第一章 Collections的 sort方法 1.2、Collections 工具类与 sort 方法概述 java.util.Collections是 Java 集合框架中的一个 ,它提供了一系列用于操作集合的静态方法,比如排序、查找、替换等。其中,sort方法专门用于对List集合进行排序,它有两种重载形式:
1 2 3 4 1. public static <T extends Comparable <? super T>> void sort (List<T> list) :该方法适用于元素实现了Comparable接口,具备自然排序能力的List集合。2. public static <T> void sort (List<T> list, Comparator<? super T> c) :当元素没有自然排序能力时,通过传入一个自定义的Comparator比较器对象,来指定排序规则。
1.3、自然排序(实现 Comparable 接口) 原理 并实现该接口的compareTo方法 。compareTo方法用于定义元素之间的自然顺序,它返回一个整数值:
如果返回值小于 0,表示当前对象小于参数对象;
如果返回值等于 0,表示当前对象等于参数对象;
如果返回值大于 0,表示当前对象大于参数对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class MyArrays { private MyArrays () { } public static void sort (Object[] arr) { if (arr == null ){ return ; } for (int i = 0 ; i < arr.length-1 ; i++) { for (int j = 0 ; j < arr.length - i - 1 ; j++) { Comparable c1 = (Comparable) arr[j]; Comparable c2 = (Comparable) arr[j+1 ]; if (c1.compareTo(c2) > 0 ){ arr[j] = c2; arr[j+1 ] = c1; } } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public class Dog implements Comparable <Dog>{ private String name; private int age; @Override public String toString () { return "Dog{" + "name='" + name + '\'' + ", age=" + age + '}' ; } ... @Override public int compareTo (Dog o) { return o.age - this .age; } } public class TestDog { public static void main (String[] args) { Dog[] arr = new Dog [3 ]; arr[0 ] = new Dog ("旺财" ,5 ); arr[1 ] = new Dog ("小黑" ,3 ); arr[2 ] = new Dog ("大黄" ,6 ); System.out.println(Arrays.toString(arr)); Arrays.sort(arr); System.out.println(Arrays.toString(arr)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 package com.shihanshuo.SetTest;import java.util.Objects;public class Book implements Comparable <Book> { private String name; private double price; public String getName () { return name; } public void setName (String name) { this .name = name; } public double getPrice () { return price; } public void setPrice (double price) { this .price = price; } @Override public String toString () { return "Book{" + "name='" + name + '\'' + ", price=" + price + '}' ; } public Book (String name, double price) { this .name = name; this .price = price; } @Override public int compareTo (Book o) { return Double.compare(this .price, o.price); } @Override public boolean equals (Object o) { System.out.println("equals.............." ); if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; Book book = (Book) o; if (Double.compare(price, book.price) != 0 ) return false ; return Objects.equals(name, book.name); } @Override public int hashCode () { System.out.println("hashCode.............." ); int result; long temp; result = name != null ? name.hashCode() : 0 ; temp = Double.doubleToLongBits(price); result = 31 * result + (int ) (temp ^ (temp >>> 32 )); return result; } } public class TestBook { public static void main (String[] args) { Book[] books = new Book [3 ]; books[0 ] = new Book ("三国演义" ,19.88 ); books[1 ] = new Book ("水浒传" ,19.8 ); books[2 ] = new Book ("西游记" ,19.83 ); MyArrays.sort(books); System.out.println(Arrays.toString(books)); } }
1.4、定制排序(使用 Comparator 接口)【重点】 原理
当被排序的元素所属的类没有实现Comparable接口 ,或者我们希望按照不同于自然排序的规则进行排序时,可以使用Comparator接口来自定义排序规则。
Comparator接口中有一个compare方法,它同样返回一个整数值,含义与Comparable接口中的compareTo方法类似,Collections.sort方法会根据这个返回值对元素进行排序。
代码思路
可以通过匿名内部类实现Comparator接口的compare方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class MyTest06 { public static void main (String[] args) { String[] arr = {"bbb" ,"a" ,"dd" ,"aa" ,"dd" ,"ccc" ,"ff" ,"aa" }; Comparator<String> bjq = new Comparator <String>(){ public int compare (String o1, String o2) { int i = o2.length() - o1.length(); return i == 0 ? o1.compareTo(o2) :i; } }; Arrays.sort(arr,bjq); System.out.println(Arrays.toString(arr)); } }
代码写法
排序方式
结果
o2 - o1降序 大的 / 长的 / 晚的 排前面
o1 - o2升序 小的 / 短的 / 早的 排前面
o1.compareTo(o2)升序 字典序 a-z
o2.compareTo(o1)降序 字典序 z-a
也可以使用 Java 8 的 Lambda 表达式简化代码实现。
注意事项 Comparable接口与Comparator接口的方法参数是不一样的 ,Comparable接口的compareTo方法只有一个参数,而Comparator接口的compare方法有两个参数 ,注意区分每个参数的含义及返回值的意义;
总结
Java中Collections工具类的sort方法是对List集合进行排序的重要工具。
使用该方法时,要确保被排序的元素拥有自然排序能力(实现Comparable接口),或者通过编写Comparator比较器对象 来定制排序规则。
第二章 TreeSet集合
对比维度
自然排序(Comparable)
比较器排序(Comparator)
实现方式
元素类自身实现 接口
外部传入 Comparator 对象
代码侵入性
需要修改元素类代码
无需修改元素类代码
灵活性
只能定义一种固定排序规则
可动态定义多种排序规则
典型场景
元素类的默认排序(如 Integer)
需自定义排序或元素类未实现接口
TreeSet 需要比较零
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.itheima.p6_treeset;import java.util.Comparator;import java.util.TreeSet;public class MyTest08_2 { public static void main (String[] args) { TreeSet<Book> set = new TreeSet <>( new Comparator <Book>() { @Override public int compare (Book o1, Book o2) { int i = Double.compare(o1.getPrice(), o2.getPrice()); return i == 0 ? o1.getName().compareTo(o2.getName()):i; } } ); set.add(new Book ("水浒传" ,19.8 )); set.add(new Book ("红楼梦" ,19.8 )); set.add(new Book ("红楼梦" ,19.8 )); set.add(new Book ("红楼梦" ,19.8 )); set.add(new Book ("三国演示" ,29.8 )); System.out.println(set); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class MyTest08 { public static void main (String[] args) { TreeSet<Integer> set = new TreeSet <>(); set.add(2 ); set.add(6 ); set.add(15 ); set.add(18 ); set.add(19 ); System.out.println(set); TreeSet<Pai> set2 = new TreeSet <>(new Comparator <Pai>() { @Override public int compare (Pai o1, Pai o2) { return o1.getZhi() - o2.getZhi(); } }); set2.add(new Pai ("♠" ,"A" ,7 )); set2.add(new Pai ("♠" ,"2" ,3 )); System.out.println(set2); } }
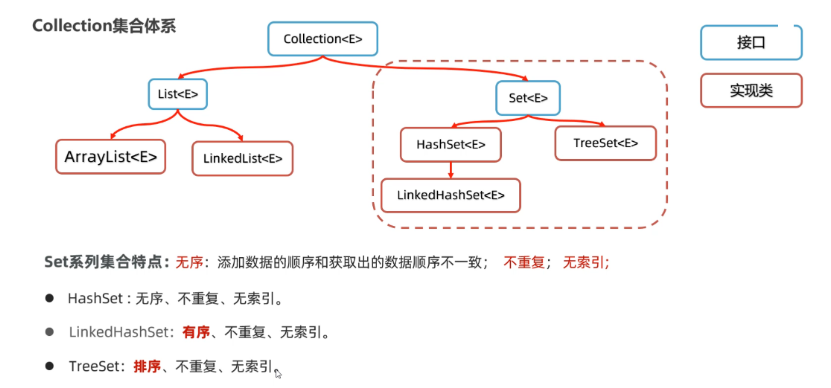
第三章 Set集合 3.1 Set特点 Set集合是属于Collection体系下的另一个分支,它的特点如下图所示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 java.util.Collection<T>接口: 单列集合的根接口 里面定义的方法,子接口/实现类 都有 常用子接口: java.util.List<T>接口: 特点: 1. 有序: 保证存入和取出元素的顺序是一致的 2. 有索引: 可以通过索引的方式获取元素 3. 可重复: 可以存储相同的内容 java.util.Set<T>接口: 特点: 1. 无索引: 不可以通过索引的方式获取元素 2. 不可重复 元素唯一,研究如何保证元素唯一的,依赖hashCode方法和equals方法 3. 注意: 不能说Set集合是有序/无序的,因为到底有序/无序, 要看实现类 HashSet就是无序的,LinkedHashSet就是有序的 注意: Set接口中的方法和Collection中的方法一样 Collection中的方法,已经学习过了
3.2 Set基本使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Demo03Set { public static void main (String[] args) { Set<Integer> set = new HashSet <>(); set.add(100 ); set.add(100 ); set.add(10000 ); set.add(10000 ); set.add(200 ); set.add(200 ); System.out.println(set); Set<String> set2 = new LinkedHashSet <>(); set2.add("zz" ); set2.add("hhh" ); set2.add("bbbb" ); set2.add("aaaaa" ); set2.add("dddddd" ); set2.add("zz" ); System.out.println(set2); } }
3.3 hashCode方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 java.lang.Object类,成员方法: public native int hashCode () : 返回该对象的哈希码值,就是一个int 数字 该方法是本地方法,根据系统资源计算一个int 数字,叫做哈希值 支持此方法是为了提高哈希表的性能。 注意: 1. 同一对象,多次调用hashCode方法,要保证获取到的哈希值是相同的 2. Object类中的hashCode方法,根据系统资源计算一个哈希值(int 数字),所以只要new 创建对象,获取到的哈希值就是不同的 3. 如果自己定义了的类,没有覆盖重写Object类中的hashCode方法,根据系统资源计算一个哈希值(int 数字),所以只要new 创建对象,获取到的哈希值就是不同的 4. 根据对String的测试,发现String类覆盖重写了Object类中的hashCode方法,根据字符串内容按照一定算法(存在漏洞)获取哈希值 假设: String根据每个字符的ASCII码值,简单相加获取哈希值 "abc" 的 哈希值 97 + 98 + 99 = 294 "cab" 的 哈希值 99 + 97 + 98 = 294 总结: 1. 哈希值不同,能否说明内容一定不同? 肯定的,必须的 2. 哈希值相同,能否说明内容一定相同? 不能的 继续调用equals方法 返回false : 内容不相同 返回true : 内容相同 改口: 以前调用toString方法,说返回的是对象的地址值 但本质是对象的哈希值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Demo04HashCode { public static void main (String[] args) { Object obj1 = new Object (); int h1 = obj1.hashCode(); int h2 = obj1.hashCode(); System.out.println(h1); System.out.println(h2); Object obj2 = new Object (); int h3 = obj2.hashCode(); System.out.println(h3); System.out.println(obj1.toString()); System.out.println(obj2.toString()); char [] chs = {'a' ,'b' ,'c' }; String s1 = new String (chs); String s2 = new String (chs); System.out.println(s1.hashCode()); System.out.println(s2.hashCode()); System.out.println("重地" .hashCode()); System.out.println("通话" .hashCode()); } }
3.4 String的哈希值算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 String的哈希值算法 String内部是字符数组 String s = "abc" ; String内部的字符数组 char [] value = {'a' ,'b' ,'c' } String 的hashCode方法: public int hashCode () { int h = hash; if (h == 0 && value.length > 0 ) { char val[] = value; for (int i = 0 ; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; } h = 31 * 0 + 97 = 97 h = 31 * 97 + 98 = 3105 h = 31 * 3105 + 99 = 96354 public class Demo05StringHashCode { public static void main (String[] args) { String s = "abc" ; System.out.println(s.hashCode()); } }
3.5 哈希表的结构
3.6 HashSet存储元素和去重原理 前面我们学习了HashSet存储元素的原理,依赖于两个方法:
要想保证在HashSet集合中没有重复元素,我们需要重写元素类的hashCode和equals方法。
一个是hashCode方法用来确定在底层数组中存储的位置,
另一个是用equals方法判断新添加的元素是否和集合中已有的元素相同 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Testqownfoq { public static void main (String[] args) { HashSet<String> set = new HashSet <>(); String s = "ab" ; String s1 = "abc" ; String s2 = "c" ; String s3 = s+s2; String s4 = new String ("abc" ); String s5 = "ab" +"c" ; set.add(s1); set.add(s3); set.add(s4); set.add(s5); System.out.println(s1.hashCode()); System.out.println(s3.hashCode()); System.out.println(s4.hashCode()); System.out.println(s5.hashCode()); System.out.println(set); } }
比如以下面的Student类为例,假设把Student类的对象作为HashSet集合的元素,想要让学生的姓名和年龄相同,就认为元素重复。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class Student { private String name; private int age; @Override public String toString () { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}' ; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } public Student (String name, int age) { this .name = name; this .age = age; } @Override public boolean equals (Object o) { System.out.println("equals执行了......" ); if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; Student student = (Student) o; if (age != student.age) return false ; return Objects.equals(name, student.name); } @Override public int hashCode () { int result = name != null ? name.hashCode() : 0 ; result = 31 * result + age; return result; } }
接着,写一个测试类,往HashSet集合中存储Student对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class MyHashSet3 { public static void main (String[] args) { HashSet<Student> set = new HashSet <>(); Student s1 = new Student ("张三" ,18 ); Student s2 = new Student ("张三" ,18 ); Student s3 = new Student ("李四" ,19 ); Student s4 = new Student ("王五" ,19 ); Student s5 = new Student ("张三" ,18 ); System.out.println(s1.hashCode()); System.out.println(s2.hashCode()); System.out.println(s3.hashCode()); System.out.println(s4.hashCode()); System.out.println(s5.hashCode()); set.add(s1); set.add(s2); set.add(s3); set.add(s4); set.add(s5); System.out.println(set); } }
打印结果如下,我们发现存了两个蜘蛛精,当时实际打印出来只有一个,而且是无序的。
HashSet集合底层是基于哈希表实现的,哈希表根据JDK版本的不同,也是有点区别的
JDK8以前:哈希表 = 数组+链表
JDK8以后:哈希表 = 数组+链表+红黑树
超过16 x 0.75 = 12 扩容
我们发现往HashSet集合中存储元素时,底层调用了元素的两个方法:
一个是hashCode方法获取元素的hashCode值(哈希值);
另一个是调用了元素的equals方法,用来比较新添加的元素和集合中已有的元素是否相同 。
只有新添加元素的hashCode值和集合中以后元素的hashCode值相同、新添加的元素调用equals方法和集合中已有元素比较结果为true, 才认为元素重复。
如果hashCode值相同,equals比较不同,则以链表的形式连接在数组的同一个索引为位置(如上图所示)
在JDK8开始后,为了提高性能,当链表的长度超过8时,就会把链表转换为红黑树 ,如下图所示:
3.7 LinkedHashSet底层原理 LinkedHashSet它底层采用的是也是哈希表结构,只不过额外新增了一个双向链表来维护元素的存取顺序。如下下图所示:
每次添加元素,就和上一个元素用双向链表连接一下 。第一个添加的元素是双向链表的头节点,最后一个添加的元素是双向链表的尾节点。
把上个案例中的集合改成LinkedList集合,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Test { public static void main (String[] args) { Set<Student> students = new LinkedHashSet <>(); Student s1 = new Student ("至尊宝" ,20 , 169.6 ); Student s2 = new Student ("蜘蛛精" ,23 , 169.6 ); Student s3 = new Student ("蜘蛛精" ,23 , 169.6 ); Student s4 = new Student ("牛魔王" ,48 , 169.6 ); students.add(s1); students.add(s2); students.add(s3); students.add(s4); for (Student s : students){ System.out.println(s); } } }
打印结果如下
1 2 3 Student{name='至尊宝' , age=20 , height=169.6 } Student{name='蜘蛛精' , age=23 , height=169.6 } Student{name='牛魔王' , age=48 , height=169.6 }
3.11 LinkedHashSet集合的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class Demo04LinkedHashSetStudent { public static void main (String[] args) { LinkedHashSet<Student> set = new LinkedHashSet <>(); set.add(new Student ("zs" ,18 )); set.add(new Student ("zs" ,18 )); set.add(new Student ("ls" ,38 )); set.add(new Student ("ls" ,38 )); set.add(new Student ("ww" ,28 )); set.add(new Student ("ww" ,28 )); System.out.println(set); } }
第四章 Arrays
扩展-集合的交集,并集,差集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Test09 { public static void main (String[] args) { ArrayList<Integer> list1 = new ArrayList <>(); ArrayList<Integer> list2 = new ArrayList <>(); Collections.addAll(list1,1 ,2 ,5 ,8 ,3 ,6 ,9 ,1 ,5 ); Collections.addAll(list2,2 ,4 ,6 ,8 ); ArrayList<Integer> clone = (ArrayList<Integer>) list1.clone(); clone.addAll(list2); System.out.println(list1); System.out.println(list2); System.out.println(clone); ArrayList<Integer> clone2 = (ArrayList<Integer>) list1.clone(); boolean b = clone2.retainAll(list2); System.out.println(clone2); ArrayList<Integer> clone3 = (ArrayList<Integer>) list1.clone(); boolean b1 = clone3.removeAll(list2); System.out.println(clone3); System.out.println(new HashSet <Integer>(clone3)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Test09_2 { public static void main (String[] args) { ArrayList<Book> list = new ArrayList <>(); list.add(new Book ("西游记" ,19.7 )); ArrayList<Book> clone = (ArrayList<Book>) list.clone(); clone.get(0 ).setName("红楼梦" ); System.out.println(list); System.out.println(clone); } }
案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 import java.time.LocalDateTime;import java.util.Comparator;import java.util.TreeSet;public class Manager { private Comparator<TuanYuan> bj = new Comparator <TuanYuan>() { @Override public int compare (TuanYuan o1, TuanYuan o2) { int i = o1.getJoinDate().compareTo(o2.getJoinDate()); return i == 0 ? o1.getName().compareTo(o2.getName()) : i; } }; private TreeSet<TuanYuan> engs = new TreeSet <>(bj); private TreeSet<TuanYuan> maths = new TreeSet <>(bj); public void showMenu () { System.out.println("----------------欢迎进入社团系统---------------" ); while (true ) { System.out.println("请选择要执行的功能:" ); System.out.println("1: 入团" ); System.out.println("2: 退团" ); System.out.println("3: 查看指定的团的团员信息" ); System.out.println("4: 查看所有社团的全部团员信息" ); System.out.println("5: 查看社团的死忠粉" ); System.out.println("6: 查看卷王" ); System.out.println("0: 退出系统" ); int i = MyScannerUtils_v2.getInt(); switch (i) { case 1 -> add(); case 2 -> del(); case 3 -> showTy(); case 4 -> showAll(); case 5 -> showSz(); case 6 -> showJw(); case 0 -> { System.out.println("拜拜" ); return ; } default -> System.out.println("输入有误,请重新输入!" ); } } } private void showJw () { } private void showSz () { TreeSet<TuanYuan> clone = (TreeSet<TuanYuan>) engs.clone(); TreeSet<TuanYuan> clone2 = (TreeSet<TuanYuan>) maths.clone(); boolean b = clone.removeAll(clone2); System.out.println("英语团的死忠粉是:" +clone); clone2.removeAll(engs); System.out.println("数学团的死忠粉是:" +clone2); } private void showAll () { TreeSet<TuanYuan> clone = (TreeSet<TuanYuan>) engs.clone(); TreeSet<TuanYuan> clone2 = (TreeSet<TuanYuan>) maths.clone(); clone.addAll(clone2); for (TuanYuan yuan : clone) { System.out.println(yuan); } } private void showTy () { System.out.println("请选择要查看的团:" ); System.out.println("1: 英语社团" ); System.out.println("2: 数学社团" ); int i = MyScannerUtils_v2.getInt(); switch (i){ case 1 -> { for (TuanYuan eng : engs) { System.out.println(eng); } } case 2 -> System.out.println(maths); default -> System.out.println("有误" ); } } private void del () { System.out.println("请输入您的姓名:" ); String name = MyScannerUtils_v2.getString(); TuanYuan tuanYuan = findTyByName(name); if (tuanYuan == null ){ System.out.println("您不在任何社团中..." ); }else { engs.remove(tuanYuan); maths.remove(tuanYuan); System.out.println("退团成功!" ); } } public TuanYuan findTyByName (String name) { for (TuanYuan eng : engs) { if (eng.getName().equals(name)){ return eng; } } for (TuanYuan math : maths) { if (math.getName().equals(name)){ return math; } } return null ; } private void add () { System.out.println("请输入您的姓名:" ); String name = MyScannerUtils_v2.getString(); System.out.println("请选择要入的团:" ); System.out.println("1: 英语社团" ); System.out.println("2: 数学社团" ); int i = MyScannerUtils_v2.getInt(); if (i == 1 ) { boolean b = engs.add(new TuanYuan (name, LocalDateTime.now())); if (b) { System.out.println("英语社团欢迎您:" + name); } else { System.out.println("亲,您已经在社团了,别瞎搞!" ); } } else if (i == 2 ) { boolean b = maths.add(new TuanYuan (name, LocalDateTime.now())); if (b) { System.out.println("数学社团欢迎您:" + name); } else { System.out.println("亲,您已经在社团了,别瞎搞!" ); } } else { System.out.println("输入有误" ); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import java.util.Scanner;public class MyScannerUtils_v2 { private static Scanner sc = new Scanner (System.in); private MyScannerUtils_v2 () { } public static int getInt () { while (true ){ try { String s = sc.nextLine(); return Integer.parseInt(s); } catch (Exception e) { System.out.println("请务必输入整数....." ); } } } public static double getDouble () { while (true ){ try { String s = sc.nextLine(); return Double.parseDouble(s); } catch (Exception e) { System.out.println("请务必输入小数....." ); } } } public static String getString () { return sc.nextLine(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import java.time.LocalDateTime;import java.util.Date;public class TuanYuan { private String name; private LocalDateTime joinDate; @Override public String toString () { return "团员:" +name+",入团时间是:" +joinDate; } public String getName () { return name; } public void setName (String name) { this .name = name; } public LocalDateTime getJoinDate () { return joinDate; } public void setJoinDate (LocalDateTime joinDate) { this .joinDate = joinDate; } public TuanYuan (String name, LocalDateTime joinDate) { this .name = name; this .joinDate = joinDate; } }
1 2 3 4 5 6 public class Test { public static void main (String[] args) { new Manager ().showMenu(); } }