
总结
总结
SmithRAG 基础原理
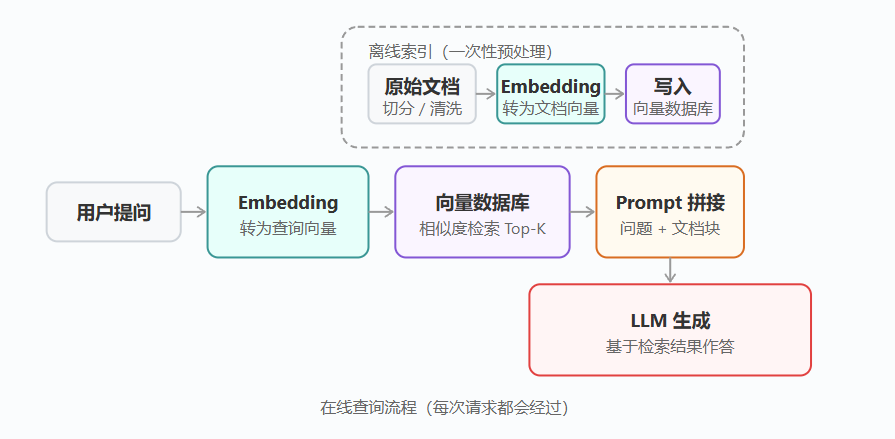
一个完整的 RAG 系统由两条流水线组成:离线索引流水线(将文档预处理存入向量库)和在线查询流水线(接收用户问题、检索、生成)。
离线阶段将原始文档切分成小块,通过 Embedding 模型转换为向量,存入向量数据库。
在线阶段将用户问题同样转换为向量,从数据库中找到最相近的文档块,拼接成上下文交给 LLM 生成答案。
https://www.runoob.com/ai-agent/retrieval-augmented-generation.html
MCP
LLM
前端
这个项目的前端,
用 Vue 3 的最新推荐写法来保证代码结构清晰,
用 Vite 这个新一代工具来构建(类比于maven,构建打包(Build) 压缩、整合代码)
热更新就是类似“改完代码自动重启生效”但更快更精准的效果;
冷启动就像把一个需要 30 秒启动的 Java 应用优化到 1 秒以内
Pinia 就是让你用 Vue 3 写组件的方式去写全局数据仓库,它轻量、类型安全,并且完美替代了旧的 Vuex,成为目前 Vue 项目中管理全局状态的“标配”。
按需引入 组件只引入需要的 store,减少打包体积
TypeScript 类型安全 完整的类型定义,IDE 自动补全,错误提前发现
持久化 自动保存到 localStorage,刷新不丢失
简洁易用 去掉 mutations,直接在 actions 里改状态,代码更清晰
dense_vector 就是 ES 中专门存储机器学习向量的字段,
kNN 向量检索则是在这些向量上找最相似的 k 个邻居,让 ES 从“找关键词”进化为“找语义相似的内容”。K近邻
结合 Java 与模型 API,就能轻松构建现代化的智能搜索应用。
Token 的本质:它就是一张“临时身份证”。用户登录成功后,服务器生成一个全局唯一、难以伪造的长字符串,作为用户的身份标识。
UUID:这里采用 UUID(通用唯一识别码)算法生成 Token,比如 a1b2c3d4-e5f6-…。它能保证全世界唯一,不会和别人重复。
为什么要颁发?:HTTP 协议是无状态的,服务器无法记住“上一次请求是谁发的”。所以必须在登录成功后,把 Token 返回给客户端,让客户端暂存起来。
FAQ(Frequently Asked Questions,常见问题解答)是一种结构化的知识载体,由一个问题(Q)和一个标准答案(A)组合而成,例如:
Q:“如何修改密码?”
A:“登录后进入个人中心,点击修改密码,输入新旧密码即可。”
它是企业客服系统、帮助中心中最常见的知识形态,比非结构化的长篇文档更精炼、直接。
性能指标
- 系统API接口平均响应时间 < 200ms
合理性:优秀水平
- 这是通用的“快”标准,人类感知延迟的阈值约 100-200ms。
- 你的
Result统一响应封装、Spring Boot + MySQL 增删改查,只要不出现N+1查询或大循环,索引用得好,达到此值难度适中。 - 验证:用 JMeter 或 wrk 压测,统计平均 RT(Response Time)。
- Java 侧确保手段:数据库索引、连接池(HikariCP)、开启 MyBatis 二级缓存、对热点数据用 Redis 缓存。
- AI流式对话首Token响应时间 < 3秒
合理性:符合业务预期
- LLM 生成回答前,必须先完成 RAG 向量检索 + Prompt 拼接 + 模型推理启动。
- 3 秒是用户能接受的“思考等待”上限。实际上,这个时间主要花在模型推理上,向量检索(ES kNN)本身应在 50ms 以内。
- 注意:“流式对话”意味着使用 SSE(Server-Sent Events)或 WebSocket 逐字返回,首 Token 是指第一个字出现的时间,而非完整回答。
- Java 侧确保:向量检索优化(ES 分片、HNSW 参数调优),调用 LLM API 时用 WebClient 异步非阻塞,避免阻塞内置 Tomcat 线程。
- Elasticsearch 商品检索 QPS ≥ 100
合理性:较保守,单节点即可达到
- 100 QPS(每秒查询数)对 ES 来说非常低。一个标准 3 节点集群,单索引正确配置分片与副本,轻松支撑数千 QPS。
- 你的 Java 项目使用 Spring Data Elasticsearch 或 High Level REST Client 查询
dense_vector或普通关键词,只要连接池配置合理,100 QPS 不会出问题。 - 验证:用 JMeter 或
ab对/search接口压测,观察 ES 的 CPU 和线程池状态(_cat/thread_pool)。
- Netty WebSocket 服务 ≥ 500 路并发长连接稳定运行
合理性:合理且必要
- 500 路并发长连接对 Netty 来说非常小(Netty 原生可轻松处理数十万连接)。
- 此指标通常用于在线聊天室、实时推送、流式对话返回等场景,比如你的 AI 流式对话就可能通过 WebSocket 推送 Token。
- Java 侧确保:
- 正确设置
SO_BACKLOG、TCP_NODELAY。 - 控制每条连接的内存占用,防止空闲连接浪费。
- 用心跳机制检测僵死连接并剔除。
- 避免在连接 EventLoop 线程上执行阻塞操作。
- 正确设置
- 验证:用专门的 WebSocket 压测工具(如
websocat、JMeter WebSocket 插件、或wrk配合 Lua 脚本)模拟 500+ 连接,查看 CPU、内存、网络连接数(netstat -an|grep 端口|wc -l),确保不掉线无异常。
总结:这组性能指标合理
它们覆盖了 快速增删改查、智能搜索、长连接实时性 三大典型挑战,形成了完整闭环。对个人项目或初创企业应用,这是合格的性能基线,也是你项目答辩时有力的质量佐证。
不过在实现时建议:
- 所有接口都加上性能监控(Spring Actuator + Micrometer + Prometheus),用数据说明达标情况。
- 对 AI 流式对话,最好设计为异步非阻塞架构(WebFlux 或 Servlet 3.0 异步),避免阻塞连接池。
💡 一句话总结
这四条安全需求是为你的后端系统穿上了四层铠甲:
密码加盐哈希 → 保护用户凭证,即使数据库泄露也无法反推密码。
Redis 存 UUID Token + 过期 → 构建可随时吊销、防伪的身份认证体系。
RSA2 签名验签 → 确保支付回调的权威性,防止伪造通知导致财务损失。
输入校验 → 过滤恶意代码,防止系统被注入攻击或植入脚本。
3.2.3
- 用户密码采用 MD5 哈希算法加盐存储,防止彩虹表攻击
- 加盐:
- 由于大家常用弱密码(如
123456),黑客可以提前算好所有常见密码的哈希值,做成“彩虹表”,一对照就破解了。 - 加盐就是给每个用户生成一个随机的额外字符串(盐),拼在密码后面再哈希:
MD5(password + salt)。 - 这样,即使两个用户密码完全相同,由于盐不同,他们数据库里存的哈希值也完全不同,彩虹表彻底失效。
- 由于大家常用弱密码(如
- Token 采用 UUID 规范签发,过期时间 2 小时,存储于 Redis 以便服务端主动失效
- UUID 规范签发:使用
java.util.UUID算法生成全球唯一的随机字符串,无法被遍历或伪造。 - 过期时间 2 小时:每签发一个 Token,在 Redis 里设置
EXPIRE 7200。超时后,Redis 自动删除这条记录,即使 Token 字面量正确,拦截器也查不到,认证失败。 - 存储于 Redis:Token 存在服务端的内存数据库里,而不是只存在于客户端,这样就有了核心的控制能力——服务端主动失效:
- 用户点击“退出登录”,后端直接删除 Redis 里的 Token 键,那张“临时身份证”立刻作废。
- 用户修改密码后,可以令所有旧 Token 一次性失效。
- 支付宝回调通知进行 RSA2 签名验证,防止伪造通知
这是处理支付回调的核心安全步骤。
- 场景:用户支付成功后,支付宝会向你的后端服务器发一个 HTTP 通知(回调),告知“订单号 123 已支付”。然后你的系统才能更新订单状态为已付款。
- 威胁:黑客可以伪造一个和支付宝一模一样的请求,发给你说“订单 123 已支付”,如果你的系统直接相信,就发货了,但钱其实没到账。
- RSA2 签名验证:
- 支付宝发的每个回调请求,都附带一个数字签名。这个签名是通过支付宝的私钥对请求参数加密生成的。
- 你的系统需要用支付宝公钥对这个签名进行解密,然后和请求参数原文进行对比。
- 只要验证通过,就能百分百确认这条通知确实来自支付宝,并且在传输过程中没有被篡改。
- 对用户输入进行合法性校验,防范 SQL 注入与 XSS 攻击
这是保护系统不被“注入恶意代码”的最后的防线。
- SQL 注入:
- 攻击者在输入框键入
' OR '1'='1,如果后端用字符串拼接构造 SQL:SELECT * FROM users WHERE name='' OR '1'='1',这会导致查出了所有用户。 - 防御:你的项目如果使用 MyBatis 的
#{ }占位符(预编译),MyBatis 会自动过滤掉这些恶意的 SQL 关键词,从根源上杜绝注入。如果你用了 MyBatis-Plus 的 QueryWrapper,也是一样安全的。
- 攻击者在输入框键入
- XSS(跨站脚本攻击):
- 攻击者在输入框写入
<script>偷取Cookie的代码</script>,如果系统直接把这个存起来并在其他用户的浏览器上原样展示,该脚本就会被执行,导致用户信息泄露。 - 防御:对所有用户输入,在写入数据库前或返回给前端前,进行HTML 转义,把
<变成<,>变成>,这样浏览器就会把它当作文本显示,而不是当作可执行的脚本。
- 攻击者在输入框写入
💡 一句话总结
这四条安全需求是为你的后端系统穿上了四层铠甲:
- 密码加盐哈希 → 保护用户凭证,即使数据库泄露也无法反推密码。
- Redis 存 UUID Token + 过期 → 构建可随时吊销、防伪的身份认证体系。
- RSA2 签名验签 → 确保支付回调的权威性,防止伪造通知导致财务损失。
- 输入校验 → 过滤恶意代码,防止系统被注入攻击或植入脚本。
5.1.2
Spring MVC 提供的 “配置工具箱”,我们用它来全局开启 CORS(跨域资源共享),告诉浏览器 “允许这个前端访问我”。
@RestControllerAdvice 是一个全局拦截器,能拦截所有 Controller 抛出的异常,统一处理成 JSON 格式返回给前端。
这段代码做了 5 件事:
查用户:根据邮箱从数据库捞用户信息;
严校验:查账号是否存在、密码对不对、账号有没有被封;
更新记录:把用户这次的登录 IP、时间写到数据库;
发 “通行证”:生成 Token 并把用户信息存到 Redis;
返回结果:把带 Token 的用户信息扔给前端。
// 登录核心逻辑
public TokenUserInfoDTO login(String email, String password, String ip) {
// 【1】根据邮箱查数据库:看有没有这个用户
UserInfo userInfo = userInfoMapper.selectByEmail(email);
// 【2】第一层校验:账号存在吗?密码对吗?
if (userInfo == null || !userInfo.getPassword().equals(password))
throw new BusinessException("账号或密码错误");
// 【3】第二层校验:账号是不是被禁用了(比如违规被封)
if (UserStatusEnum.DISABLE.getStatus().equals(userInfo.getStatus()))
throw new BusinessException("账号已禁用");
// 【4】更新用户的“最后登录信息”(IP、时间)
userInfoMapper.updateByUserId(buildUpdateInfo(ip), userInfo.getUserId());
// 【5】对象拷贝:把数据库查出来的UserInfo“瘦身”成只给前端看的TokenUserInfoDTO
TokenUserInfoDTO tokenDto = CopyTools.copy(userInfo, TokenUserInfoDTO.class);
// 【6】把Token和用户信息存到Redis(背景里说用UUID生成Token,应该在这步里做)
redisComponent.saveTokenInfo(tokenDto);
// 【7】返回给前端
return tokenDto;
}
动态构建ES查询语句,将筛选、排序与分页逻辑下放
数据库只负责「存原始商品数据」(比如商品详情、库存);
ES 负责「搜、筛、排、分页」(ES 是分布式的,天生擅长这个);
结果:数据库压力降低 90%,页面响应速度从 “秒级” 变 “毫秒级”。
5.2.4
(比如 iPhone 15 选「黑色 + 128G」还是「白色 + 256G」),要算两条独立的购物车项。因此用这三个 ID 的组合作为 “唯一标识”,避免属性混淆
Elasticsearch
分词 倒排索引
IK分词器 专门为中文设计的
一、Elasticsearch 是什么?
Elasticsearch(简称 ES)是一个分布式、RESTful 风格的搜索和数据分析引擎,基于 Apache Lucene 构建。它解决的核心问题是:如何从海量数据中快速找到所需信息,并进行复杂的聚合统计。
传统关系型数据库(如 MySQL)处理模糊查询(LIKE '%关键词%')时效率低下,并且难以实现复杂的全文检索、相关性排序、分词搜索等功能。ES 则专门为此而生。
二、核心概念(对照数据库更好理解)
| Elasticsearch | 关系型数据库 | 说明 |
|---|---|---|
| Index(索引) | Database | 存放一类文档的容器,如 products 索引存商品 |
| Document(文档) | Row | 一条 JSON 数据,如一个商品的详情 |
| Field(字段) | Column | 文档中的属性,如 name、price |
| Mapping(映射) | Schema | 定义字段的存储类型、分词器等 |
| Shard(分片) | 分库分表 | 索引可以被切分成多个分片,分布在多台服务器上 |
| Replica(副本) | 主从复制 | 每个分片的冗余副本,用于故障恢复和负载均衡 |
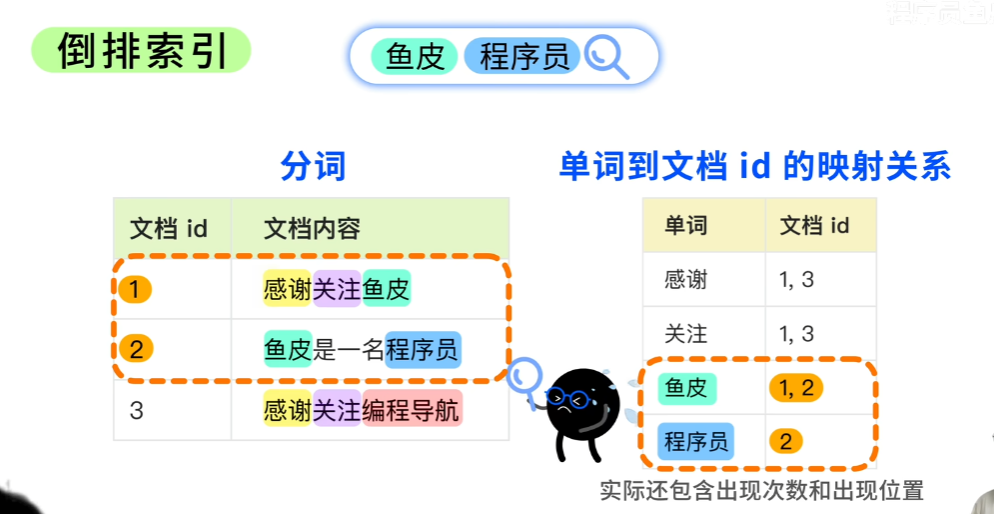
三、为什么搜索这么快?——倒排索引
ES 的核心魔法是倒排索引。
正向索引:文档 → 包含哪些单词。
倒排索引:单词 → 出现在哪些文档中。
例子:
文档1:“Java 高级编程”
文档2:“Java 入门教程”
文档3:“Python 入门教程”
倒排索引库:
| 词条 | 文档列表 |
|---|---|
Java |
文档1, 文档2 |
入门 |
文档2, 文档3 |
教程 |
文档2, 文档3 |
高级 |
文档1 |
编程 |
文档1 |
Python |
文档3 |
当用户搜索 “Java 入门” 时,先分词为 “Java” 和 “入门”,分别查倒排索引得到文档列表,做交集并计算相关性得分,快速返回文档2,整个过程无需全表扫描。
四、典型应用场景 + 举例
1. 电商商品搜索(全文检索)
- 场景:淘宝搜索“红色 大码 连衣裙”。
- ES 实现:对商品标题、描述等字段建立索引,配置中文分词器(如 IK),用户输入后被分词,ES 在索引中匹配文档,按销量、评分等权重排序,返回结果。
2. 日志分析(ELK Stack)
- 场景:收集服务器日志,快速分析错误数、慢请求等。
- 架构:Logstash 收集日志 → Elasticsearch 存储 & 索引 → Kibana 可视化。
- 查询示例:
“近1小时 status=500 的请求量”,ES 聚合分析可秒回。
3. 内容平台搜索(知乎、Github)
- 搜索问题、文章、代码等,需要高亮显示匹配词,并根据热度、时间排序。
五、在 Java 中使用 Elasticsearch
假设我们做一个商品搜索功能,技术栈:Spring Boot + Spring Data Elasticsearch。
1. 添加依赖(Maven)
1 | <dependency> |
2. 配置文件(application.yml)
1 | spring: |
3. 定义文档实体(对应索引中的一条数据)
1 | import org.springframework.data.annotation.Id; |
4. 定义 Repository(类似 MyBatis 的 Mapper)
Spring Data 会根据方法名自动生成查询实现。
1 | import org.springframework.data.elasticsearch.repository.ElasticsearchRepository; |
5. 在 Service 中使用
1 |
|
6. 测试接口
1 |
|
请求 GET /search?name=手机,即可返回名称中含“手机”的商品列表。
六、总结
Elasticsearch 把搜索这个复杂问题封装成简单的 JSON over HTTP 服务,和 Spring Data 结合后,用起来就像操作数据库一样方便。但背后的本质依然是强大的倒排索引和分布式架构,让它在海量数据下依然能保持毫秒级响应。
Netty WebSocket
群聊功能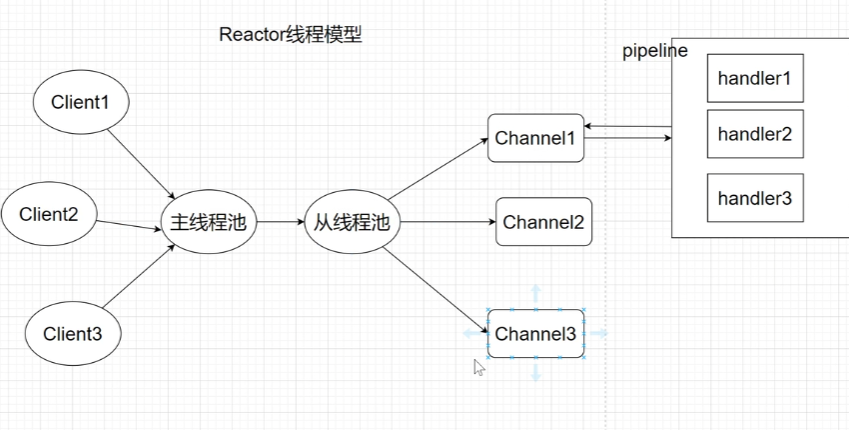
这是后端逐字/逐段推送消息 → 前端像打字机一样慢慢显示的经典方案,广泛用于 AI 对话、客服机器人、实时流输出。
一、核心原理(一定要看懂)
1. 为什么要用 WebSocket + 流式?
- HTTP 只能请求一次、响应一次,无法中途持续推送消息
- WebSocket 是长连接、全双工,后端可以随时主动向前端发数据
- 打字机效果 = 后端分段发送消息 + 前端逐段追加显示
二、技术栈
- Netty 4.1.100.Final
- WebSocket 协议
- Java 后端
- HTML + JS 前端(极简)
三、完整代码实现
1. Maven 依赖
1 | <dependencies> |
四、后端 Netty 代码(3 个类搞定)
① 主启动类 NettyWebSocketServer
1 | import io.netty.bootstrap.ServerBootstrap; |
② 自定义消息处理器(核心:流式发送)
1 | import io.netty.channel.ChannelHandlerContext; |
五、前端 HTML(直接打开即可)
1 |
|
六、运行效果
- 启动后端 Netty
- 打开前端 HTML
- 页面会像打字一样,一个字一个字慢慢显示出来
这就是标准打字机流式回复。
七、进阶优化(生产可用)
1. 逐段发送(不逐字,减少请求量)
1 | String[] parts = {"大家好,", "我是 Netty 流式回复。", "我会分段输出!"}; |
2. AI 场景:从模型流式读取输出
1 | // 伪代码 |
3. 心跳保活
Netty 加入 IdleStateHandler 防止连接断开。
4. 多客户端管理
用 ConcurrentHashMap 保存所有连接,实现群发/单播。
八、总结(超清晰)
- WebSocket 让后端能主动推送消息
- 分批发送 实现流式输出
- 前端追加文本 实现打字机效果
- Netty 高性能、高并发,适合 AI/机器人/实时消息
一、先搞懂:Netty到底解决了什么问题?
Java本身提供了**BIO(阻塞IO)和NIO(非阻塞IO)**两种网络编程方式:
- BIO:每个连接一个线程,1万连接需要1万线程,线程切换开销巨大,内存直接爆掉
- 原生NIO:API极其复杂,bug极多,需要处理半包粘包、断线重连等各种底层问题
Netty = 对Java NIO的完美封装 + 高性能架构设计 + 开箱即用的组件
它让你不用关心底层网络细节,只需要写业务逻辑,就能写出支持百万级长连接的网络应用。
二、逐句解释你的技术描述
1. “高性能、异步事件驱动的网络应用框架”
通俗解释
- 异步:你发一个请求,不用傻等结果,继续干别的事;结果出来了Netty会主动通知你
- 事件驱动:程序的所有行为都由”事件”触发——连接建立、数据到达、数据发送完成、连接断开
- 类比:就像外卖平台
- 你下单(发请求)不用在餐厅门口等
- 外卖做好了(事件发生),骑手会主动送到你家(通知你)
- 平台同时处理成千上万的订单,只需要少量骑手(线程)
代码体现
1 | // 异步绑定端口,不会阻塞主线程 |
2. “基于Java NIO构建”
通俗解释
Java NIO的核心是**”一个线程处理多个连接”**,Netty就是基于这个原理,但解决了原生NIO的所有痛点:
- 封装了复杂的Selector API
- 自动处理半包粘包问题
- 提供了统一的异常处理机制
- 优化了内存管理,减少GC
3. “采用Reactor线程模型”
通俗解释
Reactor是Netty高性能的灵魂,它是一种”事件分发模式”:
- 有一个或多个”反应器”(EventLoop)
- 所有连接都注册到反应器上
- 反应器不断轮询,哪个连接有事件发生,就分配线程去处理
Netty的主从Reactor模型(生产标准)
- BossGroup(主Reactor):1个线程,只负责一件事——接收客户端的连接请求
- WorkerGroup(从Reactor):默认CPU核心数*2个线程,负责处理所有连接的读写事件
类比
- BossGroup = 餐厅门口的迎宾,只负责把客人领到座位
- WorkerGroup = 服务员,每个服务员负责多桌客人,客人有需求(点菜、加水)就去处理
代码体现
1 | // 主Reactor:1个线程,负责接收连接 |
4. “通过少量EventLoop线程轮询I/O事件”
通俗解释
- EventLoop:就是一个”无限循环的线程”
- 每个EventLoop内部有一个
Selector(选择器) - 它不断轮询注册在自己身上的所有Channel(连接)
- 当某个Channel有读/写事件发生时,EventLoop就会调用对应的处理器处理
核心优势
- 少量线程处理大量连接:一个EventLoop可以处理上千甚至上万个连接
- 无锁设计:一个Channel的所有事件都由同一个EventLoop处理,避免了线程安全问题
- 减少上下文切换:线程数量少,操作系统切换线程的开销大大降低
数据对比
| 模型 | 10万连接需要的线程数 | 内存占用 | 并发能力 |
|---|---|---|---|
| BIO | 10万 | ~10GB | 差 |
| Netty Reactor | 16(8核CPU) | ~100MB | 极强 |
5. “在处理大量长连接场景下具有显著的性能优势”
通俗解释
什么是长连接?连接建立后一直保持,双方可以随时互相发送数据,比如:
- AI对话(需要持续推送生成的文字)
- 即时通讯(微信、QQ)
- 实时监控
- 游戏
Netty就是为大量长连接场景量身打造的,这也是为什么几乎所有AI大模型的后端都用Netty做WebSocket服务器。
6. “通过ChannelPipeline灵活编排处理器”
通俗解释
- Channel:代表一个客户端和服务器之间的连接
- ChannelPipeline:每个Channel都有一个”处理流水线”
- ChannelHandler:流水线中的”工人”,每个工人只做一件事
数据在Pipeline中单向流动:
- 入站(客户端→服务器):从Pipeline头部流向尾部
- 出站(服务器→客户端):从Pipeline尾部流向头部
核心优势
- 职责单一:每个Handler只负责一个功能,比如HTTP编解码、WebSocket协议处理
- 灵活组合:可以根据需要添加、删除、替换Handler
- 易于扩展:新增功能只需要添加一个新的Handler
代码体现(AI流式响应的Pipeline)
1 | .childHandler(new ChannelInitializer<SocketChannel>() { |
7. “实现高并发AI流式响应的实时推送”
通俗解释
AI大模型生成回答是流式的——它不是一下子生成完整的回答,而是一个字一个字地生成。这就要求:
- 服务器和前端保持长连接
- 服务器能随时主动向前端推送数据
- 能同时支持大量用户同时进行对话
Netty的所有特性正好完美满足这些需求:
- 长连接:WebSocket协议支持
- 主动推送:全双工通信
- 高并发:Reactor模型支持百万级连接
- 实时性:异步事件驱动,延迟极低
三、完整实例:Netty实现AI流式响应(打字机效果)
我会写一个生产级简化版的AI对话服务器,把上面所有概念都融入进去,你可以直接运行测试。
1. 项目结构
1 | src/ |
2. 主启动类(Reactor模型+Pipeline编排)
1 | import io.netty.bootstrap.ServerBootstrap; |
3. AI模型模拟器(模拟大模型流式生成)
1 | import java.util.concurrent.TimeUnit; |
4. 业务处理器(核心:流式推送)
1 | import io.netty.channel.ChannelHandlerContext; |
5. 前端页面(打字机效果展示)
1 |
|
四、运行效果与关键说明
运行步骤
- 启动
NettyAIWebSocketServer.java - 用浏览器打开
index.html - 输入问题”什么是Netty?”,点击发送
- 你会看到AI像打字一样,一个字一个字地显示回答
关键技术点说明
为什么要用业务线程池?
- Netty的EventLoop线程是IO线程,专门用来处理网络事件
- 如果在EventLoop线程中执行耗时操作(比如调用AI模型),会阻塞所有注册在这个EventLoop上的连接
- 所以必须把耗时的业务逻辑提交到独立的业务线程池处理
为什么用
writeAndFlush而不是write?write只是把数据写到缓冲区,不会发送到网络writeAndFlush=write+flush,会立即把数据发送到网络- 流式响应需要实时推送,所以必须用
writeAndFlush
如何支持高并发?
- BossGroup只有1个线程,就能接收每秒上万的连接请求
- WorkerGroup默认是CPU核心数*2个线程,每个线程处理上千个连接
- 业务线程池可以根据服务器配置调整大小,平衡并发量和响应时间
五、总结
Netty之所以成为AI流式响应的首选技术,是因为它完美解决了这个场景的核心需求:
- 长连接支持:WebSocket协议原生支持
- 高并发能力:Reactor模型用少量线程处理百万级连接
- 实时推送:全双工通信,服务器可以随时主动发送数据
- 灵活扩展:ChannelPipeline可以轻松添加各种功能(如权限验证、日志、限流)
如果你需要,我可以给你补充生产级AI服务器的完整代码,包括:
- 心跳保活机制(防止连接断开)
- 断线重连逻辑
- 多用户会话管理
- 限流与熔断
- 与真实大模型API(如OpenAI、通义千问)的集成
Redis
缓存
Redis(Remote Dictionary Server,远程字典服务器)是一个开源、高性能、基于内存的键值对(Key-Value)数据库,也被称为”数据结构服务器”。它是目前全球最流行的NoSQL数据库之一,广泛应用于缓存、分布式锁、计数器、消息队列等场景,是现代高并发后端系统的标配组件。
一、核心定位与本质
- 本质:一个运行在内存中的字典(哈希表),通过键快速查找值
- 核心优势:速度极快(基于内存读写,QPS可达10万+/秒)
- 与传统数据库的区别:
- 关系型数据库(MySQL):基于磁盘、结构化、支持SQL、强一致性
- Redis:基于内存、非结构化、键值对、最终一致性、速度快100-1000倍
- 官方定位:不仅是缓存,更是一个多功能的数据结构存储系统
2. 持久化机制(解决内存数据丢失问题)
Redis虽然基于内存,但提供了两种持久化方式,保证数据不会因服务器重启而丢失:
3. 高可用与分布式
- 主从复制:一主多从架构,主节点写,从节点读,实现读写分离
- 哨兵模式(Sentinel):监控主从节点,自动故障转移,保证高可用
- 集群模式(Cluster):Redis 3.0+推出,支持数据分片,横向扩展存储容量和并发能力
4. 其他重要特性
- 过期策略:支持为键设置过期时间,自动删除过期数据
- 内存淘汰机制:当内存达到上限时,按照指定策略删除数据(如LRU、LFU)
- 原子操作:所有Redis命令都是原子性的,无需担心并发问题
- 事务支持:支持简单的事务(MULTI/EXEC),保证一组命令的原子执行
- 发布订阅(Pub/Sub):实现消息的发布和订阅功能
- Lua脚本:支持执行Lua脚本,实现复杂的原子操作
三、典型应用场景
Redis的应用场景非常广泛,几乎覆盖了所有高并发系统的核心需求:
1. 数据缓存(最常用)
- 缓存热点数据(商品详情、首页内容、用户信息)
- 减轻数据库压力,将数据库的读请求转移到Redis
- 示例:用户访问商品详情页时,先查Redis,没有再查MySQL并写入Redis
2. 分布式锁
- 解决分布式系统中的并发问题
- 使用
SET key value NX EX命令实现原子加锁 - 示例:防止订单重复提交、库存超卖
3. 计数器
- 统计点赞数、评论数、浏览量、下载量
- 使用
INCR命令实现原子递增 - 示例:文章点赞数实时更新
4. 排行榜
- 使用Sorted Set实现,按分数排序
- 示例:游戏排行榜、商品销量榜、热搜榜
5. 消息队列
- 使用List或Stream实现简单的消息队列
- 示例:异步任务处理、日志收集、订单处理
6. 会话存储
- 存储用户登录Session、Token
- 替代传统的服务器Session,支持分布式部署
7. 限流
- 使用计数器或令牌桶算法实现接口限流
- 示例:防止恶意请求、保护系统稳定性
8. 地理位置服务
- 使用Geospatial数据结构存储地理位置信息
- 示例:附近的人、距离计算、位置排序
四、工作原理:为什么Redis这么快?
Redis的高性能源于以下几个关键设计:
- 基于内存:所有数据都存储在内存中,避免了磁盘IO的瓶颈
- 单线程模型:命令执行采用单线程,避免了上下文切换和锁竞争的开销
- 注意:Redis的单线程仅指命令执行是单线程,持久化、集群同步等功能有单独的线程
- IO多路复用:使用epoll/kqueue等IO多路复用技术,同时处理大量并发连接
- 高效的数据结构:内置了经过优化的数据结构,如跳表、哈希表等
- 简洁的协议:使用RESP(Redis Serialization Protocol)协议,简单高效
五、优缺点
优点
- ✅ 速度极快:基于内存,读写性能远超传统数据库
- ✅ 数据结构丰富:支持8种核心数据结构,满足各种业务需求
- ✅ 高可用:支持主从复制、哨兵模式和集群模式
- ✅ 持久化:提供RDB和AOF两种持久化方式
- ✅ 原子操作:所有命令都是原子性的,并发安全
- ✅ 生态完善:支持几乎所有编程语言的客户端,社区活跃
缺点
- ❌ 内存成本高:数据存储在内存中,存储大量数据的成本较高
- ❌ 不适合存储冷数据:冷数据占用内存资源,性价比低
- ❌ 单线程阻塞:执行耗时较长的命令(如KEYS *)会阻塞整个服务器
- ❌ 不支持复杂查询:没有SQL,不适合复杂的关联查询
六、适用与不适用场景
适用场景
- 高并发的读多写少场景
- 需要快速响应的实时系统
- 缓存热点数据
- 分布式系统中的协调(分布式锁、计数器)
- 简单的消息队列
不适用场景
- 作为主要数据库存储大量历史数据
- 需要复杂事务和关联查询的场景
- 存储超大文件或二进制数据
- 对数据一致性要求极高的金融核心系统




