

MapReduce技术细节一、概述1、MapReduce是Hadoop提供的一套用于进行分布式的计算框架
2、MapReduce程序将整个计算过程拆分成两个阶段:Map阶段(映射)和Reduce阶段(规约)
二、MapReduce程序的执行流程
三、Winodws系统的环境配置1、Hadoop对Winodws的兼容性不强,所以如果不配置则运行MR程序就会报错
2、如果双击winutils.exe报错,将msvcr120.dll复制到C:\Windows\System32目录下
3、配置环境变量
四、MapReduce程序相关案例①字符统计案例1、CharCountMapper类
12345678910111213141516171819202122232425262728293031323334353637package com.itcast.charcount;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.T ...
HDFS技术细节一、HDFS — Hadoop Distributed File System(Hadoop分布式文件系统)
1、HDFS是Hadoop提供的一套用于分布式存储的文件系统
2、为了方便使用仿照Linux系统设计的一套文件系统
3、HDFS是典型的主从结构 — NameNode(主节点)和DataNode(从节点)
4、HDFS在存储文件的时候会真实的对文件进行物理切分 – Hadoop2.x版本所切分的每一个数据块是128MB
5、在HDFS中会自动对数据进行备份,这个备份称之为副本,在完全分布式中默认的副本数量为3,但是在伪分布
式中副本数量只能为1
Block
1、Block是HDFS中的数据存储的基本单位,即一个文件在HDFS中是由一个或者多个Block组成
2、Block的大小默认是128MB,在Hadoop1.x版本中默认是64MB
3、如果一个文件本身不到Block的大小,那么这个文件是多大则对应的Blokc就是多大
4、HDFS会对Block进行编号 — Block ID
5、物理切块的意义:①能够存储超大文件 ②能够快速的备份
NameNode
1 ...
搭建Hadoop完全分布式一、完全分布式结构图
二、完全分布式简易图
三、实现步骤:1、三个节点需要关闭防火墙
①临时关闭:sudo systemctl stop firewalld
②永久关闭:sudo systemctl disable firewalld
2、三个节点需要修改主机名称
①编辑文件:vim /etc/hostname
②修改主机名称为对应的名称:hadoop01/hadoop02/hadoop03
3、三个节点需要进行IP地址与主机名称的映射
①编辑文件:vim /etc/hosts
②添加配置
123192.168.232.128 hadoop01192.168.232.129 hadoop02192.168.232.130 hadoop03
4、三个节点重新启动用于加载系统配置:reboot
5、三个节点需要进行免密互通
①生成公钥和秘钥,生成的公钥和秘钥将会自动存储在/root/.ssh目录下:ssh-keygen
②三个节点需要进行执行注册
12 ...
搭建Hadoop完全分布式一、完全分布式结构图
二、完全分布式简易图
三、实现步骤:1、三个节点需要关闭防火墙
①临时关闭:sudo systemctl stop firewalld
②永久关闭:sudo systemctl disable firewalld
2、三个节点需要修改主机名称
①编辑文件:vim /etc/hostname
②修改主机名称为对应的名称:hadoop01/hadoop02/hadoop03
3、三个节点需要进行IP地址与主机名称的映射
①编辑文件:vim /etc/hosts
②添加配置
123192.168.232.128 hadoop01192.168.232.129 hadoop02192.168.232.130 hadoop03
4、三个节点重新启动用于加载系统配置:reboot
5、三个节点需要进行免密互通
①生成公钥和秘钥,生成的公钥和秘钥将会自动存储在/root/.ssh目录下:ssh-keygen
②三个节点需要进行执行注册
12 ...
Zookeeper的安装方式一、单机模式实现步骤:
1、三个节点需要关闭防火墙
①临时关闭:sudo systemctl stop firewalld
②永久关闭:sudo systemctl disable firewalld
2、解压Zookeeper的安装包
1tar -xvf zookeeper-3.4.7.tar.gz -C /home/software/
3、进入Zookeeper的安装目录:cd zookeeper-3.4.7/conf
4、复制模版文件并且重命名:cp zoo_sample.cfg zoo.cfg
5、编辑文件:vim zoo.cfg
6、修改dataDir属性
1dataDir=/home/software/zookeeper-3.4.7/tmp
7、进入bin目录:cd ../bin/
8、启动Zookeeper:sh zkServer.sh start
9、查看Zookeeper的状态:sh zkServer.sh status
10、单机模式的状态:standalone
二、完全分布式实现步骤:
1、三个 ...

数据库开发-MySQL前言为了应用程序职责单一,方便维护,我们一般将web应用程序分为三层,即:Controller、Service、Dao 。
请求流程:浏览器发起请求,先请求Controller;Controller接收到请求之后,调用Service进行业务逻辑处理;Service再调用Dao,Dao再解析user.xml中所存储的数据。
xml文件中可以存储数据,但是在企业项目开发中不会使用xml文件存储数据,因为不便管理维护,操作难度大。 在真实的企业开发中呢,都会采用数据库来存储和管理数据,那此时,web开发调用流程图如下所示:
首先来了解一下什么是数据库。
数据库:英文为 DataBase,简称DB,它是存储和管理数据的仓库。
像我们日常访问的电商网站京东,企业内部的管理系统OA、ERP、CRM这类的系统,以及大家每天都会刷的头条、抖音类的app,那这些大家所看到的数据,其实都是存储在数据库中的。
数据是存储在数据库中的,那我们要如何来操作数据库以及数据库中所存放的数据呢?
那这里呢,会涉及到一个软件:数据库管理系统(DataBase Management Sys ...
DCLDCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。
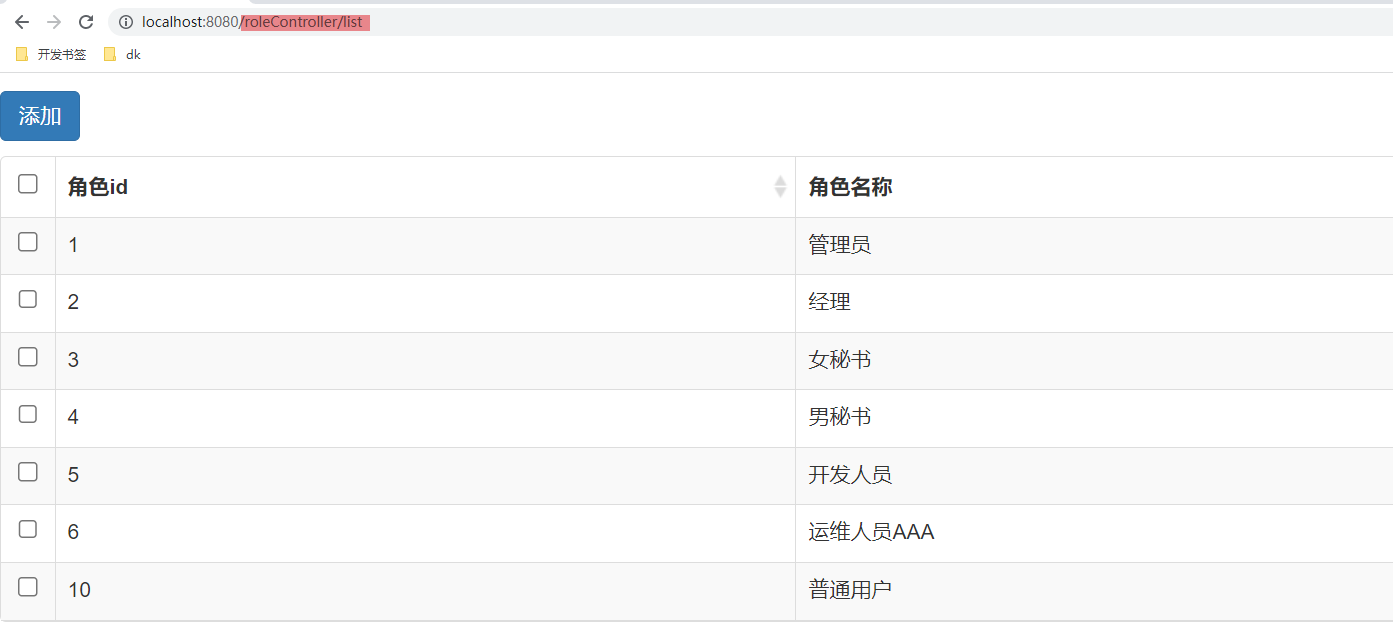
2.7.1 管理用户1).查询用户
1select * from mysql.user;
查询的结果如下:
其中 Host代表当前用户访问的主机, 如果为localhost, 仅代表只能够在当前本机访问,是不可以远程访问的。 User代表的是访问该数据库的用户名。在MySQL中需要通过Host和User来唯一标识一个用户。
2).创建用户
1CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
3).修改用户密码
1ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码' ;
4).删除用户
1DROP USER '用户名'@'主机名' ;
注意事项: • 在MySQL中需要通 ...
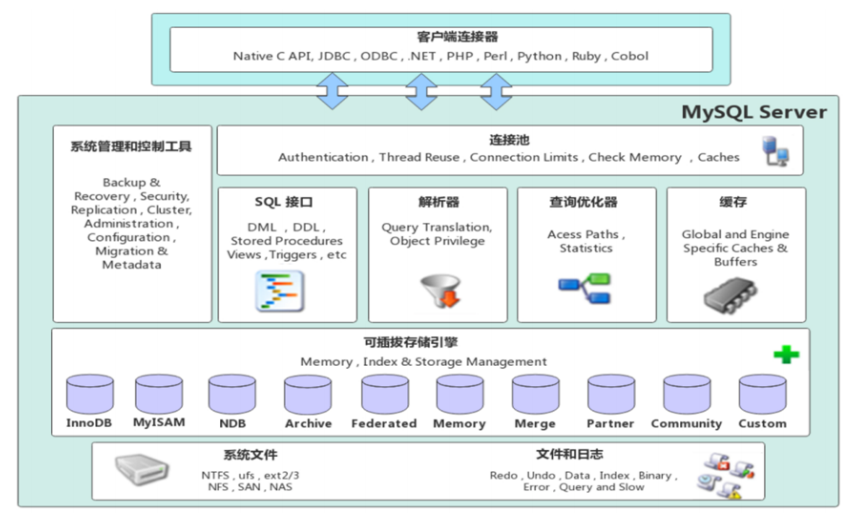
mysql进阶1. 存储引擎1.1 mysql体系结构
1). 连接层
最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于客户端/服务端工具实现的类似于TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
2). 服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
3). 引擎层
存储引擎层, 存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎具有 ...
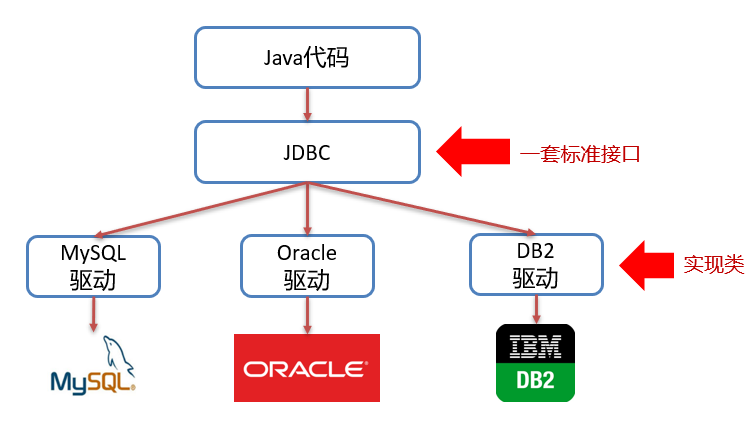
JDBC1,JDBC概述1.1 JDBC概念
JDBC 就是使用Java语言操作关系型数据库的一套API
全称:( Java DataBase Connectivity ) Java 数据库连接
我们开发的同一套Java代码是无法操作不同的关系型数据库,因为每一个关系型数据库的底层实现细节都不一样。
我们要做到的是同一套Java代码操作不同的关系型数据库,而此时sun公司就指定了一套标准接口(JDBC),JDBC中定义了所有操作关系型数据库的规则。
众所周知接口是无法直接使用的,我们需要使用接口的实现类,而这套实现类(称之为:驱动)就由各自的数据库厂商给出。
1.2 JDBC本质
官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口
各个数据库厂商去实现这套接口,提供数据库驱动jar包
我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动jar包中的实现类
1.3 JDBC好处
各数据库厂商使用相同的接口,Java代码不需要针对不同数据库分别开发
可随时替换底层数据库,访问数据库的Java代码基本不变
以后编写操作数据库的代码只需要面向JDBC(接口 ...

数据库开发-MySQL1. 单表查询12345-- 单表查询练习-- 按 job 升序排序,相同,则按入职时间降序排序 (job和entrydate任意一个都不能是null)SELECT * FROM tb_emp WHERE not (job is null or entrydate is null) ORDER BY job,entrydate desc;SELECT * FROM tb_emp WHERE job is not null and entrydate is not null ORDER BY job,entrydate desc;
1.1 排序查询排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法:
12345select 字段列表 from 表名 [where 条件列表] [group by 分组字段 ] order by 字段1 排序方式1 , 字段2 排序方式2 … ;
排序方式:
ASC :升序(默认值)
DESC:降序
案例1:根据入职时间, 对员工进行升序排序
1234567select id, ...

🔥 热搜
加载中...

