数据库 MySQL · 入门重点总结 一、数据库概述 1.1 核心名词
名词
全称
说明
DB Database(数据库)
存储和管理数据的仓库,本质是一堆文件
DBMS Database Management System(数据库管理系统)
操作和管理数据库的软件,如 MySQL、Oracle
SQL Structured Query Language(结构化查询语言)
操作所有关系型数据库 的统一标准编程语言
RDBMS 关系型数据库管理系统
基于二维表 (行+列)存储数据,支持 SQL
关系链 :程序员 → 编写 SQL → 发给 DBMS → DBMS 操作 DB 中的数据
1.2 常见数据库软件
软件
特点
MySQL 开源免费,中小型,最常用(本课程使用 8.x)
Oracle
大型收费,稳定性高,企业级不差钱时使用
SQL Server
微软出品,收费,C#/.NET 常用
1.3 连接 MySQL 1 2 3 4 5 6 7 mysql -u用户名 -p密码 [-h IP地址 -P 端口号] mysql -uroot -p123456 mysql -uroot -p123456 -h192.168.1.100 -P3306
1.4 SQL 通用语法规则
规则
说明
语句结尾
以 分号 ; 结尾
大小写
SQL 关键字不区分大小写 (建议大写关键字)
空格/换行
可以随意使用,增加可读性
单行注释
-- 注释内容 或 # 注释内容(MySQL 特有)
多行注释
/* 注释内容 */
1.5 SQL 四大分类
分类
全称
作用
核心关键字
DDL Data Definition Language
定义数据库对象(库、表、字段)
CREATE DROP ALTER
DML Data Manipulation Language
对表中数据进行增删改
INSERT UPDATE DELETE
DQL Data Query Language
查询表中数据
SELECT
DCL Data Control Language
创建用户、控制访问权限
GRANT REVOKE
二、DDL — 数据库操作 2.1 数据库操作 SQL
操作
语法
说明
查询所有数据库
SHOW DATABASES;列出所有数据库
查询当前数据库
SELECT DATABASE();查看当前所在库
创建数据库
CREATE DATABASE [IF NOT EXISTS] 库名;IF NOT EXISTS:避免已存在时报错
切换/使用数据库
USE 库名;操作表之前必须先 USE
删除数据库
DROP DATABASE [IF EXISTS] 库名;IF EXISTS:避免不存在时报错
1 2 3 4 5 6 SHOW DATABASES;CREATE DATABASE IF NOT EXISTS zhisheng;USE zhisheng; SELECT DATABASE(); DROP DATABASE IF EXISTS zhisheng;
三、DDL — 表操作 3.1 数据类型 ① 数值类型(常用)
类型
大小
说明
Java 对应
TINYINT1 字节
有符号 -128127;无符号 0255
—
INT / INTEGER4 字节
整数
int
BIGINT8 字节
大整数
long
DOUBLE(总长, 小数位)8 字节
双精度浮点
double
DECIMAL(M, D)依赖 M/D
精确小数 ,金融场景推荐BigDecimal
1 2 age TINYINT UNSIGNED score DOUBLE (4 , 1 )
② 字符串类型(常用)
类型
范围
特点
适用场景
CHAR(n)0~255 字符
定长 ,不足补空格,性能高固定长度:手机号、性别
VARCHAR(n)0~65535 字节
变长 ,按实际长度存,灵活不固定长度:用户名、备注
1 2 3 phone CHAR (11 ) gender CHAR (1 ) username VARCHAR (20 )
③ 日期时间类型(常用)
类型
格式
范围
说明
DATEYYYY-MM-DD1000-01-01 ~ 9999-12-31
只存日期(如生日)
DATETIMEYYYY-MM-DD HH:MM:SS1000-01-01 ~ 9999-12-31
日期+时间(如创建时间)最常用
TIMESTAMPYYYY-MM-DD HH:MM:SS1970-01-01 ~ 2038-01-19
时间戳,范围较小
1 2 birthday DATE create_time DATETIME
3.2 五大约束
约束
关键字
说明
非空约束 NOT NULL字段值不能为 null
唯一约束 UNIQUE字段值在表中必须唯一(可以为 null)
主键约束 PRIMARY KEY唯一标识一行,非空 + 唯一 ,每表只有一个
默认约束 DEFAULT 值未指定值时使用默认值
外键约束 FOREIGN KEY关联两张表,保证数据一致性
主键自增 AUTO_INCREMENT配合主键使用,每次插入自动 +1(从 1 开始)
3.3 建表语法 1 2 3 4 5 6 CREATE TABLE 表名 ( 字段1 数据类型 [约束] [COMMENT '注释' ], 字段2 数据类型 [约束] [COMMENT '注释' ], ... 字段n 数据类型 [约束] [COMMENT '注释' ] ) [COMMENT '表注释' ];
1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE TABLE tb_emp ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT 'ID' , username VARCHAR (20 ) NOT NULL UNIQUE COMMENT '用户名' , password VARCHAR (32 ) DEFAULT '123456' COMMENT '密码' , name VARCHAR (10 ) NOT NULL COMMENT '姓名' , gender TINYINT UNSIGNED NOT NULL COMMENT '性别 1男 2女' , image VARCHAR (300 ) COMMENT '头像' , job TINYINT UNSIGNED COMMENT '职位 1班主任 2讲师' , entrydate DATE COMMENT '入职日期' , create_time DATETIME NOT NULL COMMENT '创建时间' , update_time DATETIME NOT NULL COMMENT '修改时间' ) COMMENT '员工表' ;
设计表规范 :业务字段 + id(主键自增)+ create_time(创建时间)+ update_time(最后修改时间)
3.4 查询/修改/删除表 查询表:
操作
SQL
查询当前库所有表
SHOW TABLES;
查看表结构
DESC 表名;
查看建表语句
SHOW CREATE TABLE 表名;
修改表(ALTER):
操作
SQL
添加字段
ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT '注释'];
修改字段类型
ALTER TABLE 表名 MODIFY 字段名 新类型(长度);
修改字段名+类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度);
删除字段
ALTER TABLE 表名 DROP 字段名;
修改表名
RENAME TABLE 旧表名 TO 新表名;
删除表:
1 DROP TABLE [IF EXISTS ] 表名;
1 2 3 4 5 6 ALTER TABLE tb_emp ADD qq VARCHAR (11 ) COMMENT 'QQ号' ;ALTER TABLE tb_emp MODIFY qq VARCHAR (13 );ALTER TABLE tb_emp CHANGE qq qq_num VARCHAR (13 ) COMMENT 'QQ号' ;ALTER TABLE tb_emp DROP qq_num;RENAME TABLE tb_emp TO emp;
四、DML — 数据增删改 4.1 INSERT(插入)
语法
说明
INSERT INTO 表名 (字段...) VALUES (值...);指定字段插入单条
INSERT INTO 表名 VALUES (值...);全字段插入单条(值顺序必须与表字段完全一致)
INSERT INTO 表名 (字段...) VALUES (值...), (值...);批量 指定字段插入
1 2 3 4 5 6 7 8 9 10 11 12 INSERT INTO tb_emp (username, name, gender, create_time, update_time)VALUES ('wuji' , '张无忌' , 1 , NOW(), NOW());INSERT INTO tb_emp (id, username, password, name, gender, image, job, entrydate, create_time, update_time)VALUES (NULL , 'zhirou' , '123' , '周芷若' , 2 , '1.jpg' , 1 , '2010-01-01' , NOW(), NOW());INSERT INTO tb_emp (username, name, gender, create_time, update_time)VALUES ('weifuwang' , '韦一笑' , 1 , NOW(), NOW()), ('fengzi' , '张三疯' , 1 , NOW(), NOW());
⚠️ 注意:字符串和日期值要用单引号 包含;字段顺序与值顺序必须一一对应 ;NOW() 获取当前日期时间。
4.2 UPDATE(修改) 1 UPDATE 表名 SET 字段1 = 值1 , 字段2 = 值2 , ... [WHERE 条件];
1 2 3 4 5 UPDATE tb_emp SET name= '张三' , update_time= NOW() WHERE id= 1 ;UPDATE tb_emp SET entrydate= '2010-01-01' , update_time= NOW();
⚠️ 无 WHERE 会修改整张表 ;修改数据时,同步更新 update_time=NOW()。
4.3 DELETE(删除) 1 DELETE FROM 表名 [WHERE 条件];
1 2 3 4 5 6 7 8 DELETE FROM tb_emp WHERE id= 1 ;DELETE FROM tb_emp;TRUNCATE TABLE tb_emp;
⚠️ 无 WHERE 会删除整张表的数据 ;DELETE 不能只删某字段的值(需用 UPDATE 置为 NULL)。
五、DQL — 数据查询 5.1 完整查询语法结构 1 2 3 4 5 6 7 SELECT 字段列表FROM 表名WHERE 条件列表 GROUP BY 分组字段HAVING 分组后条件列表 ORDER BY 排序字段 [ASC | DESC ]LIMIT 起始索引, 每页条数;
执行顺序 :FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
5.2 基本查询
操作
语法
查询指定字段
SELECT 字段1, 字段2 FROM 表名;
查询所有字段
SELECT * FROM 表名;(实际开发少用 *,影响效率)
起别名
SELECT 字段 AS 别名 FROM 表名;(AS 可省略)
去重
SELECT DISTINCT 字段 FROM 表名;
1 2 3 SELECT name, entrydate FROM tb_emp;SELECT name AS '姓名' , entrydate AS '入职日期' FROM tb_emp;SELECT DISTINCT job FROM tb_emp;
5.3 条件查询(WHERE) 比较运算符:
运算符
说明
> >= < <= =大于/大于等于/小于/小于等于/等于
<> 或 !=不等于
BETWEEN min AND max范围查询,含两端
IN(值1, 值2, ...)多值匹配,任意一个即可
LIKE 占位符模糊匹配:_ 匹配单个 字符,% 匹配任意多个 字符
IS NULL值为 NULL(⚠️ 不能用 = NULL)
IS NOT NULL值不为 NULL
逻辑运算符:
运算符
说明
AND 或 &&多个条件同时成立
OR 或 ||多个条件任意一个成立
NOT 或 !取反
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 SELECT * FROM tb_emp WHERE name = '杨逍' ;SELECT * FROM tb_emp WHERE entrydate BETWEEN '2000-01-01' AND '2010-01-01' ;SELECT * FROM tb_emp WHERE entrydate >= '2000-01-01' AND entrydate <= '2010-01-01' ;SELECT * FROM tb_emp WHERE job IS NULL ;SELECT * FROM tb_emp WHERE job IS NOT NULL ;SELECT * FROM tb_emp WHERE job IN (2 , 3 , 4 );SELECT * FROM tb_emp WHERE name LIKE '__' ; SELECT * FROM tb_emp WHERE name LIKE '张%' ; SELECT * FROM tb_emp WHERE name LIKE '%三%' ; SELECT * FROM tb_empWHERE entrydate BETWEEN '2000-01-01' AND '2010-01-01' AND gender = 2 ;
5.4 聚合函数
定义 :对一列数据 进行纵向计算,返回单个结果值。聚合函数会忽略 NULL 值 (NULL 行不参与计算)。
函数
功能
注意
COUNT(字段)统计非 NULL 行数
推荐用 COUNT(*) — MySQL 已优化,效率最高
MAX(字段)最大值
MIN(字段)最小值
AVG(字段)平均值
SUM(字段)求和
非数值列结果为 0
1 2 3 4 5 6 7 SELECT COUNT (* ) FROM tb_emp; SELECT COUNT (job) FROM tb_emp; SELECT MAX (entrydate) FROM tb_emp; SELECT MIN (entrydate) FROM tb_emp; SELECT AVG (id) FROM tb_emp; SELECT SUM (id) FROM tb_emp; SELECT COUNT (* ) FROM tb_emp WHERE gender = 1 ;
5.5 分组查询(GROUP BY) 1 2 3 4 5 SELECT 分组字段, 聚合函数(...)FROM 表名[WHERE 分组前条件] GROUP BY 分组字段[HAVING 分组后条件];
重要规则 :
只要分组,SELECT 后面只能写分组字段和聚合函数 ,写其他字段无意义
只要分组,必须配合聚合函数 使用
WHERE vs HAVING 区别(⭐ 面试常考):
对比项
WHERE
HAVING
执行时机 分组之前 过滤
分组之后 过滤
能否用聚合函数 ❌ 不能
✅ 可以
过滤对象 原始行数据
分组后的结果
1 2 3 4 5 6 7 8 9 SELECT gender, COUNT (* ) FROM tb_emp GROUP BY gender;SELECT job, COUNT (* )FROM tb_empWHERE entrydate <= '2015-01-01' GROUP BY job HAVING COUNT (* ) >= 2 ;
六、综合速查 SQL 执行顺序 1 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
DDL 操作速查 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 SHOW DATABASES;CREATE DATABASE IF NOT EXISTS db_name;USE db_name; DROP DATABASE IF EXISTS db_name;SHOW TABLES;DESC tb_name;SHOW CREATE TABLE tb_name;ALTER TABLE tb_name ADD col_name type [COMMENT '' ];ALTER TABLE tb_name MODIFY col_name new_type;ALTER TABLE tb_name CHANGE old_col new_col type;ALTER TABLE tb_name DROP col_name;RENAME TABLE old_name TO new_name; DROP TABLE IF EXISTS tb_name;
DML 操作速查 1 2 3 4 5 6 7 8 9 10 INSERT INTO tb (col1, col2) VALUES (v1, v2);INSERT INTO tb (col1, col2) VALUES (v1, v2), (v3, v4);UPDATE tb SET col1= v1, update_time= NOW() WHERE 条件;DELETE FROM tb WHERE 条件;TRUNCATE TABLE tb;
DQL 条件运算符速查
场景
用法
等值
= '值'
不等
!= 值 或 <> 值
范围
BETWEEN a AND b
多值
IN (v1, v2, v3)
模糊
LIKE '张%' / LIKE '__'
NULL
IS NULL / IS NOT NULL
复合
AND / OR / NOT
常见注意事项
问题
说明
NULL 比较
不能用 = NULL,只能用 IS NULL
无 WHERE 的 UPDATE/DELETE
会操作整张表 ,开发中必须小心
COUNT(*) vs COUNT(字段)COUNT(*) 推荐,COUNT(字段) 忽略 NULL
CHAR vs VARCHAR
固定长度用 CHAR(性能好),可变长度用 VARCHAR
分组查询 SELECT 字段限制
GROUP BY 后 SELECT 只能写分组字段 + 聚合函数
TRUNCATE vs DELETE
TRUNCATE 效率更高且重置主键,DELETE 可带条件
MySQL 单表查询 · 多表设计 · 多表查询 · 事务 · 索引 · 重点总结 一、单表查询补充 1.1 排序查询(ORDER BY) 1 SELECT 字段列表 FROM 表名 [WHERE 条件] ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;
排序方式
说明
ASC升序(默认 ,可省略不写)
DESC降序
⚠️ 多字段排序时,只有第一个字段值相同 ,才会按第二个字段排序。
1 2 3 4 5 6 7 8 9 SELECT * FROM tb_emp ORDER BY entrydate;SELECT * FROM tb_emp ORDER BY entrydate ASC , update_time DESC ;SELECT * FROM tb_emp WHERE job IS NOT NULL AND entrydate IS NOT NULL ORDER BY job, entrydate DESC ;
1.2 分页查询(LIMIT) 1 SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询条数;
规则
说明
起始索引从 0 开始
起始索引 = (页码 - 1) × 每页条数
第 1 页可省略起始索引
LIMIT 10 等价于 LIMIT 0, 10
MySQL 方言
不同数据库分页语法不同,MySQL 用 LIMIT
1 2 3 4 5 6 7 8 SELECT * FROM tb_emp LIMIT 5 ;SELECT * FROM tb_emp LIMIT 5 , 5 ;SELECT * FROM tb_emp LIMIT 10 , 5 ;
1.3 条件分页综合案例 1 2 3 4 5 6 7 SELECT * FROM tb_empWHERE name LIKE '张%' AND gender = 1 AND entrydate BETWEEN '2000-01-01' AND '2015-12-31' ORDER BY update_time DESC LIMIT 0 , 10 ;
1.4 IF 和 CASE 函数
函数
语法
说明
IFIF(条件, true值, false值)相当于三元运算符,二选一
IFNULLIFNULL(字段, 默认值)字段为 NULL 时返回默认值
CASECASE 字段 WHEN v1 THEN r1 ... ELSE r END相当于 switch,多选一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SELECT IF(gender= 1 , '男性员工' , '女性员工' ) AS 性别, COUNT (* ) AS 人数FROM tb_emp GROUP BY gender;SELECT name, IFNULL(job, '无' ) AS 职位 FROM tb_emp;SELECT COUNT (* ) 人数, CASE job WHEN 1 THEN '班主任' WHEN 2 THEN '讲师' WHEN 3 THEN '学工主管' WHEN 4 THEN '教研主管' ELSE '其他岗位' END AS 职位 FROM tb_emp GROUP BY job;
1.5 DQL 完整执行顺序(⭐ 常考) 1 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
验证依据:在 SELECT 中给字段起的别名,不能 在 WHERE 中使用(因为 WHERE 先于 SELECT 执行),但可以 在 ORDER BY 中使用。
二、多表设计 2.1 三种表关系
关系类型
说明
设计方案
一对多 (多对一)A 表一条数据对应 B 表多条数据(部门—员工)
在多的一方 (从表)添加外键字段,引用主表主键
一对一 两表互相对应一条(用户基本信息—身份信息)
在任意一方 添加外键 + UNIQUE 约束
多对多 A 的一条数据对应 B 的多条,反之亦然(学生—课程)
建立第三张中间表 ,包含两个外键分别关联两表主键
2.2 外键约束 1 2 3 4 5 6 7 8 CREATE TABLE 从表 ( 字段..., [CONSTRAINT 外键名] FOREIGN KEY (外键字段) REFERENCES 主表(主键) ); ALTER TABLE 从表 ADD CONSTRAINT 外键名 FOREIGN KEY (外键字段) REFERENCES 主表(主键);
外键的作用:
删除主表中被引用的数据时 → 报错,无法直接删除 (保证完整性)
添加/修改从表数据时,指定的外键值不存在 → 报错失败 (外键值可以为 NULL)
2.3 物理外键 vs 逻辑外键(⭐ 重要)
对比项
物理外键(FOREIGN KEY)
逻辑外键(业务层控制)
实现方式 数据库层面 DDL 关键字
Java 代码业务逻辑控制
性能 影响增删改效率(每次需检查约束)
不影响 DB 性能
适用场景 单节点数据库
分布式、集群场景
死锁风险 可能引发死锁
无
企业现状 很少使用,部分规范明确禁止 主流做法
2.4 三种关系建表示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ALTER TABLE tb_emp ADD CONSTRAINT fk_dept_id FOREIGN KEY (dept_id) REFERENCES tb_dept(id);CREATE TABLE tb_user_card ( ... user_id INT UNSIGNED NOT NULL UNIQUE COMMENT '用户ID' , CONSTRAINT fk_user_id FOREIGN KEY (user_id) REFERENCES tb_user(id) ); CREATE TABLE tb_student_course ( id INT AUTO_INCREMENT PRIMARY KEY, student_id INT NOT NULL , course_id INT NOT NULL , CONSTRAINT fk_student FOREIGN KEY (student_id) REFERENCES tb_student(id), CONSTRAINT fk_course FOREIGN KEY (course_id) REFERENCES tb_course(id) );
三、多表查询 3.1 笛卡尔积与消除
笛卡尔积 :直接查询两张表时,A 表每条记录与 B 表所有记录组合,产生 A行数 × B行数 条无效数据。
1 2 3 4 5 SELECT * FROM tb_emp, tb_dept;SELECT * FROM tb_emp, tb_dept WHERE tb_emp.dept_id = tb_dept.id;
3.2 多表查询三大分类
类型
结果
语法关键字
内连接 A ∩ B(两表交集,只显示匹配的行)
JOIN ... ON 或 FROM A, B WHERE
左外连接 左表全部 + 右表匹配部分(右表无匹配显示 NULL)
LEFT JOIN ... ON
右外连接 右表全部 + 左表匹配部分(左表无匹配显示 NULL)
RIGHT JOIN ... ON
子查询 嵌套 SELECT,将内层结果作为外层条件或表
SELECT ... (SELECT ...)
3.3 内连接
写法
语法
说明
隐式内连接 FROM 表1, 表2 WHERE 关联条件结果完全相同,写法不同
显式内连接 FROM 表1 [INNER] JOIN 表2 ON 关联条件更清晰,推荐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 SELECT e.name 姓名, d.name 部门FROM tb_emp e, tb_dept dWHERE e.dept_id = d.id;SELECT e.name 姓名, d.name 部门FROM tb_emp e INNER JOIN tb_dept dON e.dept_id = d.id;SELECT e.name, d.name, e.entrydateFROM tb_emp e JOIN tb_dept dON e.dept_id = d.idWHERE YEAR (e.entrydate) < 2010 ;
⚠️ 给表起别名后,只能用别名引用字段 ,不能再用原表名。
3.4 外连接 1 2 3 4 5 6 7 8 9 10 11 12 SELECT e.name, d.nameFROM tb_emp e LEFT JOIN tb_dept d ON e.dept_id = d.id;SELECT e.name, d.nameFROM tb_emp e RIGHT JOIN tb_dept d ON e.dept_id = d.id;SELECT e.name, d.name FROM tb_emp e LEFT JOIN tb_dept d ON e.dept_id = d.idUNION ALL SELECT e.name, d.name FROM tb_emp e RIGHT JOIN tb_dept d ON e.dept_id = d.id;
UNION vs UNION ALL:
UNION:合并结果集,去除重复行 UNION ALL:合并结果集,保留所有行 (性能更高)
左右外连接可以互相转换(调换表的前后顺序),日常开发更偏向左外连接 。
3.5 子查询 子查询可以出现的位置: WHERE 之后 / FROM 之后 / SELECT 之后
子查询类型
结果形式
常用操作符
使用方式
标量子查询 单值(一行一列)
= <> > < >= <=当作一个具体的值使用
列子查询 一列多行
IN NOT IN ANY ALL当作 IN (...) 的列表使用
行子查询 一行多列
= <> IN NOT IN用 () 包裹多列进行比较
表子查询 多行多列
IN,配合 JOIN当作临时表,继续 JOIN 查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 SELECT * FROM tb_empWHERE dept_id = (SELECT id FROM tb_dept WHERE name = '教研部' );SELECT * FROM tb_empWHERE dept_id IN (SELECT id FROM tb_dept WHERE name IN ('教研部' , '咨询部' ));SELECT * FROM tb_empWHERE (entrydate, job) = (SELECT entrydate, job FROM tb_emp WHERE name = '韦一笑' );SELECT IFNULL(ls.人数, 0 ) 人数, d.name 部门名称FROM tb_dept dLEFT JOIN ( SELECT COUNT (* ) 人数, dept_id FROM tb_emp WHERE dept_id IS NOT NULL GROUP BY dept_id ) ls ON ls.dept_id = d.id; SELECT name, price FROM dishWHERE price < (SELECT AVG (price) FROM dish);
四、事务 4.1 核心概念
项目
说明
定义 一组 SQL 操作的集合,作为不可分割的整体 ,要么全部成功,要么全部失败
典型场景 银行转账(扣款 + 到账 必须同时成功或同时回滚);删部门同时删员工
提交方式 自动提交(默认,每条 SQL 自动提交);手动提交 (显式 BEGIN + COMMIT/ROLLBACK)
4.2 事务操作 SQL
SQL
说明
START TRANSACTION; 或 BEGIN;开启手动事务
COMMIT;提交 事务(所有操作永久生效)
ROLLBACK;回滚 事务(所有操作撤销,恢复原状)
1 2 3 4 5 6 7 8 9 10 11 START TRANSACTION;DELETE FROM tb_dept WHERE id = 1 ; DELETE FROM tb_emp WHERE dept_id = 1 ; COMMIT ;ROLLBACK ;
4.3 事务四大特性 ACID(⭐ 面试必考)
特性
英文
说明
转账例子
原子性 Atomicity
不可分割,要么全成功,要么全失败
扣款和到账不能只做一半
一致性 Consistency
事务前后数据逻辑完整性保持一致
转账前后 A+B 总金额不变
隔离性 Isolation
并发事务互不干扰,独立运行
你转账和别人转账互不影响
持久性 Durability
提交后数据永久保存,不会丢失
转账成功后数据库崩溃重启仍然有效
4.4 并发问题三大坑(⭐ 面试常考)
问题
定义
根本原因
例子
脏读 读到另一事务未提交 的数据
别人可能回滚,你读到的是无效数据
账户余额被临时修改为 1500,你读到了,结果对方回滚,余额还是 1000
不可重复读 同一事务内,两次读同一行 结果不同
别人修改并提交 了该行数据
你查余额 1000,老婆取走 500 提交,你再查变成 500
幻读 同一事务内,按条件查询行数 不同
别人新增/删除 了符合条件的行
你查没有 2026001 号学生,准备插入,却发现已存在(别人先插了)
不可重复读 vs 幻读:
不可重复读 → 针对同一行的 UPDATE ,同一行数据内容变了
幻读 → 针对INSERT/DELETE ,行数变了(多了或少了行)
4.5 事务隔离级别(⭐ 面试必考)
隔离级别
脏读
不可重复读
幻读
性能
READ UNCOMMITTED(读未提交)✅ 有
✅ 有
✅ 有
最高
READ COMMITTED(读已提交)❌ 无
✅ 有
✅ 有
高
REPEATABLE READ(可重复读)❌ 无
❌ 无
⚠️ 基本解决
中(MySQL 默认 )
SERIALIZABLE(串行化)❌ 无
❌ 无
❌ 无
最低
⚠️ MySQL InnoDB 在 REPEATABLE READ 级别下通过间隙锁 机制,已经在很大程度上解决了幻读问题。
1 2 3 4 5 6 SELECT @@TRANSACTION_ISOLATION ;SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
五、索引 5.1 核心概念
项目
说明
定义 帮助数据库高效获取数据 的数据结构,本质上是有序的数据结构
无索引查询 全表扫描(从第一行扫到最后一行),数据量大时极慢
有索引查询 通过树结构快速定位,千万数据只需 3 次 IO
5.2 索引优缺点
方面
说明
优点 极大提高查询效率 ,降低 IO 成本;降低排序 CPU 消耗
缺点 占用磁盘空间 ;降低 INSERT / UPDATE / DELETE 效率 (维护索引需要额外开销)
5.3 索引结构
索引结构
特点
支持引擎
B+Tree(最常用) 多路平衡搜索树,叶子节点双向链表,支持范围查询和排序
InnoDB / MyISAM / Memory
Hash
精确匹配极快,不支持范围查询 ,不支持排序
Memory(InnoDB 自适应)
R-tree(空间索引)
地理空间数据
MyISAM
Full-text(全文索引)
倒排索引,类似 ES
InnoDB(5.6+) / MyISAM
B+Tree 结构特点:
特点
说明
每节点存多个 key
宽度大,树高度低(千万数据树高 ≤ 3)
数据只在叶子节点
非叶子节点仅存 key+指针,用于快速索引
叶子节点双向链表
支持范围查询(BETWEEN)和排序
查询效率稳定
所有数据查找路径长度相同(都在叶子层)
为何 InnoDB 选 B+Tree 而不是红黑树? 红黑树是二叉树 ,数据量大时树高太高(100W 数据树高约 23),磁盘 IO 次数多;B+Tree 每节点可存 1170 个元素,3 层可覆盖 2000W+ 数据。
5.4 索引操作 SQL
操作
语法
创建普通索引
CREATE INDEX 索引名 ON 表名(字段名);
创建唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名(字段名);
查看索引
SHOW INDEX FROM 表名;
删除索引
DROP INDEX 索引名 ON 表名;
1 2 3 4 5 6 7 8 CREATE INDEX idx_emp_name ON tb_emp(name);SHOW INDEX FROM tb_emp;DROP INDEX idx_emp_name ON tb_emp;
自动创建索引的情况:
添加 PRIMARY KEY → 自动创建主键索引
添加 UNIQUE 约束 → 自动创建唯一索引
六、综合速查 DQL 完整语法模板 1 2 3 4 5 6 7 SELECT 字段列表FROM 表名WHERE 条件 GROUP BY 分组字段HAVING 分组后条件 ORDER BY 字段1 ASC | DESC , 字段2. .. LIMIT 起始索引, 条数;
多表查询选型
需求
选用
只查两表都有匹配的数据
内连接
要查左表所有数据(右表无匹配显示 NULL)
左外连接
要查右表所有数据
右外连接
子查询结果是单个值
标量子查询 (= (SELECT ...)))
子查询结果是一列多行
列子查询 (IN (SELECT ...)))
子查询结果是一行多列
行子查询 ((col1,col2) = (SELECT ...)))
子查询结果是多行多列(临时表)
表子查询 (FROM (SELECT ...) t)
事务四大特性口诀 1 2 3 4 A(原子) → 全成功/全失败,不可分割 C(一致) → 数据逻辑完整性始终保持 I(隔离) → 并发事务互不干扰 D(持久) → 提交后永久生效,数据库崩溃也不丢
隔离级别选型
场景
推荐隔离级别
普通 Web 应用(默认即可)
REPEATABLE READ(MySQL 默认)
需要读最新已提交数据(Oracle 风格)
READ COMMITTED
最高数据一致性、极低并发
SERIALIZABLE
索引使用建议
适合建索引
不适合建索引
经常出现在 WHERE、ORDER BY、GROUP BY 的字段
数据量很小的表
主键字段(自动创建)
频繁 INSERT/UPDATE/DELETE 的字段
唯一约束字段(自动创建)
重复值很多的字段(如性别字段)
JDBC · 连接池(Druid) · 重点总结 一、JDBC 概述 1.1 核心概念
项目
说明
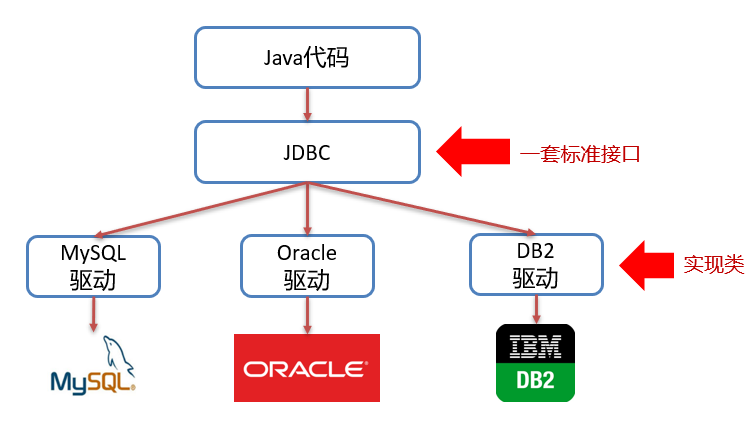
全称 Java DataBase Connectivity(Java 数据库连接)
本质 Sun 公司定义的一套操作所有关系型数据库的标准接口
驱动 各数据库厂商实现 JDBC 接口提供的 jar 包 (如 MySQL 驱动包)
好处 同一套 Java 代码可操作不同数据库;更换数据库时代码基本不变
1.2 JDBC 与驱动的关系 1 2 3 4 5 6 7 Java 代码 → 面向 JDBC 接口编程 ↓ JDBC(标准接口) ↓ MySQL 驱动 jar 包(实现类) ↓ MySQL 数据库服务器
二、JDBC 七步流程(⭐ 核心)
步骤
操作
代码
① 注册驱动
加载数据库驱动(MySQL 8+ 可省略)
Class.forName("com.mysql.cj.jdbc.Driver");
② 获取连接
通过 DriverManager 建立数据库连接
Connection conn = DriverManager.getConnection(url, user, pwd);
③ 编写 SQL
定义要执行的 SQL 字符串
String sql = "SELECT * FROM tb";
④ 获取执行者
创建 Statement 或 PreparedStatement
Statement st = conn.createStatement();
⑤ 执行 SQL
执行增删改或查询
st.executeUpdate(sql) / st.executeQuery(sql)
⑥ 处理结果
处理影响行数或遍历 ResultSet
while(rs.next()){ rs.getString("col"); }
⑦ 释放资源
关闭资源(顺序:ResultSet → Statement → Connection)
rs.close(); st.close(); conn.close();
三、JDBC 核心 API 详解 3.1 DriverManager(驱动管理类)
方法
说明
DriverManager.getConnection(url, user, pwd)获取数据库连接对象 Connection
Class.forName("驱动类全名")注册驱动(MySQL 5+ 可自动加载,可省略 )
URL 格式:
1 2 3 4 jdbc:mysql://IP地址:端口号/数据库名?参数1&参数2 // 连接本机 3306 端口,可简写 jdbc:mysql:///数据库名?useSSL=false
3.2 Connection(连接对象)
方法
说明
createStatement()创建普通 SQL 执行对象(可能有 SQL 注入风险)
prepareStatement(sql)创建预编译 SQL 执行对象(推荐,防注入 )
setAutoCommit(false)关闭自动提交,开启手动事务
commit()提交事务
rollback()回滚事务
3.3 Statement vs PreparedStatement(⭐ 常考)
对比项
Statement
PreparedStatement(推荐)
SQL 写法
直接拼字符串
用 ? 占位符
SQL 注入
❌ 存在漏洞
✅ 防止注入 (敏感字符转义)
性能
每次执行都重新编译
预编译 ,同模板只编译一次,性能更高
参数设置
无
setString(1, value) / setInt(1, value)
适用场景
固定 SQL、DDL
几乎所有场景,尤其是带参数的 DML/DQL
SQL 注入示例:
1 2 3 用户输入密码:' or '1' = '1 拼接后SQL:SELECT * FROM user WHERE pwd = '' or '1'='1' → 条件永远为 true,绕过验证!
3.4 Statement 方法
方法
说明
返回值
executeUpdate(sql)执行 DDL / DML (CREATE/INSERT/UPDATE/DELETE)
int(受影响的行数)
executeQuery(sql)执行 DQL (SELECT)
ResultSet(结果集对象)
3.5 PreparedStatement 方法
方法
说明
setString(paramIndex, value)给第 N 个 ? 设置 String 值
setInt(paramIndex, value)给第 N 个 ? 设置 int 值
setDouble(paramIndex, value)给第 N 个 ? 设置 double 值
executeUpdate()执行增删改(无参,SQL 已在 prepareStatement 中传入)
executeQuery()执行查询(无参)
3.6 ResultSet(结果集对象)
方法
说明
next()光标向下移一行,有数据返回 true,无数据返回 false
getString(列名/索引)获取当前行指定列的 String 值
getInt(列名/索引)获取当前行指定列的 int 值
getDouble(列名/索引)获取当前行指定列的 double 值
getObject(列名/索引)获取任意类型值
ResultSet 初始时光标在第一行上方 ,每次 next() 才移到下一行数据上。
四、JDBC 完整代码模板 4.1 增删改(PreparedStatement) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Connection conn = DriverManager.getConnection( "jdbc:mysql:///db1?useSSL=false" , "root" , "1234" ); String sql = "INSERT INTO tb_brand VALUES (null, ?, ?, ?, ?, ?)" ;PreparedStatement pst = conn.prepareStatement(sql);pst.setString(1 , "华为" ); pst.setString(2 , "华为技术有限公司" ); pst.setInt(3 , 100 ); pst.setString(4 , "构建万物互联的智能世界" ); pst.setInt(5 , 1 ); int rows = pst.executeUpdate(); System.out.println("影响行数:" + rows); pst.close(); conn.close();
4.2 查询(ResultSet 遍历) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Connection conn = DriverManager.getConnection( "jdbc:mysql:///db1?useSSL=false" , "root" , "1234" ); String sql = "SELECT * FROM tb_brand WHERE status = ?" ;PreparedStatement pst = conn.prepareStatement(sql);pst.setInt(1 , 1 ); ResultSet rs = pst.executeQuery();List<Brand> list = new ArrayList <>(); while (rs.next()) { int id = rs.getInt("id" ); String brandName = rs.getString("brand_name" ); String compName = rs.getString("company_name" ); int status = rs.getInt("status" ); list.add(new Brand (id, brandName, compName, status)); } rs.close(); pst.close(); conn.close();
4.3 事务控制(JDBC 中的事务) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Connection conn = DriverManager.getConnection(url, user, pwd);conn.setAutoCommit(false ); try { PreparedStatement pst1 = conn.prepareStatement("UPDATE account SET money=money-500 WHERE id=1" ); pst1.executeUpdate(); PreparedStatement pst2 = conn.prepareStatement("UPDATE account SET money=money+500 WHERE id=2" ); pst2.executeUpdate(); conn.commit(); } catch (Exception e) { conn.rollback(); throw new RuntimeException (e); } finally { conn.close(); }
五、数据库连接池 5.1 为什么需要连接池
问题(无连接池)
解决(有连接池)
每次请求都 new Connection
连接预先创建好,直接复用
每次用完都销毁 Connection
用完归还 ,不销毁
频繁创建/销毁耗费性能和时间
响应速度快 ,资源利用率高
连接数量无法控制,可能耗尽数据库资源
限制最大连接数 ,避免连接遗漏
5.2 常见连接池对比
连接池
特点
DBCP
Apache 出品,较老
C3P0
较老,性能一般
Druid(德鲁伊) 阿里开源,性能最优,最常用 ;提供监控功能
标准接口 :javax.sql.DataSource,所有连接池都实现此接口,通过 getConnection() 获取连接。
5.3 Druid 连接池使用五步骤
步骤
操作
① 写配置文件
在 src 下新建 druid.properties,填写数据库和连接池参数
② 创建 Properties 对象
Properties p = new Properties();
③ 加载配置文件
用类加载器读取,p.load(inputStream);
④ 创建连接池
DataSource source = DruidDataSourceFactory.createDataSource(p);
⑤ 获取/归还连接
获取:source.getConnection();归还:conn.close()(不是真正关闭,是归还到池中 )
5.4 druid.properties 配置文件 1 2 3 4 5 6 7 8 9 10 11 12 driverClassName =com.mysql.jdbc.Driver url =jdbc:mysql:///db1?useSSL=false&useServerPrepStmts=true username =root password =1234 initialSize =5 maxActive =10 maxWait =3000
5.5 Druid 完整代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public class DruidDemo { private static DataSource dataSource; static { try { Properties p = new Properties (); InputStream is = ClassLoader.getSystemClassLoader() .getResourceAsStream("druid.properties" ); p.load(new InputStreamReader (is, "UTF-8" )); dataSource = DruidDataSourceFactory.createDataSource(p); } catch (Exception e) { throw new RuntimeException (e); } } public static void main (String[] args) throws Exception { Connection conn = dataSource.getConnection(); String sql = "SELECT * FROM tb_brand" ; PreparedStatement pst = conn.prepareStatement(sql); ResultSet rs = pst.executeQuery(); while (rs.next()) { System.out.println(rs.getInt("id" ) + " | " + rs.getString("brand_name" )); } rs.close(); pst.close(); conn.close(); } } 程序启动 → 类加载 → 执行 static 块: └─ 读 druid.properties └─ 创建 Druid 连接池(池子里预先创建了几个连接) └─ 把池子赋值给 static 变量 dataSource 执行 main: └─ dataSource.getConnection() → 从池子借一个连接 └─ 执行 SQL 查询 └─ 打印结果 └─ conn.close() → 连接归还到池子(不是真关闭) 程序结束 → 连接池随着 JVM 退出而销毁,所有物理连接才真正关闭
六、综合对比速查 JDBC 完整 API 速查
类/接口
获取方式
核心方法
ConnectionDriverManager.getConnection(url, user, pwd)prepareStatement(sql) / setAutoCommit / commit / rollback
PreparedStatementconn.prepareStatement(sql)setXxx(index, value) / executeUpdate() / executeQuery()
Statementconn.createStatement()executeUpdate(sql) / executeQuery(sql)
ResultSetpst.executeQuery()next() / getXxx(列名)
DataSourceDruidDataSourceFactory.createDataSource(p)getConnection()
Statement vs PreparedStatement 核心区别 1 2 3 4 5 6 7 8 Statement(不推荐): String sql = "SELECT * WHERE name = '" + name + "'"; → 用户输入 ' or '1'='1,SQL语义被改变! PreparedStatement(推荐): String sql = "SELECT * WHERE name = ?"; pst.setString(1, name); → ? 处的内容永远是参数,不会改变SQL结构,安全!
连接池 Connection.close() 的真相 1 2 3 4 无连接池时:conn.close() → 真正关闭,销毁连接对象 使用连接池后:conn.close() → 归还连接到池中,供下次复用 池子的 close() 才是真正关闭整个连接池
JDBC 操作方法选型
操作类型
使用方法
返回值
INSERT / UPDATE / DELETE
executeUpdate()int(受影响行数 > 0 表示成功)
SELECT 查询
executeQuery()ResultSet(遍历用 next())
CREATE / DROP 等 DDL
executeUpdate()int(通常为 0)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 public class Test09 { private static Connection conn = null ; private static DataSource source = null ; static { try { Properties p = new Properties (); InputStreamReader reader = new InputStreamReader (ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties" ), "utf-8" ); p.load(reader); source= DruidDataSourceFactory.createDataSource(p); } catch (Exception e) { throw new RuntimeException (e); } } public static void main (String[] args) throws Exception { conn = source.getConnection(); Brand brand = new Brand (0 ,"卫龙辣条" ,"卫龙集团" ,100 ,"麻辣" ,1 ); int i = insertBrand(brand); System.out.println("添加的结果:" +i); conn = source.getConnection(); List<Brand> brands = selectAll(); System.out.println(brands); } private static int insertBrand (Brand brand) throws Exception { conn.setAutoCommit(false ); PreparedStatement pst = conn.prepareStatement("insert into tb_brand values (?,?,?,?,?,?)" ); pst.setInt(1 ,0 ); pst.setString(2 ,brand.getBrandName()); pst.setString(3 , brand.getCompanyName()); pst.setInt(4 ,brand.getOrdered()); pst.setString(5 , brand.getDescription()); pst.setInt(6 ,brand.getStatus()); int i = pst.executeUpdate(); pst.close(); conn.commit(); conn.close(); return i; } private static List<Brand> selectAll () throws Exception { String sql = "select * from tb_brand" ; Statement statement = conn.createStatement(); ResultSet set = statement.executeQuery(sql); List<Brand> list = new ArrayList <>(); while (set.next()){ int id = set.getInt("id" ); String name = set.getString("brand_name" ); String company_name = set.getString("company_name" ); int order = set.getInt("ordered" ); String description = set.getString("description" ); int status = set.getInt("status" ); Brand brand = new Brand (id,name,company_name,order,description,status); list.add(brand); } set.close(); statement.close(); conn.close(); return list; } }