
HBase教程

HBase教程
Smith文章目录
- 1. HBase 简介
- 2. HBase 快速入门
- 3. HBase 进阶
- 4. HBase API 操作
- 5. HBase 优化
1. HBase 简介
1.1 HBase 定义
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
1.2 HBase 背景
HBase 的原型是 Google 的 BigTable 论文,受到了该论文思想的启发,目前作为 Hadoop的子项目来开发维护,用于支持结构化的数据存储。
- 2006 年 Google 发表 BigTable 白皮书
- 2006 年开始开发 HBase
- 2008 年北京成功开奥运会,程序员默默地将 HBase 弄成了 Hadoop 的子项目
- 2010 年 HBase 成为 Apache 顶级项目
- 现在很多公司二次开发出了很多发行版本
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBASE 技术可在廉价 PC Server 上搭建起大规模结构化存储集群。HBase 的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase 是 Google Bigtable 的开源实现,但是也有很多不同之处。比如:
- Google Bigtable 利用 GFS 作为其文件存储系统,HBase 利用 Hadoop HDFS 作为其文件存储系统;
- Google 运行 MapReduce 来处理 Bigtable 中的海量数据,HBase 同样利用 Hadoop MapReduce 来处理 HBase 中的海量数据;
- Google Bigtable 利用 Chubby 作为协同服务,HBase 利用 Zookeeper 作为对应。
1.3 HBase 数据模型
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map。
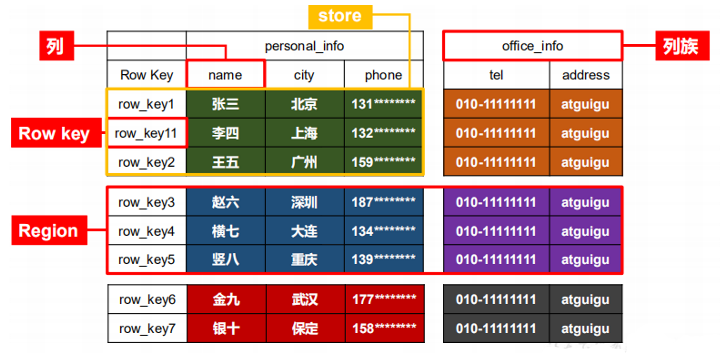
1.3.1 HBase 逻辑结构
1.3.2 HBase 物理存储结构
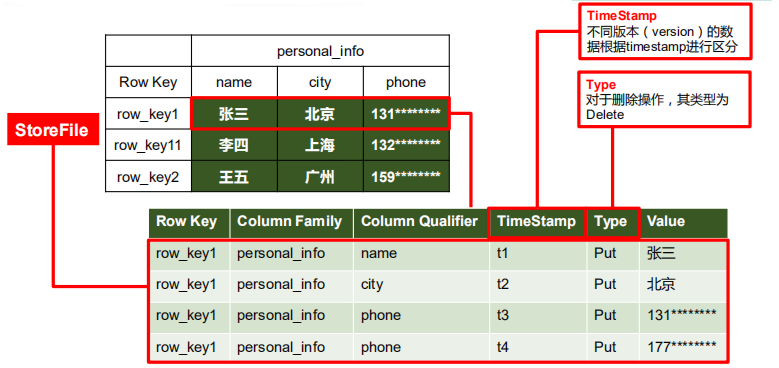
1.3.3 数据模型
NameSpace
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase 有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。
Region
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限
定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会
自动为其加上该字段,其值为写入 HBase 的时间。Cell
由 {rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数
据是没有类型的,全部是字节码形式存贮。
1.4 HBase 基本架构
(不完整版)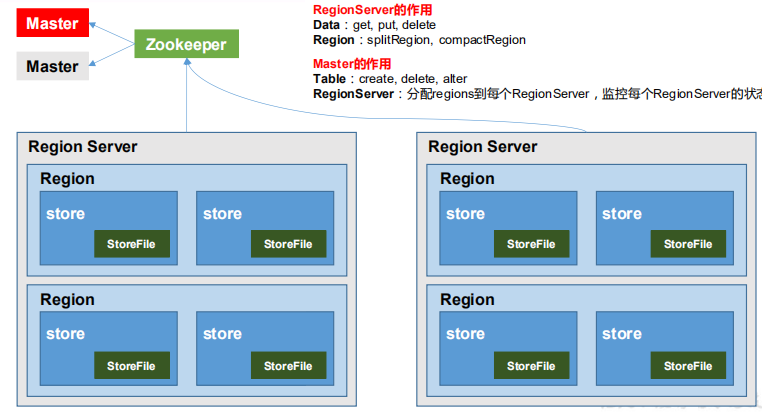
RegionServer
Region Server 为 Region 的管理者,其实现类为 HRegionServer,主要作用如下:
① 对于数据的操作:get, put, delete;
② 对于 Region 的操作:splitRegion、compactRegion。Master
Master 是所有 RegionServer 的管理者,其实现类为 HMaster,主要作用如下:
① 对于表的操作:create, delete, alter
② 对于 RegionServer的操作:分配 regions 到每个 RegionServer,监控每个 RegionServer 的状态,负载均衡和故障转移。Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及
集群配置的维护等工作。HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。
2. HBase 快速入门
2.1 HBase 官网地址
2.2 HBase 安装流程
- 启动 Hadoop 集群
- 启动 Zookeeper
- 将 HBase 的安装包上传到服务器上(hbase-2.2.2-bin.tar.gz)
- 解压 HBase 到指定目录
1 | tar -zxvf hbase-2.2.2-bin.tar.gz -C /hadoop/ |
修改 HBase 的配置文件(/hadoop/hbase-2.2.2/conf/ 目录下)
① hbase-env.sh 修改内容:
1 | The java implementation to use. Java 1.8+ required. |
1 | Tell HBase whether it should manage it's own instance of ZooKeeper or not. |
② hbase-site.xml 修改内容:
1 | <configuration> |
③ regionservers:
1 | master |
⑤ 软连接 hadoop 配置文件到 hbase:
1 | ln -s /hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml /hadoop/hbase-2.2.2/conf/core-site.xml |
1 | ln -s /hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml /hadoop/hbase-2.2.2/conf/hdfs-site.xml |
- 将 HBase 同步到其他机器上
1 | xsync /hadoop/hbase-2.2.2/ |
- 配置环境变量
1 | vim /etc/profile |
添加以下内容:
1 | #HBASE |
使配置文件生效
1 | source /etc/profile |
同步其他机器配置文件并分别使配置文件生效
1 | xsync /etc/profile |
HBase 服务的启动
① 方式一
1 | hbase-daemon.sh start master |
1 | hbase-daemon.sh start regionserver |
② 方式二
1 | start-hbase.sh |
对应的停止服务
1 | stop-hbase.sh |
- 查看 HBase 页面
2.3 HBase Shell 操作
2.3.1 基本操作
- 进入 HBase 客户端命令行
1 | hbase shell |
- 查看帮助命令
1 | help |
- 查看当前数据库中有哪些表
1 | list |
2.3.2 表的操作
- 创建表
1 | create 'student','info' |
- 插入数据到表
1 | put 'student','1001','info:sex','male' |
1 | put 'student','1001','info:age','18' |
1 | put 'student','1002','info:name','Janna' |
1 | put 'student','1002','info:sex','female' |
1 | put 'student','1002','info:age','20' |
- 扫描查看表数据
1 | scan 'student' |

1 | scan 'student',{STARTROW => '1001', STOPROW => '1001'} |
1 | scan 'student',{STARTROW => '1001'} |
- 查看表结构
1 | describe 'student' |
- 更新指定字段的数据
1 | put 'student','1001','info:name','Nick' |
1 | put 'student','1001','info:age','100' |
- 查看 “指定行” 或 “指定列族:列” 的数据
1 | get 'student','1001' |
1 | get 'student','1001','info:name' |
- 统计表数据行数
1 | count 'student' |
变更表信息
将 info 列族中的数据存放 3 个版本
1 | alter 'student',{NAME=>'info',VERSIONS=>3} |
1 | get 'student','1001',{ |
删除数据
① 删除某 rowkey 的全部数据
1 | deleteall 'student','1001' |
② 删除某 rowkey 的某一列数据
1 | delete 'student','1002','info:sex' |
- 清空表数据
1 | truncate 'student' |
提示:清空表的操作顺序为先 disable,然后再 truncate。
- 删除表
① 首先需要先让该表为 disable 状态
1 | disable 'student' |
② 然后才能 drop 这个表
1 | drop 'student' |
2.3.3 命名空间的基本操作
- 查看命名空间
1 | list_namespace |
- 创建命名空间
1 | create_namespace 'bigdata' |
- 在新的命名空间中创建表
1 | create 'bigdata:student','info' |
删除命名空间
只能删除空的命名空间,如果不为空,需要先删除该命名空间下的所有表
1 | drop_namespace 'bigdata' |
3. HBase 进阶
3.1 架构原理
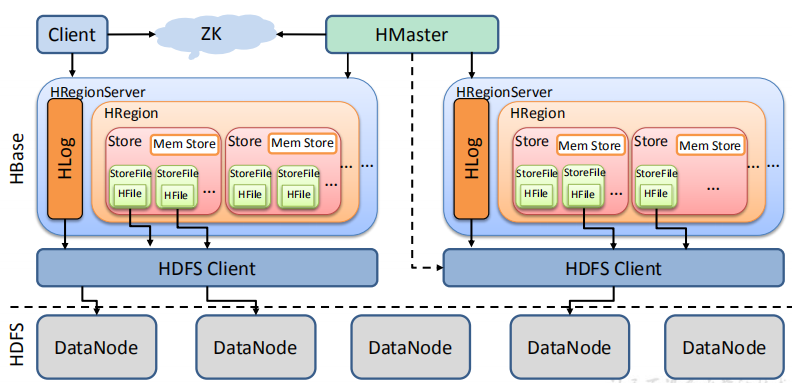
StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
3.2 读流程
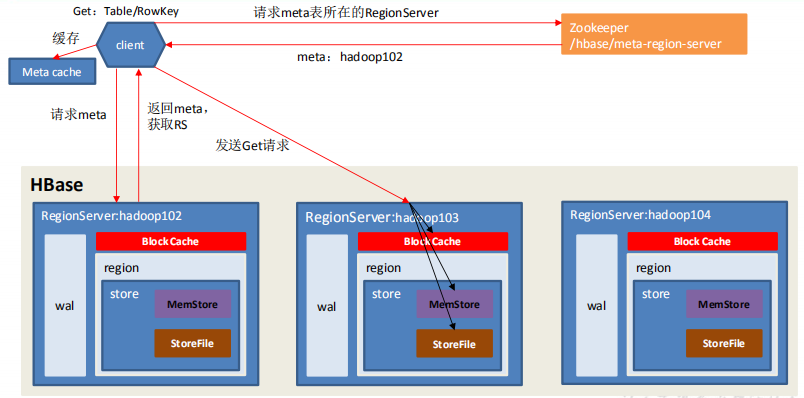
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
- 访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
- 与目标 Region Server 进行通讯;
- 将数据顺序写入(追加)到 WAL;
- 将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
- 向客户端发送 ack;
- 等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
3.3 MemStore Flush
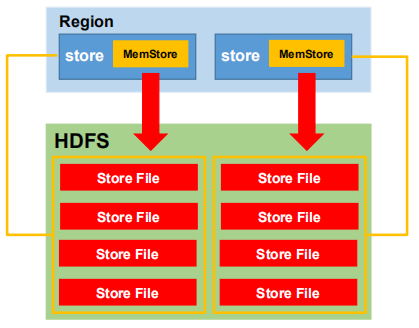
当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M), 其所在 region 的所有 memstore 都会刷写,并且会阻止继续往该 memstore 写数据。
当 region server 中 memstore 的总大小达到 *hbase.regionserver.global.memstore.size(默认值 0.4), *hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server 中所有 memstore 的总大小减小到上述值以下。
当 region server 中 memstore 的总大小达到 java_heapsize*hbase.regionserver.global.memstore.size(默认值 0.4)时,会阻止继续往所有的 memstore 写数据。
到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)
当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进
行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃,
现无需手动设置,最大值为 32)。
3.4 读流程
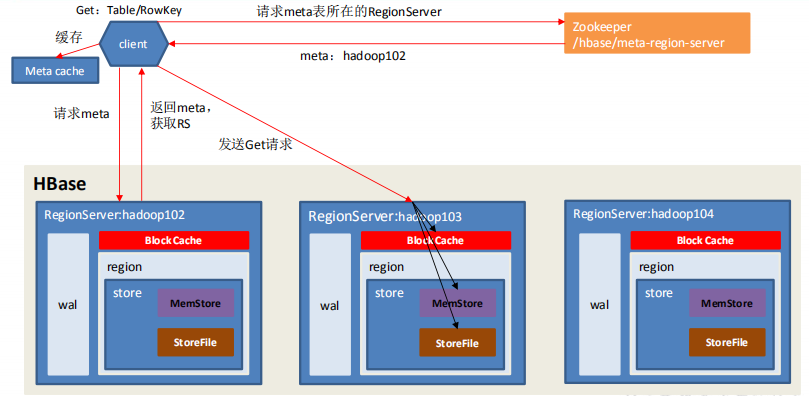
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
- 访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
- 与目标 Region Server 进行通讯;
- 分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
- 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到 Block Cache。
- 将合并后的最终结果返回给客户端。
3.5 StoreFile Compaction
由于 memstore 每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor Compaction 会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期和删除的数据。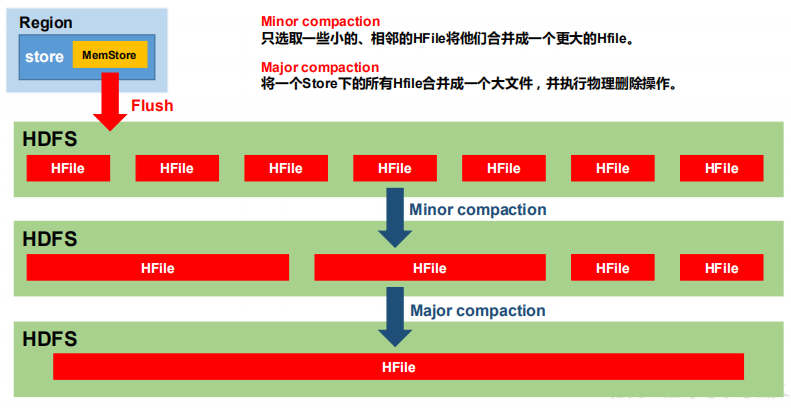
3.6 Region Split
默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进
行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。
- 当 1 个 region 中的某个 Store 下所有 StoreFile 的总大小超过 hbase.hregion.max.filesize, 该 Region 就会进行拆分(0.94 版本之前)。
- 当 1 个 region 中 的 某 个 Store 下所有 StoreFile 的 总 大 小 超 过 Min(R^2 *
“hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize”),该 Region 就会进行拆分,其
中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。

4. HBase API 操作
4.1 环境准备
新建项目后在 pom.xml 中添加依赖:
1 | <dependencies> |



