } g e r$nder":"0"}’,’cn.itcast.co ntroller.UserController’,’insert’,’29’,3);
22INSERT INTO tb⊥oq (id, model_name, model_value, return_value, return_class,operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source)
VALUES(‘6’,’user’,’find’,’success’,’java.lang.String’,’10001’,’2022-01-06
$1 8 : 3 0 : 3 1 ^ { \prime } , ^ { \prime } { \vert ^ { \prime \prime } d g e } ^ { \prime \prime } : \vert ^ { \prime \prime } 2 0 0 \vert ^ { \prime \prime } r ^ { \prime \prime } n a m e } ^ { \prime \prime } : \vert ^ { \prime \prime } T O m C$at","gender":"0"}’,’cn.itcast.co ntroller.UserController’,’find’,’29’,2);
3.5.3 分片规则
3.5.3.1 范围分片
1). 介绍
根据指定的字段及其配置的范围与数据节点的对应情况, 来决定该数据属于哪一个分片。

2). 配置
schema.xml逻辑表配置:
1 <tab1e$n a m e = “ T B O R D E R ^ { n }$detaNode=”dn1,dn2,$a n 3 ^ { n }$ $r u l e = ^ { w } a u t o - s h a r d \in g - 1 o n g ^ { \prime \prime }$/>
schema.xml数据节点配置:
1<dataNode name=”dn1” dataHost=”dhost1” database=”db01” 1>
2<dataNode name=”dn2” $d a t a H o s t = ^ { n } d h o s t 2 ^ { n }$ $d a t a b a s e = ^ { n } d b 0 1 ^ { n }$ />
3<dataNode name=”dn3” $d a t a H o s t = ^ { n } d h o s t 3 ^ { n }$ $d a t a b a s e = ^ { n } d b 0 1 ^ { n }$ />
rule.xml分片规则配置:
| 1 | <tableRule name=”auto-sharding-long”> |
|---|---|
| 2 | <rule> |
| 3 | <columns>id</columns> |
| 4 | <algorithm>rang-long</algorithm> |
| 5 | </rule> |
| 6 | </tableRule> |
| 7 | |
| 8 | <function name=”rang-long” .mycat.route.function.AutoPartitionByLong”> |
| 9 | <property name=”mapFile”>autopartition-long.txt</property> |
| 10 | <property name=”defaultNod |
| 11 | </function> |
分片规则配置属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为0 ; 0 表示Integer , 1 表示String |
| defaultNode | 默认节点 默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。 |
在rule.xml中配置分片规则时,关联了一个映射配置文件 autopartition-long.txt,该配置文件的配置如下:
| 1 | # range start-end ,data node index |
|---|---|
| 2 | # |
| 3 | |
| 4 | 500M-1000M=1 |
| 5 | 1000M-1500M=2 |
含义:0-500万之间的值,存储在0号数据节点(数据节点的索引从0开始) ; 500万-1000万之间的数据存储在1号数据节点 ; 1000万-1500万的数据节点存储在2号节点 ;
该分片规则,主要是针对于数字类型的字段适用。 在MyCat的入门程序中,我们使用的就是该分片规则。
3.5.3.2 取模分片
1). 介绍
根据指定的字段值与节点数量进行求模运算,根据运算结果, 来决定该数据属于哪一个分片。

2). 配置
schema.xml逻辑表配置:
1<tablename=”七b109” $d a t a N c d e = ^ { n } c \in 4 ,$,dn5,dn6” primaryKey=”id” $r u l e = ^ { n } m o d - 1 o n g ^ { n }$/>
schema.xml数据节点配置:
1<dataNode name=”dn4” $d a t a H o s t = ^ { n } d h o s t 1 ^ { n }$ $d a t a b a s e = ^ { n } 让 c a s t ^ { n }$ />
2<dataNode name=”dn5” $d a t a H o s t = ^ { n } c h o s t 2 ^ { n }$ $d a t a b a s e = ^ { n } 让 c a s t ^ { n }$ />
3<dataNode name=”dn6” $d a t a H o s t = ^ { n } d h o s t 3 ^ { n }$ $d a t a b a s e = ^ { n } 让 c a s t ^ { n }$ />
rule.xml分片规则配置:
| 1 | <tableRule name=”mod-long”> |
|---|---|
| 2 | <rule> |
| 3 | <columns>id</columns> |
| 4 | <algorithm>mod-long</algorithm> |
| 5 | </rule> |
| 6 | </tableRule> |
| 7 | |
| 8 | <function name=”mod-long” .mycat.route.function.PartitionByMod”> |
| 9 | <property |
| 10 | </function> |
分片规则属性说明如下:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| count | 数据节点的数量 |
该分片规则,主要是针对于数字类型的字段适用。 在前面水平拆分的演示中,我们选择的就是取模分片。
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
3.5.3.3 一致性hash分片
1). 介绍
所谓一致性哈希,相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置,有效的解决了分布式数据的拓容问题。

2).配置
schema.xml中逻辑表配置:
1 <1–致性hash–>
2 <table$n a m e = “ t b O r d e r ^ { n }$dataNode=”dn4,,dn5$d n 6 ^ { n }$ $x u l e = ^ { n } s h a x d i n g - b y - m u x m u x ^ { n }$
schema.xml中数据节点配置:
1 <dataNodename=”dn4”$d a t a H O s t = n c h o s t 1 ^ { \prime \prime }$database=”itcast”/>
2 <dataNodename=”dn5”$d a t a H o s t = ^ { n } d h o s t 2 ^ { n }$database=”itcast”
3 <dataNodename=”dn6”$d a t a H o s t = n c h o s t 3 ^ { \prime \prime }$database=”1tcast”
rule.xml中分片规则配置:
| 1 | <tableRule name=”sharding-by-murmur”> |
|---|---|
| 2 | <rule> |
| 3 | <columns>id</columns> |
| 4 | <algorithm>murmur</algorithm> |
| 5 | </rule> |
| 6 | </tableRule> |
| 7 | |
| 8 | <function name=”murmur” .mycat.route.function.PartitionByMurmurHash”> |
| 9 | <property 默认是0 –> |
| 10 | <property |
| 11 | <property name=”virtualBucketTimes”>160</property> |
| 12 | </function> |
分片规则属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| seed | 创建murmur_hash对象的种子,默认0 |
| count | 要分片的数据库节点数量,必须指定,否则没法分片 |
| virtualBucketTimes | 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍;virtualBucketTimes*count就是虚拟结点数量 ; |
| weightMapFile | 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 |
| bucketMapPath | 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 |
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
1 create table tb_order(
2 id varchar(100) not null primary key,
3 money int null,
4 content varchar(200) null
5);
6
7INSERT INTO tb_order (id, money, content) VALUES (‘b92fdaaf-6fc4-11ec-b831-482ae33c4a2d’, 10, ‘b92fdaf8-6fc4-11ec-b831-482ae33c4a2d’);
8INSERT INTO tb_order (id, money, content) VALUES (‘b93482b6-6fc4-11ec-b831-482ae33c4a2d’, 20, ‘b93482d5-6fc4-11ec-b831-482ae33c4a2d’);
9INSERT INTO tb_order (id, money, content) VALUES (‘b937e246-6fc4-11ec-b831-482ae33c4a2d’, 50, ‘b937e25d-6fc4-11ec-b831-482ae33c4a2d’);
10INSERT INTO tb_order (id, money, content) VALUES (‘b93be2dd-6fc4-11ec-b831-482ae33c4a2d’, 100, ‘b93be2f9-6fc4-11ec-b831-482ae33c4a2d’);
11INSERT INTO tb_order (id, money, content) VALUES (‘b93f2d68-6fc4-11ec-b831-482ae33c4a2d’, 130, ‘b93f2d7d-6fc4-11ec-b831-482ae33c4a2d’);
12INSERT INTO tb_order (id, money, content) VALUES (‘b9451b98-6fc4-11ec-b831-482ae33c4a2d’, 30, ‘b9451bcc-6fc4-11ec-b831-482ae33c4a2d’);
13INSERT INTO tb_order (id, money, content) VALUES (‘b9488ec1-6fc4-11ec-b831-482ae33c4a2d’, 560, ‘b9488edb-6fc4-11ec-b831-482ae33c4a2d’);
14INSERT INTO tb_order (id, money, content) VALUES (‘b94be6e6-6fc4-11ec-b831-482ae33c4a2d’, 10, ‘b94be6ff-6fc4-11ec-b831-482ae33c4a2d’);
15INSERT INTO tb_order (id, money, content) VALUES (‘b94ee10d-6fc4-11ec-b831-482ae33c4a2d’, 123, ‘b94ee12c-6fc4-11ec-b831-482ae33c4a2d’);
16INSERT INTO tb_order (id, money, content) VALUES (‘b952492a-6fc4-11ec-b831-482ae33c4a2d’, 145, ‘b9524945-6fc4-11ec-b831-482ae33c4a2d’);
17INSERT INTO tb_order (id, money, content) VALUES (‘b95553ac-6fc4-11ec-b831-482ae33c4a2d’, 543, ‘b95553c8-6fc4-11ec-b831-482ae33c4a2d’);
18INSERT INTO tb_order (id, money, content) VALUES (‘b9581cdd-6fc4-11ec-b831-482ae33c4a2d’, 17, ‘b9581cfa-6fc4-11ec-b831-482ae33c4a2d’);
19INSERT INTO tb_order (id, money, content) VALUES (‘b95afc0f-6fc4-11ec-b831-482ae33c4a2d’, 18, ‘b95afc2a-6fc4-11ec-b831-482ae33c4a2d’);
20INSERT INTO tb_order (id, money, content) VALUES (‘b95daa99-6fc4-11ec-b831-482ae33c4a2d’, 134, ‘b95daab2-6fc4-11ec-b831-482ae33c4a2d’);
| 21 | INSERT INTO tb_order (id, money, content) VALUES (‘b9667e3c-6fc4-11ec-b831- |
|---|---|
| 22 | 482ae33c4a2d’, 156, ‘b9667e60-6fc4-11ec-b831-482ae33c4a2d’);INSERT INTO tb_order (id, money, content) VALUES (‘b96ab489-6fc4-11ec-b831- |
| 22 | 482ae33c4a2d’, 175, ‘b96ab4a5-6fc4-11ec-b831-482ae33c4a2d’); |
| 23 | INSERT INTO tb_order (id, money, content) VALUES (‘b96e2942-6fc4-11ec-b831- |
| 23 | 482ae33c4a2d’, 180, ‘b96e295b-6fc4-11ec-b831-482ae33c4a2d’); |
| 24 | INSERT INTO tb_order (id, money, content) VALUES (‘b97092ec-6fc4-11ec-b831- |
| 24 | 482ae33c4a2d’, 123, ‘b9709306-6fc4-11ec-b831-482ae33c4a2d’); |
| 25 | INSERT INTO tb_order (id, money, content) VALUES (‘b973727a-6fc4-11ec-b831- |
| 25 | 482ae33c4a2d’, 230, ‘b9737293-6fc4-11ec-b831-482ae33c4a2d’); |
| 26 | INSERT INTO tb_order (id, money, content) VALUES (‘b978840f-6fc4-11ec-b831- |
| 26 | 482ae33c4a2d’, 560, ‘b978843c-6fc4-11ec-b831-482ae33c4a2d’); |
3.5.3.4 枚举分片
1). 介绍
通过在配置文件中配置可能的枚举值, 指定数据分布到不同数据节点上, 本规则适用于按照省份、性别、状态拆分数据等业务 。

2). 配置
schema.xml中逻辑表配置:
| 1<!– 枚举 –> | 1<!– 枚举 –> |
|---|---|
| 2 | sharding-by-intfile-enumstatus” |
| /> |
schema.xml中数据节点配置:
1<dataNode name=”dn4” dataHost=”dhost1” database=”itcast”/>
2<dataNode name=”dn5” $d a t a H o s t = ^ { n } d h o s t 2 ^ { n }$ database=”itcast”/>
3<dataNode name=”dn6” dataHost=”dhost3” detabase=”itcast” />
rule.xml中分片规则配置:
| 1 | <tableRule |
|---|---|
| 2 | |
| 3 | <columns>sharding_id</columns> |
| 4 | <algorithm>hash-int</algorithm> |
| 5 | </rule> |
| 6 | </tableRule> |
| 7 | |
| 8 | <!– 自己增加 tableRule –> |
| 9 | <tableRule name=”sharding-by-intfile-enumstatus”> |
| 10 | <rule> |
| 11 | <columns>status</columns> |
| 12 | <algorithm>hash-int</algorithm> |
| 13 | </rule> |
| 14 | </tableRule> |
| 15 | |
| 16 | <function .mycat.route.function.PartitionByFileMap”> |
| 17 | <property name=”defaultNode”>2</property> |
| 18 | <property name=”mapFile”>partition-hash-int.txt</property> |
| 19 | </function> |
partition-hash-int.txt ,内容如下 :
| 1 |
|---|
| 2 |
| 3 |
分片规则属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为0 ; 0 表示Integer , 1 表示String |
| defaultNode | 默认节点 ; 小于0 标识不设置默认节点 , 大于等于0代表设置默认节点 ;默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。 |
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
| 1 | CREATE TABLE ( |
|---|---|
| 2 | id bigint(20) NOT NULL COMMENT ‘ID’, |
| 3 | username varchar(200) DEFAULT NULL COMMENT ‘姓名’, |
| 4 | status int(2) DEFAULT ‘1’ COMMENT ‘1: 未启用, 2: 已启用, 3: 已关闭’, |
| 5 | PRIMARY KEY (id) |
| 6 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; |
| 7 | |
| 8 | |
| 9 | insert into tb_user (id,username ,status) values(1,’Tom’,1); |
| 10 | insert into tb_user (id,username ,status) values(2,’Cat’,2); |
| 11 | insert into tb_user (id,username ,status) values(3,’Rose’,3); |
| 12 | insert into tb_user (id,username ,status) values(4,’Coco’,2); |
| 13 | insert into tb_user (id,username ,status) values(5,’Lily’,1); |
| 14 | insert into tb_user | (id,username ,status | ) values(6,’Tom’,1); |
|---|---|---|---|
| 15 | insert into tb_user | (id,username ,status | ) values(7,’Cat’,2); |
| 16 | insert into tb_user (id,username ,status | insert into tb_user (id,username ,status | ) values(8,’Rose’,3) |
| 17 | insert into tb_user (id,username ,status | insert into tb_user (id,username ,status | ) values(9,’Coco’,2) |
| 18 | insert into tb_user | (id,username ,status | ) values(10,’Lily’,1 |
3.5.3.5 应用指定算法
1). 介绍
运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号。

2). 配置
schema.xml中逻辑表配置:
1 <!– 应用指定算法 –>
2 <table$n a m e = “ 七 b \underline { } a p p ^ { \prime \prime }$dataNcde=”dn4,dn5,dn6” $r u 1 e = ^ { u } s$harding-by-substring” />
schema.xml中数据节点配置:
1<dataNode name=”dn4” dataHost=”dhost1” $d a t a b a s e = ^ { n } \bot t \cos t ^ { n }$ />
2<dataNode name=”dn5” $d a t a H o s t = ^ { n } d h o s t 2 ^ { n }$ database=”itcast”/>
3<dataNode name=”dn6” $d a t a H o s t = ^ { n } d h o s t 3 ^ { n }$ $d a t a b a s e = ^ { n } \bot t \cos t ^ { n }$ />
rule.xml中分片规则配置:
| 1 | <tableRule name=”sharding-by-substring”> |
|---|---|
| 2 | <rule> |
| 3 | <columns>id</columns> |
| 4 | <algorithm>sharding-by-substring</algorithm> |
| 5 | |
| 6 | </tableRule> |
| 7 | |
| 8 | <function name=”sharding-by-substring” |
| .mycat.route.function.PartitionDirectBySubString”> | |
| 9 | <property <!– zero-based –> |
| 10 | <property |
| 11 | <property |
| 12 | <property name=”defaultPartition”>0</property> |
| 13 | </function> |
分片规则属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| startIndex | 字符子串起始索引 |
| size | 字符长度 |
| partitionCount | 分区(分片)数量 |
| defaultPartition | 默认分片(在分片数量定义时, 字符标示的分片编号不在分片数量内时,使用默认分片) |
示例说明 :
id=05-100000002 , 在此配置中代表根据id中从 startIndex=0,开始,截取Siz=2位数字即05,05就是获取的分区,如果没找到对应的分片则默认分配到defaultPartition 。
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
| 1 | CREATE TABLE ( |
|---|---|
| 2 | id varchar(10) NOT NULL COMMENT ‘ID’, |
| 3 | name varchar(200) DEFAULT NULL COMMENT ‘名称’, |
| 4 | PRIMARY KEY (id) |
| 5 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; |
| 6 | |
| 7 | insert into tb_app (id,name) values(‘0000001’,’Testx00001’); |
| 8 | insert into tb_app (id,name) values(‘0100001’,’Test100001’); |
| 9 | insert into tb_app (id,name) values(‘0100002’,’Test200001’); |
| 10 | insert into tb_app (id,name) values(‘0200001’,’Test300001’); |
| 11 | insert into tb_app (id,name) values(‘0200002’,’TesT400001’); |
3.5.3.6 固定分片hash算法
1). 介绍
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十进制,也就是位于0-1023之间。

特点:
如果是求模,连续的值,分别分配到各个不同的分片;但是此算法会将连续的值可能分配到相同的分片,降低事务处理的难度。
可以均匀分配,也可以非均匀分配。
分片字段必须为数字类型。
2). 配置
schema.xml中逻辑表配置:
1 <!– 固定分片hash算法 –>
2 <table$n a m e = “ t b 1 o n g h a s h ^ { \prime \prime }$dataNode=nan4,dn5,dn6” rule=”sharding-by-long-hash” />
schema.xml中数据节点配置:
1<dataNode name=”dn4” $d a t a H o s t = ^ { n } d h o s t 1 ^ { n }$ $d a t a b a s e = ^ { n } 让 c a s t ^ { n }$ />
2<dataNode name=”dn5” dataHost=”dhost2” $d a t a b a s e = ^ { n } 让 c a s t ^ { n }$ />
3<dataNode name=”dn6” dataHost=”dhost3” detabase=”itcast” />
rule.xml中分片规则配置:
| 1 | <tableRule name=”sharding-by-long-hash”> |
|---|---|
| 2 | <rule> |
| 3 | <columns>id</columns> |
| 4 | <algorithm>sharding-by-long-hash</algorithm> |
| 5 | </rule> |
| 6 | </tableRule> |
| 7 | |
| 8 | <!– 分片总长度为1024,count与length数组长度必须一致; –> |
| 9 | <function |
| .mycat.route.function.PartitionByLong”> | |
| 10 | <property name=”partitionCou 1</property> |
| 11 | <property name=”partitionLength”>256,512</property> |
| 12 | </function> |
分片规则属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段名 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| partitionCount | 分片个数列表 |
| partitionLength | 分片范围列表 |
约束 :
1). 分片长度 : 默认最大2^10 , 为 1024 ;
2). count, length的数组长度必须是一致的 ;
以上分为三个分区:0-255,256-511,512-1023
示例说明 :
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
| 1 | CREATE TABLE tb_longhash ( | CREATE TABLE tb_longhash ( | |
|---|---|---|---|
| 2 | id int(11) NOT NULL COMMENT ‘ID’, | id int(11) NOT NULL COMMENT ‘ID’, | |
| 3 | name varchar(200) DEFAULT NULL COMMENT ‘ | name varchar(200) DEFAULT NULL COMMENT ‘ | 名称’, |
| 4 | firstChar char(1) COMMENT ‘首字母’, | firstChar char(1) COMMENT ‘首字母’, | |
| 5 | PRIMARY KEY (id) |
PRIMARY KEY (id) |
|
| 6 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; | |
| 7 | |||
| 8 | insert into tb_longh | ash (id,name,firstChar) | values(1,’七匹狼’,’Q’) |
| 9 | insert into tb_longh | ash (id,name,firstChar) | values(2,’八匹狼’,’B’) |
| 10 | insert into tb_longh | ash (id,name,firstChar) | values(3,’九匹狼’,’J’) |
| 11 | insert into tb_longh | ash (id,name,firstChar) | values(4,’十匹狼’,’S’) |
| 12 | insert into tb_longh | ash (id,name,firstChar) | values(5,’六匹狼’,’L’) |
| 13 | insert into tb_longh | ash (id,name,firstChar) | values(6,’五匹狼’,’W’) |
| 14 | insert into tb_longh | ash (id,name,firstChar) | values ‘四匹狼’,’S’) |
| 15 | insert into tb_longh | ash (id,name,firstChar) | values(8,’三匹狼’,’S’) |
| 16 | insert into tb_longh | ash (id,name,firstChar) | values(9,’两匹狼’,’L’) |
3.5.3.7 字符串hash解析算法
1). 介绍
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片。

2). 配置
schema.xml中逻辑表配置:
1 <!– 字符串hash解析算法 –>
2 <table$n a m e = “ 七 b s t r h a s h ^ { n }$dataNode=”dn4,dn5” ru1e=”sharding-by-stringhash”
schema.xml中数据节点配置:
1<dataNode name=”dn4” $d a t a H o s t = ^ { n } d h o s t 1 ^ { n }$ $d a t a b a s e = n i t c a s t ^ { n }$ />
2<dataNode name=”dn5” $d a t a H o s t = ^ { n } d h o s t 2 ^ { n }$ $d a t a b a s e = ^ { n } 让 c a s t ^ { n }$ />
rule.xml中分片规则配置:
| 1 | <tableRule name=”sharding-by-stringhash”> |
|---|---|
| 2 | <rule> |
| 3 | <columns>name</columns> |
| 4 | <algorithm>sharding-by-stringhash</algorithm> |
| 5 | |
| 6 | </tableRule> |
| 7 | |
| 8 | <function na harding-by-stringhash” |
| .mycat.route.function.PartitionByString”> | |
| 9 | <property name=”partitionLength”>512</property> <!– zero-based –> |
| 10 | <property name=”partitionCount”>2</property> |
| 11 | <property |
| 12 | </function> |
分片规则属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| partitionLength | hash求模基数 ; length*count=1024 (出于性能考虑) |
| partitionCount | 分区数 |
| hashSlice | hash运算位 , 根据子字符串的hash运算 ; 0 代表 str.length(), -1 代表 str.length()-1 , 大于0只代表数字自身 ; 可以理解为substring(start,end),start为0则只表示0 |
示例说明:

3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
| 1 | create table tb_strhash( | create table tb_strhash( | |
|---|---|---|---|
| 2 | name varchar(20) primary key, | name varchar(20) primary key, | |
| 3 | content varchar(100) | content varchar(100) | |
| 4 | )engine=InnoDB DEFAULT CHARSET=utf8mb4; | )engine=InnoDB DEFAULT CHARSET=utf8mb4; | |
| 5 | |||
| 6 | INSERT INTO tb_strha | sh (name,content) VALU | ES(‘T1001’, UUID()); |
| 7 | INSERT INTO tb_strha | sh (name,content) VALU | ES(‘ROSE’, UUID()); |
| 8 | INSERT INTO tb_strha | sh (name,content) VALU | ES(‘JERRY’, UUID()); |
| 9 | INSERT INTO tb_strha | sh (name,content) VALU | ES(‘CRISTINA’, UUID()); |
| 10 | INSERT INTO tb_strha | sh (name,content) VALU | ES(‘TOMCAT’, UUID()); |
3.5.3.8 按天分片算法
1). 介绍
按照日期及对应的时间周期来分片。

2). 配置
schema.xml中逻辑表配置:
1 <!– 按天分片 –>
2 <tab1e$n a m e = “ 七 b \underline { } c$atepart” $d a t a N o d e = ^ { n } d n 4$,dn5,dn6” rule=”sharding-by-date” />
schema.xml中数据节点配置:
1<dataNode name=”dn4” $d a t a H O s t = n c h o s t 1 ^ { n }$ database=”itcast”/>
2<dataNode name=”an5” dataHost=”dhost2” database=”itcast”/>
3<dataNode name=”dn6” $d a t a H O s t = ^ { n } d h o s t 3 ^ { n }$ $d a t a b a s e = n i t c a s t ^ { n }$
rule.xml中分片规则配置:
1<tableRule$n a m e = ^ { n } s h a r d \in g - b y - d a t e ^ { n } >$
2 <rule>
3 <columns>create_time</columns>
4 <algorithm>sharding-by-date</algorithm>
5 </rule>
6</tableRule>
7
| 8 | <function name=” class=”io.mycat.route.function.PartitionByDate”> |
|---|---|
| 9 | <property |
| 10 | <property |
| 11 | <property |
| 12 | <property PartionDay”>10</property> |
| 13 | </function> |
| 14 | |
| 15 | 从开始时间开始,每10天为一个分片,到达结束时间之后,会重复开始分片插入 |
| 16 | 配置表的 dataNode 的分片,必须和分片规则数量一致,例如 2022-01-01 到 2022-12-31 ,每10天一个分片,一共需要37个分片。 |
| 17 | –> |
分片规则属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| dateFormat | 日期格式 |
| sBeginDate | 开始日期 |
| sEndDate | 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入 |
| sPartionDay | 分区天数,默认值 10 ,从开始日期算起,每个10天一个分区 |
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
| 1 | create table tb_datepart( | create table tb_datepart( | |
|---|---|---|---|
| 2 | id bigint not null comment ‘ID’ primary ke | id bigint not null comment ‘ID’ primary ke | y, |
| 3 | name varchar(100) nu | ll comment ‘姓名’, | |
| 4 | create_time date null | create_time date null | |
| 5 | ); | ); | |
| 6 | |||
| 7 | insert into tb_datepart( | id,name ,create_time) valu | es(1,’Tom’,’2022-01-01’); |
| 8 | insert into tb_datepart( | id,name ,create_time) valu | es(2,’Cat’,’2022-01-10’); |
| 9 | insert into tb_datepart( | id,name ,create_time) valu | es(3,’Rose’,’2022-01-11’); |
| 10 | insert into tb_datepart( | id,name ,create_time) valu | es(4,’Coco’,’2022-01-20’); |
| 11 | insert into tb_datepart(id,name ,create_time) valu | insert into tb_datepart(id,name ,create_time) valu | es(5,’Rose2’,’2022-01-21’); |
| 12 | insert into tb_datepart( | id,name ,create_time) valu | es(6,’Coco2’,’2022-01-30’); |
| 13 | insert into tb_datepart( | id,name ,create_time) valu | es(7,’Coco3’,’2022-01-31’); |
3.5.3.9 自然月分片
1). 介绍
使用场景为按照月份来分片, 每个自然月为一个分片。

2). 配置
schema.xml中逻辑表配置:
1 <!– 按自然月分片 –>
2 <tab1ename=”七bmonthpart” $d a t a N o d e = ^ { n } d n 4$,dn5,dn6” $r u 1 e = ^ { n }$sharding-by-month” />
schema.xml中数据节点配置:
1<dataNode name=”dn4” $d a t a H O s t = ^ { n } d h o s t 1 ^ { n }$ $d a t a b a s e = ^ { n } \bot t c a s t ^ { n }$
2 <dataNode name=”an5” dataHost=”dhost2” database=”1tcast”
3<dataNode name=”dn6” $d a t a H O s t = ^ { n } d h o s t 3 ^ { n }$ database=”1tcast”
rule.xml中分片规则配置:
| 1 | <tableRule |
|---|---|
| 2 | <rule> |
| 3 | <columns>create_time</columns> |
| 4 | <algorithm>partbymonth</algorithm> |
| 5 | </rule> |
| 6 | </tableRule> |
| 7 | |
| 8 | <function name=”partbymonth” .mycat.route.function.PartitionByMonth”> |
| 9 | <property |
| 10 | |
| 11 | <property |
| 12 | </function> |
| 13 | <!– |
| 14 | 从开始时间开始,一个月为一个分片,到达结束时间之后,会重复开始分片插入 |
| 15 | 配置表的 dataNode 的分片,必须和分片规则数量一致,例如 2022-01-01 到 2022-12-31 ,一 |
| 共需要12个分片。 | 共需要12个分片。 |
| 16 | –> |
分片规则属性含义:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| dateFormat | 日期格式 |
| sBeginDate | 开始日期 |
| sEndDate | 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入 |
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
| 1 | create table tb_monthpart( | create table tb_monthpart( | create table tb_monthpart( |
|---|---|---|---|
| 2 | id bigint not null comment | ‘ID’ primary key, | |
| 3 | name varchar(100) null commen | t ‘姓名’, | |
| 4 | create_time date null | create_time date null | |
| 5 | ); | ); | |
| 6 | |||
| 7 | ins | ert into tb_monthpart(id,name | ,create_time) values(1,’Tom’,’2022-01-01’); |
| 8 | ins | ert into tb_monthpart(id,name | ,create_time) values(2,’Cat’,’2022-01-10’); |
| 9 | ins | ert into tb_monthpart(id,name | ,create_time) values(3,’Rose’,’2022-01-31’); |
| 10 | ins | ert into tb_monthpart(id,name | ,create_time) values(4,’Coco’,’2022-02-20’); |
| 11 | ins | ert into tb_monthpart(id,name | ,create_time) values(5,’Rose2’,’2022-02-25’) |
| 12 | ins | ert into tb_monthpart(id,name | ,create_time) values(6,’Coco2’,’2022-03-10’) |
| 13 | ins | ert into tb_monthpart(id,name | ,create_time) values(7,’Coco3’,’2022-03-31’) |
| 14 | ins | ert into tb_monthpart(id,name | ,create_time) values(8,’Coco4’,’2022-04-10’) |
| 15 | ins | ert into tb_monthpart(id,name | ,create_time) values(9,’Coco5’,’2022-04-30’) |
3.6 MyCat管理及监控

在MyCat中,当执行一条SQL语句时,MyCat需要进行SQL解析、分片分析、路由分析、读写分离分析等操作,最终经过一系列的分析决定将当前的SQL语句到底路由到那几个(或哪一个)节点数据库,数据库将数据执行完毕后,如果有返回的结果,则将结果返回给MyCat,最终还需要在MyCat中进行结果合并、聚合处理、排序处理、分页处理等操作,最终再将结果返回给客户端。
而在MyCat的使用过程中,MyCat官方也提供了一个管理监控平台MyCat-Web(MyCat-eye)
Mycat-web 是 Mycat 可视化运维的管理和监控平台,弥补了 Mycat 在监控上的空白。帮 Mycat 分担统计任务和配置管理任务。Mycat-web 引入了 ZooKeeper 作为配置中心,可以管理多个节点。Mycat-web 主要管理和监控 Mycat 的流量、连接、活动线程和内存等,具备 IP 白名单、邮件告警等模块,还可以统计 SQL 并分析慢 SQL 和高频 SQL 等。为优化 SQL 提供依据。
3.6.2 MyCat管理
Mycat默认开通2个端口,可以在server.xml中进行修改。
8066 数据访问端口,即进行 DML 和 DDL 操作。
9066 数据库管理端口,即 mycat 服务管理控制功能,用于管理mycat的整个集群状态
连接MyCat的管理控制台:
| 1 | mysql | -h | 192.168.200.210 - | p 9066 | -uroot | -p123456 |
|---|
| 命令 | 含义 |
|---|---|
| show @@help | 查看Mycat管理工具帮助文档 |
| show @@version | 查看Mycat的版本 |
| reload @@config | 重新加载Mycat的配置文件 |
| show @@datasource | 查看Mycat的数据源信息 |
| show @@datanode | 查看MyCat现有的分片节点信息 |
| show @@threadpool | 查看Mycat的线程池信息 |
| show @@sql | 查看执行的SQL |
| show @@sql.sum | 查看执行的SQL统计 |
3.6.3 MyCat-eye
3.6.3.1 介绍
Mycat-web(Mycat-eye)是对mycat-server提供监控服务,功能不局限于对mycat-server使用。他通过JDBC连接对Mycat、Mysql监控,监控远程服务器(目前仅限于linux系统)的cpu、内存、网络、磁盘。
Mycat-eye运行过程中需要依赖zookeeper,因此需要先安装zookeeper。
3.6.3.2 安装
1). zookeeper安装
2). Mycat-web安装
具体的安装步骤,请参考资料中提供的《MyCat-Web安装文档》
3.6.3.3 访问
http://192.168.200.210:8082/mycat
| Mycat-eye | |
|---|---|
| 志 | |
| Myct | |
| Myct控 | |
| SC-1 | |
| SC- | |
| Mycat Zone |
3.6.3.4 配置
1).开启MyCat的实时统计功能(server.xml)
1 <property name="usesqlStat">1</property><!–1为开启实时统计、0为关闭–>
2).在Mycat监控界面配置服务地址
| Mycat-eye | ||
|---|---|---|
| 保签单 | Mycat配置管理 | Mycat理:Procedare-Poceduycen |
| Mat道 | Mycat配置管理 | |
| 服管理 | ||
| OmycV理 | Mycat名(必为文): | |
| Om | Mycat0l | |
| Om系数 | I地址 | |
| 白名单 | 192,168,200.210 | |
| Omyca日理 | 管理口: | |
| 邮督 | 9066 | |
| Mycat监腔 | 服务口: | |
| SCL-控 | 8066 | |
| ISCL-上EE | 票据用名: | |
| Mycat Zone | IICAST | |
| 用户: | ||
| Fo0t | ||
| 密码: |
3.6.3.5 测试
配置好了之后,我们可以通过MyCat执行一系列的增删改查的测试,然后过一段时间之后,打开mycat-eye的管理界面,查看mycat-eye监控到的数据信息。
A.性能监控

B.物理节点

c.SQL统计

| Mycat-eye - | Mycat-eye - | Mycat-eye - | Mycat-eye - | Mycat-eye - |
|---|---|---|---|---|
| 导单 SQL表分析 -50Mycat-五 | 导单 SQL表分析 -50Mycat-五 | 导单 SQL表分析 -50Mycat-五 | 导单 SQL表分析 -50Mycat-五 | 导单 SQL表分析 -50Mycat-五 |
| 查询件:Mycat控 Mycat01 | 区查称 | 区查称 | 区查称 | |
| 查询件:Mycat控 Mycat01 | 2022-01-06 00:00-2022-01-06 22.56 | |||
| S-控 | ||||
| O S 查询 重置OSO析O SCL控 지 票日 지 票日 지 지 日tb_apP ⑳국 tb_datepart tb_longhash – tb_orderO ASQLOO SOSQU上 SCU型Mycat Zone 写:66667%⑲국 tb_strhash쪽 日 | O S 查询 重置OSO析O SCL控 지 票日 지 票日 지 지 日tb_apP ⑳국 tb_datepart tb_longhash – tb_orderO ASQLOO SOSQU上 SCU型Mycat Zone 写:66667%⑲국 tb_strhash쪽 日 | O S 查询 重置OSO析O SCL控 지 票日 지 票日 지 지 日tb_apP ⑳국 tb_datepart tb_longhash – tb_orderO ASQLOO SOSQU上 SCU型Mycat Zone 写:66667%⑲국 tb_strhash쪽 日 | O S 查询 重置OSO析O SCL控 지 票日 지 票日 지 지 日tb_apP ⑳국 tb_datepart tb_longhash – tb_orderO ASQLOO SOSQU上 SCU型Mycat Zone 写:66667%⑲국 tb_strhash쪽 日 | O S 查询 重置OSO析O SCL控 지 票日 지 票日 지 지 日tb_apP ⑳국 tb_datepart tb_longhash – tb_orderO ASQLOO SOSQU上 SCU型Mycat Zone 写:66667%⑲국 tb_strhash쪽 日 |
E. SQL监控
| Mycat-eye | = | = | = | = | = | |||
|---|---|---|---|---|---|---|---|---|
| SQL监控 SCN-SOLM | SQL监控 SCN-SOLM | SQL监控 SCN-SOLM | SQL监控 SCN-SOLM | SQL监控 SCN-SOLM | SQL监控 SCN-SOLM | SQL监控 SCN-SOLM | SQL监控 SCN-SOLM | |
| I Mycal 配 | 查件: | 用: | 区用查: | |||||
| I Mycat监控 | Mycat | o1 | 1户 | 2022-01-08 00 | :00-2022-01-08 22:57 | |||
| SC-控 | ||||||||
| O SQS析 | 查 重置 | |||||||
| OS腔 | R | 数细理 | 黑户 | IP | SQL | HB(m | s) 执行时间 | |
| O SOO 5计 | Mycat01 | roct | selectfreo thcrder Smit 4 | D3 | 2022-01-08 22:50.29 | |||
| O SOU | Mycat01 | 1004 | select*from th_order Smit | 3 | 2 | 2022-01-08 22:50:28 | ||
| il SQL-上 | il SQL-上 | Mycat01 | root | selectfrom th_order lmit 5 | 2022-01-08 22:50:25 | |||
| Mycat Zone | Mycat Zone | Mycat01 | Fo0f | selectfrom th onder Smit lecttom th order Smit | 20 1 |
2 2 |
2022-01-08 225023 | |
| Mycat01Mycat01 | roct1004 | seselect*from th_order | 2022-01-0822:50212022-01-08 22:50:18 | |||||
| Mycat01 | root | select*fom th longhash w | 5here id<100 7 | 5here id<100 7 | 2022-01-08 225007 | |||
| Mycat01 | roct | selectfrom tb_longhath | 2022-01-08 22:50:03 |
F.高频SQL
| Mycat-ey | e = | e = | e = | e = | ||||
|---|---|---|---|---|---|---|---|---|
| 号单 | 高频SQL监控 | 高频SQL监控 | 高频SQL监控 | 高频SQL监控 | 高频SQL监控 | 高國編* 高腔 | ||
| Mya | ||||||||
| I M控 | 查询条件用户: | 数据源: | 区用查 | |||||
| SC-监 | 用户 | Mycat01 | 2022-01- | 08 00:00-2022-01-08 2 | 2:58 | |||
| O SOL计SO分析OSQ监控 | 查 | 重置 | ||||||
| O SCL | ||||||||
| O | 查询结果 | 查询结果 | 查询结果 | 查询结果 | 查询结果 | 查询结果 | 查询结果 | |
| S昕 | 操 | 作 结息 | 用户 数细理 | SQL | HE( | ms) 最大时 | ||
| SCK-上 | r | oot Mycat01 | DINSERT INTO tb_dat | epert fid name, create ti | mel VALUES (2,2.7) | |||
| 信Mysat Zone | r | oot Mycat01 | INSERT INTO tb use | r (id username, status) V | ALUES (,2,7) 8 | ALUES (,2,7) 8 | ||
| r | o0t Mycat01 | SELECT*FROM tb,a | pp LIMIT? | 3 | 3 | |||
| r | oot Mycat01 | SELECT*FROM tb J | onghash WHERE id? | 7 | 7 | |||
| 日 | 期 1 | 00t Mycat01 | SELECT*FROM tb_o | rder LIMIT7 | 2 | |||
| 期 r | oot Mycat01 | select*fom tb.app | 4 | |||||
| r | o0t Mycat01 | select*from tb_date | part | 10 | 10 | |||
| 号 r | oot Mycat01 | select*from tb_long | hmh | 7 | 7 |
4.读写分离
4.1 介绍
读写分离,简单地说是把对数据库的读和写操作分开,以对应不同的数据库服务器。主数据库提供写操作,从数据库提供读操作,这样能有效地减轻单台数据库的压力。
通过MyCat即可轻易实现上述功能,不仅可以支持MySQL,也可以支持Oracle和SQL Server。

4.2 一主一从
4.2.1 原理
MySQL的主从复制,是基于二进制日志(binlog)实现的。

4.2.2 准备
| 主机 | 角色 | 用户名 | 密码 |
|---|---|---|---|
| 192.168.200.211 | master | root | 1234 |
| 192.168.200.212 | slave | root | 1234 |
备注:主从复制的搭建,可以参考前面课程中 主从复制 章节讲解的步骤操作。
4.3 一主一从读写分离
MyCat控制后台数据库的读写分离和负载均衡由schema.xml文件datahost标签的balance属性控制。
4.3.1 schema.xml配置
| 1 | <!– 配置逻辑库 –> |
|---|---|
| 2 | <schema name=”ITCAST_RW” checkSQLschema=”true” sqlMaxLimit=”100” |
| 3 | </schema> |
| 4 | |
| 5 | <dataNode dataHost=” |
| 6 | |
| 7 | <dataHost na m mi |
| “ slaveThreshold=”100”> | |
| 8 | <heartbeat>select user()</heartbeat> |
| 9 | |
| 10 | <writeHost “ dbc:mysql://192.168.200.211:3306? |
| useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8” | |
| 11 | > |
| 11 | <readHost dbc:mysql://192.168.200.212:3306? |
| useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8” | |
| 12 13 |
</dataHost> |
上述配置的具体关联对应情况如下:

writeHost代表的是写操作对应的数据库,readHost代表的是读操作对应的数据库。 所以我们要想实现读写分离,就得配置writeHost关联的是主库,readHost关联的是从库。
而仅仅配置好了writeHost以及readHost还不能完成读写分离,还需要配置一个非常重要的负责均衡的参数 balance,取值有4种,具体含义如下:
| 参数值 | 含义 |
|---|---|
| 0 | 不开启读写分离机制 , 所有读操作都发送到当前可用的writeHost上 |
| 1 | 全部的readHost 与 备用的writeHost 都参与select 语句的负载均衡(主要针对于双主双从模式) |
| 2 | 所有的读写操作都随机在writeHost , readHost上分发 |
| 3 | 所有的读请求随机分发到writeHost对应的readHost上执行, writeHost不负担读压力 |
所以,在一主一从模式的读写分离中,balance配置1或3都是可以完成读写分离的。
4.3.2 server.xml配置
配置root用户可以访问SHOPPING、ITCAST 以及 ITCAST_RW逻辑库。
| 1 | <user |
|---|---|
| 2 | <property |
| 3 | <property chemas”>SHOPPING,ITCAST,ITCAST_RW</property> |
| 4 | |
| 5 | <!– 表级 DML 权限设置 –> |
| 6 | |
| 7 | <privileges |
| 8 | <schema |
| 9 | <table |
| 10 | </schema> |
| 11 | </privileges> |
| 12 | –> |
| 13 | </user> |
4.3.3 测试
配置完毕MyCat后,重新启动MyCat。
1bin/mycat stop
2bin/mycat start
然后观察,在执行增删改操作时,对应的主库及从库的数据变化。 在执行查询操作时,检查主库及从库对应的数据变化。
在测试中,我们可以发现当主节点Master宕机之后,业务系统就只能够读,而不能写入数据了。

那如何解决这个问题呢?这个时候我们就得通过另外一种主从复制结构来解决了,也就是我们接下来讲解的双主双从。
4.4 双主双从
4.4.1 介绍
一个主机 Master1 用于处理所有写请求,它的从机 Slave1 和另一台主机 Master2 还有它的从机 Slave2 负责所有读请求。当 Master1 主机宕机后,Master2 主机负责写请求,Master1 、Master2 互为备机。架构图如下:

4.4.2 准备
我们需要准备5台服务器,具体的服务器及软件安装情况如下:
| 编号 | IP | 预装软件 | 角色 |
|---|---|---|---|
| 1 | 192.168.200.210 | MyCat、MySQL | MyCat中间件服务器 |
| 2 | 192.168.200.211 | MySQL | M1 |
| 3 | 192.168.200.212 | MySQL | S1 |
| 4 | 192.168.200.213 | MySQL | M2 |
| 5 | 192.168.200.214 | MySQL | S2 |
| 关闭以上所有服务器的防火墙: |
|---|
| systemctl stop firewalld |
| systemctl disable firewalld |
4.4.3 搭建
4.4.3.1 主库配置
1). Master1(192.168.200.211)

A.修改配置文件/etc/my.cnf
| 1 | #mysq1 服务ID,保证整个集群环境中唯一,取值范围:1-2^32-1,默认为1 |
|---|---|
| 2 | $\sec v e r - i d = 1$ |
| 3 | #指定同步的数据库 |
| 4 | $b \in 1 0 g - d o - d b = d b 0 1$ |
| 5 | $b \in 1 0 g - d o - d b = d b 0 2$ |
| 6 | $b \in 1 0 g - d o - d b = d b 0 3$ |
| 7 | #在作为从数据库的时候,有写入操作也要更新二进制日志文件 |
| 8 | $1 0 9 - 8 1 a v e - u p d a t e s$ |
B.重启MySQL服务器
| 1 | systemct1 | restart | mysqld |
|---|
c.创建账户并授权
1 #创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
2 CREATEUSER ‘itcast‘@*s’ IDENTIFIED WITH mysql_native password BY ‘Root@123456’;
3 #为'itcast'@%用户分配主从复制权限
4 GRANT REPLICATION SLAVE ON*.* TO ‘itcast‘@’%’;
通过指令,查看两台主库的二进制日志坐标

| mysq1> CREATB USER “itcast‘@”*IDEN7IFIE |
|---|
| QueEy OK,O rows affected (0.00 senlmysq1> ORANT REPLICATION JLAVE ON g |
| Query Ok, 0 rows affected (0.00 sec) |
| mysl>ayoq1> |
| File |
| binlog.000002I row in set (0.00 sec) |
2). Master2(192.168.200.213)

A. 修改配置文件 /etc/my.cnf
| 1 | #mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,默认为1 |
|---|---|
| 2 | |
| 3 | #指定同步的数据库 |
| 4 | |
| 5 | |
| 6 | |
| 7 | # 在作为从数据库的时候,有写入操作也要更新二进制日志文件 |
| 8 |
B. 重启MySQL服务器
| 1 | systemc | tl restar | t mysqld |
|---|
C. 创建账户并授权
1#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
2CREATE USER ‘itcast‘@’%’ IDENTIFIED WITH mysql_native_password BY ‘Root@123456’;
3#为 ‘itcast‘@’%’ 用户分配主从复制权限
4GRANT REPLICATION SLAVE ON . TO ‘itcast‘@’%’;
| 1 | show | master | status; |
|---|
| nyaq1> CREATR O3ER “Iccast‘@’s’ IDENSIPIEoR,o rows affected (0.00 |
|---|
| Query sec)nysg> ANT REPLICAION SEAV□N |
| query Ok, owsafe(0.00 sec) |
| nysqa> shcw master atacun |
| Lrile 00binlcg.0000 063 db01,db02,db03 |
| 02FOM1n ) |

4.4.3.2 从库配置
1). Slave1(192.168.200.212)

A.修改配置文件/etc/my.cnf
1 #mysq1 服务ID,保证整个集群环境中唯一,取值范围:1-232-1,默认为1
2 secver-1d=2
B.重新启动MySQL服务器
1 systemct1 restart mysqld
2). Slave2(192.168.200.214)

A. 修改配置文件 /etc/my.cnf
1#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
2 secvwer-id=4
B. 重新启动MySQL服务器

4.4.3.3 从库关联主库
1). 两台从库配置关联的主库

需要注意slave1对应的是master1,slave2对应的是master2。
A.在 slave1(192.168.200.212)上执行
| $C H N G E M N S T E R T O M S T E R H O S T H O S T H U O S T H U O , 2 0 0 , 2 1 1 ^ { - } , M S T E R U O S E R N ^ { - 1 } 1 t e O A C ‘ ,$ |
|---|
| $M A S T E R P A S S N O R D = ‘ R O O t [ Q 1 2 3 4 5 6 ^ { \circ }$$M A S T E R L O G P O S = 6 6 3 ;$ |
B.在 slave2(192.168.200.214)上执行
| CHANGE MASTER TO MA |
|---|
| $M A S T E R P A S S N O R D = ^ { \prime } R O O E ( 0 . 1 2 3 4 5 6 ^ { \circ }$$M A S T E R L O G P O S = 6 6 3 ;$ |
c.启动两台从库主从复制,查看从库状态
| 1 |
|---|
| 2 |


2). 两台主库相互复制

1Master2 复制 Master1,Master1 复制 Master2。
A. 在 Master1(192.168.200.211)上执行
| CHANGE MASTER TO MA |
|---|
| MASTER_PASSWORD=’Ro |
| CHANGE MASTER TO MA |
C. 启动两台从库主从复制,查看从库状态


经过上述的三步配置之后,双主双从的复制结构就已经搭建完成了。 接下来,我们可以来测试验证一下。
4.4.4 测试
分别在两台主库Master1、Master2上执行DDL、DML语句,查看涉及到的数据库服务器的数据同步情况。
| 1 | create database db01; |
|---|---|
| 2 | use db01; |
| 3 | create table |
| 4 | id int(11) not null primary key , |
| 5 | name varchar(50) not null, |
| 6 | sex varchar(1) |
| 7 | )engine=innodb default charset=utf8mb4; |
| 8 | |
| 9 | insert into tb_user(id,name,sex) values(1,’Tom’,’1’); |
10insert into tb_user(id,name,sex) values(2,’Trigger’,’0’);
11insert into tb_user(id,name,sex) values(3,’Dawn’,’1’);
12insert into tb_user(id,name,sex) values(4,’Jack Ma’,’1’);
13insert into tb_user(id,name,sex) values(5,’Coco’,’0’);
14insert into tb_user(id,name,sex) values(6,’Jerry’,’1’);
在Master1中执行DML、DDL操作,看看数据是否可以同步到另外的三台数据库中
在Master2中执行DML、DDL操作,看看数据是否可以同步到另外的三台数据库中
完成了上述双主双从的结构搭建之后,接下来,我们再来看看如何完成这种双主双从的读写分离。
4.5 双主双从读写分离
4.5.1 配置
MyCat控制后台数据库的读写分离和负载均衡由schema.xml文件datahost标签的balance属性控制,通过writeType及switchType来完成失败自动切换的。
1). schema.xml
配置逻辑库:
1<schema name=”ITCAST_RW2” checkSQLschema=”true” sqlMaxLimit=”100”dataNode=”dn7”>
2</schema>
配置数据节点:
1<dataNode name=”dn7” $d a t a H o s t = n c h o s t 7 ^ { n }$ database=”db01” />
配置节点主机:
1<dataHostname=”dhost7” ma×Con=”1000” m∈Con=”10” ba1ance=”1” writeType=”0”$d b T y p e = “ m y s q l ^ { n }$dbDriver=”jdbc” switchType=”1” $s l a v e T h r e s h o l d = ^ { w } 1 0 0 ^ { n } >$
2 <heartbeat>select user()</heartbeat>
3
4 <writeHost $h o s t = ^ { \prime \prime } m a s t e r 1 ^ { \prime }$” ux1=”jdbc:mysql://192.168.200.211:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8”$u \sec x = ^ { w } x \cot ^ { w }$ $p a s s w o r d = ^ { n } 1 2 3 4 ^ { n }$>
5 <readHost $h o s t = ^ { w } s l a v e 1 ^ { n }$ ur1=”jdbc:mysql://192.168.200.212:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8”$u \sec x = ^ { w } x \cot ^ { w }$ $p a s s w o r d = “ 1 2 3 4 ^ { n }$1>
6 </writeHost>
7
8 <writeHost $h o s t = ^ { \prime \prime } m a s t e r 2 ^ { n }$ uxl=”j)。dbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8”$u s e r = ^ { n } r o o t ^ { \prime \prime }$ $p a s s w o r d = ^ { n } 1 2 3 4 ^ { n }$>
9 <readHost$h o s t = ^ { \prime \prime } s l a v e 2 ^ { n }$ ur1=”jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8”$u s e r = ^ { n } r o o t ^ { \prime \prime }$ $p a s s w o r d = “ 1 2 3 4 ^ { n }$1>
10 </writeHost>
11</dataHost>
具体的对应情况如下:
属性说明:
ba1ance=”1”
代表全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡 ;
writeType
0 : 写操作都转发到第1台writeHost, writeHost1挂了, 会切换到writeHost2上;
1 : 所有的写操作都随机地发送到配置的writeHost上 ;
switchType
-1 : 不自动切换
1 : 自动切换
2). user.xml
配置root用户也可以访问到逻辑库 ITCAST_RW2。
| 1 | |
|---|---|
| 2 | |
| 3 | <property chemas”>SHOPPING,ITCAST,ITCAST_RW2</property> |
| 4 | |
| 5 | <!– 表级 DML 权限设置 –> |
| 6 | |
| 7 | <privileges |
| 8 | <schema |
| 9 | <table |
| 10 | </schema> |
| 11 | </privileges> |
| 12 | –> |
| 13 | </user> |
4.5.2 测试
登录MyCat,测试查询及更新操作,判定是否能够进行读写分离,以及读写分离的策略是否正确。
当主库挂掉一个之后,是否能够自动切换。


{kind=link}